Статьи в научных журналах — главный продукт современного ученого. Ежегодно исследователи производят около миллиона публикаций. Навигация в этом огромном информационном потоке остается нерешенной задачей. Одна из ключевых проблем — содержание научных статей трудно индексировать для электронного поиска. Мощным подспорьем здесь могут послужить алгоритмы машинного обучения (ML) и обработка естественного языка (NLP).
Уже сейчас существуют системы поиска, позволяющие находить в огромных массивах данных не просто ключевые слова, а скрытые взаимосвязи, и ранжировать результаты по релевантности. Увы, пока семантический анализ в системах поиска далек от идеального. Использование алгоритмов машинного обучения и NLP позволит улучшить качество поиска научных статей и существенно упростит работу.
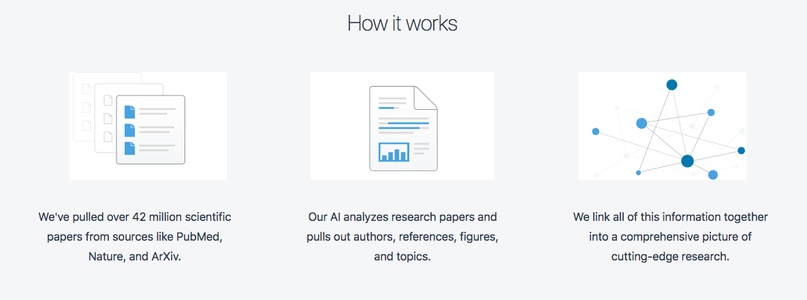
Стартапы, внедряющие семантический поиск по научным статьям, уже существуют. Многие из них предоставляют сервисы поиска близких по смыслу статей на основе ключевых слов, краткой аннотации (абстракта) или ссылки на документ. Получив их, такой поисковик возвращает близкие или смежные статьи в виде сети.
Близость статей передают через силу (вес) связей в получившейся сети. Так пользователь может увидеть на группы наиболее схожих статей в виде плотных клубков.
Еще научный поисковик может использовать рекомендательную систему, как в Amazon или Netflix. Статьи, которые понравились пользователю А, могут рекомендовать пользователю B, у которого схожие научные предпочтения.
В биомедицине поисковики пытаются искать не только по текстам, но и по изображениям. Однако результаты их анализа всё ещё требуют проверки человеком — алгоритмы компьютерного зрения не дают стопроцентной точности.
P.S. Если вас интересует компьютерное зрение, почитайте наши статьи о переносе стиля изображения или об использовании алгоритмов для анализа телесериалов. А если вы хотите узнать больше о сетевом анализе, загляните в статью о социальных сетях в русских пьесах.

