Часто ли вы сталкиваетесь с проблемой выбора фильма на вечер? И как эту проблему вы решаете сегодня? Подборки на тематических порталах, советы друзей, оценки критиков. К сожалению, эти инструменты обладают одной существенной погрешностью — они исключают персонализацию.
Вторая проблема лежит в поведенческой номенклатуре нашего мозга и чистой математике: чем больше выбор — тем сложнее выбирать. Число релизов ежегодно растет, а развитие платформ стимулирует еще и горизонтальный рост продукции. Масштаб проблемы растет нелинейно, ведь с каждым циклом изобилие порождает существенно большее изобилие.
К счастью, эти проблемы вполне решаемы, ведь большие корпорации уже сегодня знают о нас куда больше, чем мы сами. Или узнают рано или поздно.
Основные принципы рекомендательных систем
Рекомендательные системы в своей привычной форме существуют порядка 30 лет, однако архитектурно не претерпели больших перемен. Можно выделить две основные методики, применяемые в производстве: коллаборативная фильтрация (User-Based Filtering) и фильтрация по содержанию (Content-Based Filtering). Попробуем на пальцах разобраться что есть что.
Предсказываем на примере других пользователей
Коллаборативная фильтрация строит прогноз на основе пользователей со схожими признаками, интересами или поведением, группируя их в кластеры. Выявить степень «схожести» можно с помощью формулы расчета корреляции (например, Пирсона):
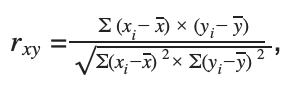
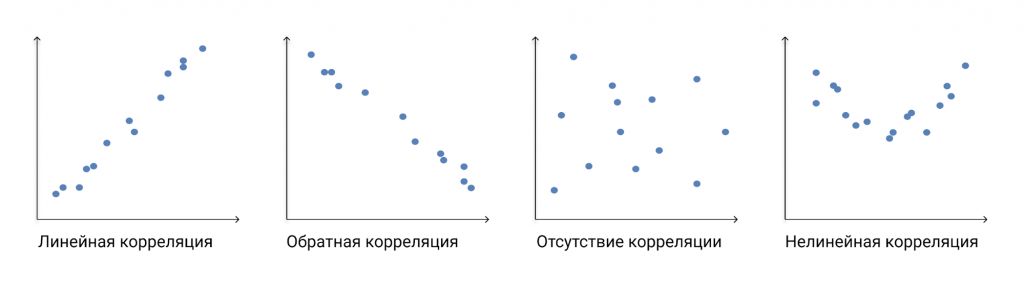
где xi— значения переменной X (исходный пользователь), yi— значения переменной Y (другой пользователь), x — среднее арифметическое для переменной X, y — среднее арифметическое для переменной Y. Визуально это выглядит примерно так:
Приведем живой пример для наглядности. У нас имеется пользователь A, которому мы должны либо не должны порекомендовать к просмотру фильм «Авиатор».

Следующим шагом просканируем базу в поисках схожих по предпочтению пользователей, которые ранее оценили «Авиатора».
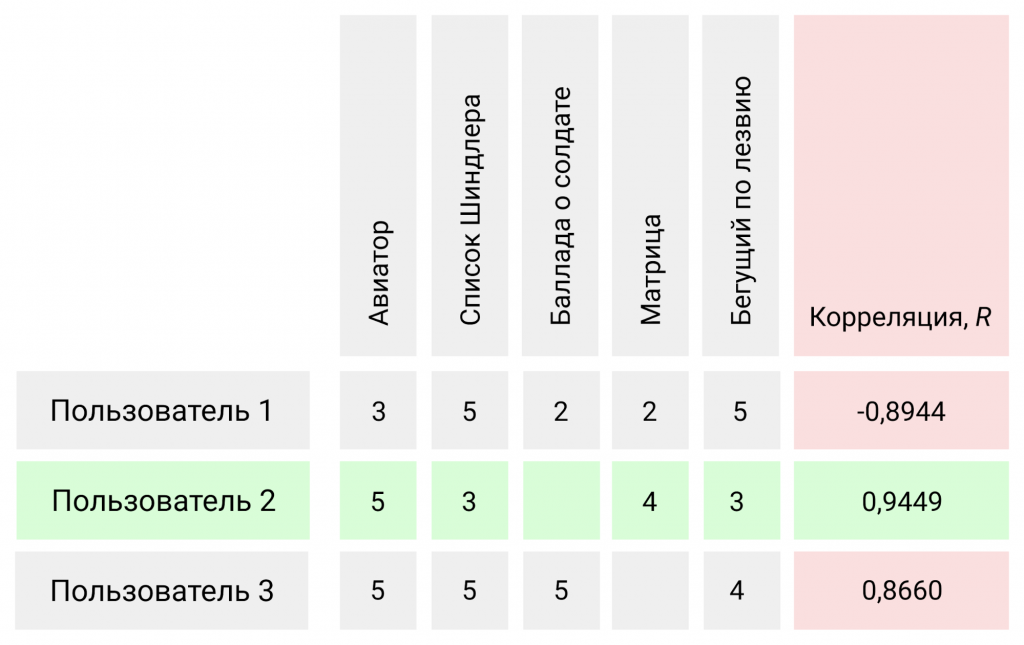
В нашем примере Пользователь 2 более прочих коррелирует с пользователем A, и с учетом его оценки, пользователю A с высокой степенью вероятности понравится «Авиатор», следовательно это фильм можно ему порекомендовать.
Второй вариант: ищем однотипные фильмы
Второй способ фильтрации (Content-Based Filtering) отличает лишь то, что за основу берутся похожие группы контента (в нашем случае — похожие фильмы). И по тому же принципу выявляет степень соседства между фильмами.
На деле применение алгоритма выглядит куда сложнее и чаще всего представляет собой гибридную модель.
Данные и проблемы с ними
Когда есть данные, лучшего сценария для рекомендательной системы и придумать нельзя. Однако бывает и по-другому, что порождает проблемы. К примеру, проблема холодного старта (когда мы ничего не знаем о пользователе, следовательно, неясно что ему рекомендовать), или проблема нового контента (что порождает проблему разнообразия), или синонимия (когда похожие и одинаковые предметы имеют разные имена, например, жанры «детский фильм» и «фильм для детей»). Поэтому приходится логировать (т.е. сохранять в памяти системы) все, пытаясь «между строк» предугадать намерение пользователя.
Так, совокупность данных формируют явные (explicit ratings) и неявные (implicit ratings) информационные сигналы, получаемые от пользователей. На примере кино: явным сигналом может служить оценка, неявным — просмотр трейлера. Вес этих сигналов также будет индивидуален (оценка представляет большую ценность для сервиса).
Как все это работает на практике? Пример Netflix
Для демонстрации современного образца рекомендательных систем обратимся к Netflix — сервис, который поставил качество рекомендаций во главу угла и не прогадал.
Кто хочет стать миллионером?
История эта берёт своё начало в 2006 году, когда компания по аренде DVD дисков с миллиардным годовым оборотом решила повысить релевантность рекомендаций и объявила конкурс на 1 млн. долларов, который достанется тому, кто сможет улучшить текущее качество прогноза не менее чем на 10%. Качество прогноза измерялось на основе среднеквадратичного отклонения (Root Mean Square Error) и на момент объявления конкурса составляло 0.9514. Целью же было снизить эту ошибку как минимум до 0.8563.
В качестве обучающих данных был использован датасет из 100 с лишним миллионов реальных оценок пользователей сервиса. Соревнование длилось порядка трех лет. Сперва ошибку удалось снизить на рекордные 7%, что долгое время оставалось недостижимой планкой для остальных команд. Однако в итоге награда нашла своего героя, не без драмы правда — сразу две команды с разницей в 20 минут выложили свои решения, удовлетворяющие требованиям с точностью до четвертого знака после запятой. Наиболее расторопной оказалась команда «BellKor’s Pragmatic Chaos», которой удалось улучшить результаты на 10,06%.

Спустя 10 с лишним лет обучающийся алгоритм Netflix стал учитывать уже не только оценки пользователей, но и весь доступный контекст — время суток, данные о возрасте и поле, географическое положение. Сам алгоритм использует не только регрессионные методы прогнозирования, но и метод сингулярного разложения, генеративные стохастические нейронные сети, обучение ассоциативным правилам, градиентный бустинг и многое другое, что формирует архитектуру под капотом.

Чего ждать от рекомендательных систем завтра?
В начале этой статьи была намеренно упущена третья проблема выбора фильма — мы, за редким исключением, сами не знаем, чего по-настоящему хотим. Иначе говоря, за фасадом «что я хочу посмотреть» чаще всего лежит куда более глубокое «что я хочу».
Если брать линейность как основную методику прогнозирования, можно предположить, что как поисковые системы сегодня формируют поисковый информационный спрос, так и стриминговые сервисы (Netflix, Amazon Prime, Hulu, HBO и другие) влияют на киноиндустрию, определяя принципы производства нового контента. Если производители контента и площадки добьются необходимой синергии, то потребность в рекомендациях с высокой долей вероятности будет снижена или даже упразднена.
Иными словами, будут снимать ровно то, что будет востребовано, и вопросы «что я хочу посмотреть» и «что я хочу» перестанут волновать аудиторию, поскольку ответ будет получен до возникновения самого вопроса.