
Раньше машинные переводчики работали по правилам, которые писали лингвисты. Лингвистов нужно было много, а составлять правила было долго и утомительно. Но потом на помощь человеку пришли компьютеры и статистика.
Появилась идея — давайте загрузим в память вычислительной машины «параллельный» корпус текстов, то есть их коллекцию на некотором языке и перевод. Для каждого предложения явно укажем, какому из переводных предложений оно соответствует. И всё — больше компьютер ничего заранее не «знает» о своей коллекции текстов, но, пользуясь ей, научится переводить.
В чем замысел статистического переводчика?
Коротко: если предложение со словом Х часто сопоставляется предложению со словом Y, компьютер предположит, что Х=Y.
Вот в памяти компьютера оказалось два предложения: «Я вижу дом» и «I see a house». Между ними стоит знак равенства. Если дать статистическому переводчику команду перевести слово «дом» на английский язык, то он вынужден будет предположить, что слово с равной вероятностью переводится как «I», или как «see», или как «a», или как «house». Не слишком полезно. Но вот мы заносим в память системы второе соответствие: предложение «Этот дом большой» перевели как «That house is big». Получается, если судить уже не по одному, а по двум предложениям, то все слова «that, big, see, a» встретились в них по одному разу, а «house» — дважды. В точности, как и слово «дом» (и никакое другое). А значит, по сравнению со всеми остальными вариантами увеличивается вероятность соответствия «дом = house», между ними установилась связь. Когда компьютер собирает данные не о двух предложениях, а о тысячах, становится возможным решать задачи по переводу.
Это важно: у каждого соответствия, которое таким образом запомнит компьютер, своя вероятность.
Где взять обучающую коллекцию текстов?
Спойлер: перевести вручную
Заранее переведенные предложения человек подготавливает сам. Для обучения часто выбирают протоколы заседаний многоязычных организаций или инструкции — их переводят как можно точнее, почти буквально. Переводчикам художественных текстов приходится слегка переписывать слова иностранного автора, чтобы адаптировать его замысел, а это мешает обучать статистическую систему.
Компьютер догадался, что дом = house. Что делать дальше?
Коротко: сделать такие же догадки для всех остальных слов, а потом объединить их во фразы
Просмотрев большой текст, машина составляет словарь вероятностей перевода, то есть какие варианты перевода она чаще всего предполагала, основываясь на обучающей коллекции текстов. Переводя предложение, статистический переводчик выбирает самые вероятные переводы каждого отдельного слова и строит из них предложения по специальным правилам, про которые мы еще расскажем.
Конечно, переводить отдельные слова — слишком просто, это приведет к ошибкам. Как научить переводчик учитывать контекст, чтобы после слова «альпинистская» слово «кошка» не переводилось бы как «cat»? В зависимости от контекста меняются и вероятности перевода конкретного слова тем или иным способом. Тут на сцену выходит фразовый перевод.
Фразовый переводчик старается перевести по несколько слов сразу (по «фразам»), если эти слова встречались или могли встречаться рядом в обучающих данных. Для каждого предложения машина генерирует много вариантов, как можно разбить предложение на фразы, как их лучше всего перевести, какие переводы выбрать и как потом сгруппировать.
Раскраски для компьютера
Коротко: сейчас будем решать, какие фразы достаточно устойчивые, а какие — нет
Давайте рассмотрим детальнее, как работает алгоритм статистического переводчика Moses. Сначала программа составляет две таблицы соответствия слов, прямую, например, англо-немецкую, и обратную — немецко-английскую.
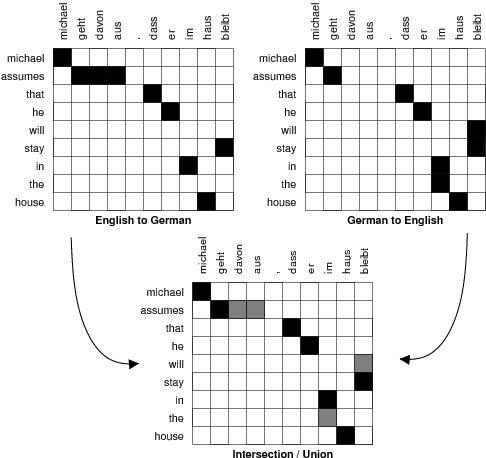
Черные ячейки в обеих верхних таблицах — самые вероятные варианты перевода какого-нибудь одного слова с одного языка на другой. В «обратную сторону» варианты перевода не всегда совпадают, и обязательно найдутся «точные» пары соответствий, которые есть в обеих таблицах (например, assumes = geht, geht = assumes), и такие, которые есть только в одной из таблиц. Те соответствия, что нашлись только в одной из таблиц, помечены серым на нижней картинке. Они самые интересные — дальнейшая работа алгоритма обучения переводчика будет крутиться вокруг того, какие варианты перевода внести в словарь, а какие — отбросить.
Решая, стоит ли включать «неточное» соответствие в словарь, программа спрашивает себя:
- в какой из таблиц нашлось соответствие (в англо-немецкой или в немецко-английской)?
- оно стоит рядом с уже установленным соответствием или, может, по диагонали от него?
- если закрасить ячейку черным, попадет ли в словарь новое слово, для которого раньше не было соответствий?
- какова лексическая вероятность нового соответствия?
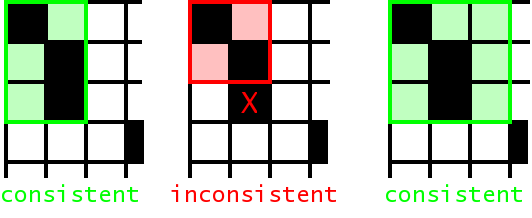
Создатели переводчика Moses решили, что стоит включать в словарь новые соответствия, просматривая таблицу с правого верхнего угла, добавляя сначала серые ячейки, которые напрямую примыкают к черным, а затем — те, что по диагонали. При этом добавлять можно только ячейки тех слов, которых до сих пор не было в словаре.
Хорошо, некоторые серые точки в таблице соответствий программа по своим внутренним правилам закрасила черным, а некоторые — белым, отбросила. Для чего это было нужно? Дело вот в чем: теперь в таблице появились небольшие «островки» из черных ячеек, примыкающих друг к другу. Они-то и будут фразовыми соответствиями, которые программа занесет в память и будет стараться найти. Фразовым соответствием считается только такой «островок», к которому напрямую не примыкает никакая другая ячейка (рядом с островком могут оставаться пустые ячейки, как и показано на рисунке)
Ниже — пример того, какие фразовые соответствия удалось бы построить статистическому переводчику, если бы он анализировал два предложения: Maria no daba una bofetada a la bruja verde и Mary did not slap the green witch. Каждое соответствие обведено цветным прямоугольником.
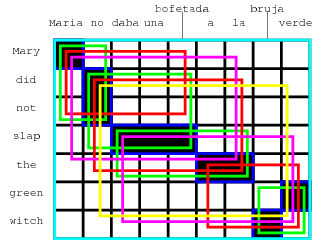
Обратите внимание: все эти манипуляции с островками алгоритм совершал, по сути, чтобы выяснить, что три слова «daba una bofetada» можно переводить одним словом «slap», а не тремя.
Как выбрать лучший перевод?
Коротко: выбирая цепочку переводов отдельных фраз, мы вычисляем условную вероятность всей цепочки, зная вероятность отдельных «звеньев», фразовых переводов. Кстати, вариантов цепочек должно быть несколько, так надежнее, но не слишком много.
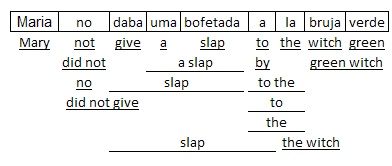
Любое предложение можно разбить на фразы множеством способов, и, в свою очередь, для каждой фразы придумать по несколько вариантов перевода (это не просто словосочетание, а прямо термин). Вот так, например, выглядят варианты перевода фраз испанского предложения Maria no daba una bofetada a la bruja verde.
Для выбора лучшего перевода Moses пользуется алгоритмом лучевого поиска (что это такое, мы прямо сейчас объясним). Нужно перевести предложение Maria no daba una bofetada a la bruja verde. Допустим, у статистического переводчика в словаре 10 000 слов. Чтобы понять, что будет дальше, представим, что кто-то создал переводчик, который генерирует просто случайное предложение на русском в ответ на «скормленное» ему иностранное предложение. Для перевода бесполезно, но кому-то вот так захотелось.
Если бы так работал Moses, то первое слово в поданном на вход предложении можно было бы перевести любым из слов в словаре, начиная со слов «абажур, Абакан», и заканчивая «ящуром» — по алфавиту. Машина, действуя наивно, должна была бы предположить каждый из вариантов и уже для первого слова дать 10 000 вариантов перевода. На втором шаге — для каждого из этих 10 000 — еще по 10 000, формируя 100 000 000 (10 000^2) вариантов фраз из двух слов.
К счастью, задача статистического переводчика — не просто сгенерировать случайное предложение, а попытаться подобрать его кусочки так, чтобы вероятность общего перевода была ненулевой. Значит, не нужно перебирать сто тысяч вариантов: для первого слова в таблице соответствий существует всего несколько вариантов перевода, вероятность которых больше нуля. Не нужно брать их все, но и один тоже не подойдет. Если выбрать только один, самый вероятный, а потом окажется, что он был неправильным, вся дальнейшая цепочка перевода окажется неверной, и ошибку не получится исправить. Поэтому выберем, например, три самых вероятных варианта перевода первого слова и для каждого из них по отдельности будем в дальнейшем решать, как лучше всего перевести второе слово с учетом выбранного первого. В этом кроется суть «алгоритма лучевого поиска», где 3 слова — ширина этого самого луча, количество «гипотез» перевода, которые программа одновременно отслеживает.
Вероятность перевода второго слова рассчитывается как совместная вероятность события «мы ввели иностранное предложение Х для перевода» и события «первым словом перевода оказалось Y». Так, по очереди, слово за словом, а если это возможно, фраза за фразой, программа строит «гипотезы» перевода, у каждой из которых есть вероятность, а есть «цена» — грубо говоря, величина, обратная вероятности.
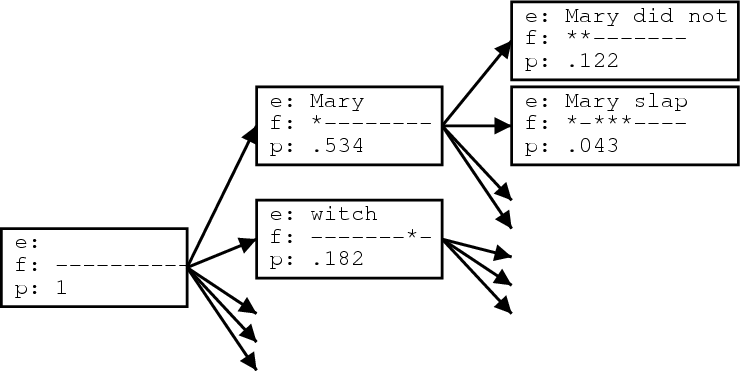
Вот так может выглядеть дерево «гипотез» (цепочек вариантов) перевода предложения из примера Maria no daba una bofetada a la bruja verde. Обратите внимание, что работу переводчик начинает с «начальной гипотезы», где ни одно из иностранных слов не переведено (переведенные слова из иностранного предложения помечаются звездочкой на второй строчке каждого блока). «Р» в третьей строке — вероятность данной гипотезы. Строить новые гипотезы можно только на основе уже имеющихся, а иногда их нужно сокращать, оставляя только самую вероятную, если они совпадают по ряду параметров. Задача алгоритма — найти «дорожку» от первой, «пустой» гипотезы до последней, с наименьшей «ценой», то есть, самой большой совокупной вероятностью перевода.
Примерно так может действовать статистический машинный переводчик: ничего не зная о языке, он способен установить связи между отдельными словами и фразами на разных языках и оценить, какой из вариантов перевода стоит выбрать. Чтобы улучшить систему, добавим тегов частей речи, маркеров числа и рода отдельных слов — будем и их учитывать при расчете вероятностей. А о том, как работает следующая ступень развития технологий перевода — нейросетевые системы — тоже можно прочитать в нашей статье.

