
«Кино для всех»
Технология face keypoint detection распознает лицевые точки, а pose estimation ищет и оценивает позы. С их помощью проводятся масштабные исследования, которые затрагивают различные области. Например, можно изучить, как экспрессия людей в искусстве отличается от их эмоций в повседневности. Участники IV Московско-тартуской школы по цифровым методам в гуманитарных науках представили туториал по этой теме.
В рамках проекта «Кино для всех» создатели хотели найти и измерить различия между движениями людей в искусстве и жизни. Для этого они собрали датасет из 35 фильмов и использовали компьютерное зрение и глубокие нейронные сети для разметки видеозаписей. Особое внимание исследователи уделили углам между конечностями и их мелким движениям.
Итоговый материал стал частью моделей и графиков, которые можно изучить. Они подтвердили предположения создателей туториала о различии экспрессии в различных ситуациях. Теперь мы подробно расскажем о том, какие технологии лежат в его основе.
История FKD
Face keypoint detection — это воплощение теории распознавания образов. Ее задачей считается не только нахождение лица, но и идентификация человека по нему. Сложность в том, что изображение лица одного и того же индивида меняется из-за положения в пространстве, размера, возраста, эмоций т.д.
Биометрическая технология привлекает исследователей тем, что она не проникает через внешние барьеры организма. Потенциал распознавания лиц также имеет широкий междисциплинарный характер. Эта область исследований отличается необходимостью взаимодействия между программистами, учеными и психологами.

В начале исследователи определяли лица по образцу и разбирались в генерации изображений. В этом им помогали свойства человеческой внешности. Их разделили на регулярные (цвет кожи лица, его геометрия, волосы) и нерегулярные (макияж, аксессуары).
Самым ранним примером использования технологии стала система Т. Кохонена. Исследователь продемонстрировал, что простая нейронная сеть может распознавать лица при выровненных и нормализованных изображениях. Он использовал тип сети, который вычислял описание внешности на изображении путем приближения «собственных векторов», матрицы автокорреляции. Сегодня «собственные векторы» известны как «собственные грани».
Технология не имела практического успеха из-за необходимости точного выравнивания и нормализации картинки. Впоследствии исследователи пробовали схемы на основе краев, расстояний между объектами и других «точек опоры». При этом ни один из них не решил проблему местоположения и масштабов лиц. Позже ученые Кирби и Сирович из Университета Брауна в 1989 году представили алгебраические манипуляции, которые легко вычисляли собственные грани. Тесты показали, что для точного кодирования требуется менее ста изображений.
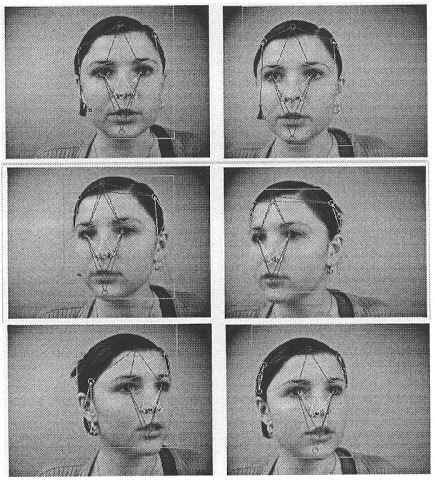
Исследователи М.Турк и А.Пентланд спустя 3 года нашли применение ошибке при кодировании с собственными гранями. Теперь алгоритм мог найти лица в сложных естественных изображениях и определить их точное местоположение и масштаб. Объединение методов обнаружения, нахождения и распознавания позволило точно определять лица в реальном времени с минимальными ограничениями среды.
В 1993 году компания FERET во главе с Джонатаном Филлипсом создала программу для оценивания эффективности предложенных алгоритмов. Они опирались на методы преобразования собственных лиц, моделирование отличий, линейный и квадратичный дискриминанты. Алгоритмы предназначались для государственных учреждений США. Филлипс подчеркивал успех технологии, но говорил об ее ограничении из-за неидеальных условий внешней среды. Системы распознавания внешности были еще неустойчивы к отклонениям при анализе нечетких изображений. При этом производительность алгоритмов постепенно улучшилась, что стало заметно сейчас.
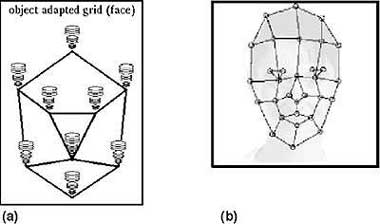
Позже исследователи выявили 15 ключевых точек на лице, число которых затем выросло. Появились такие структуры, как нейронные сети со скрытым слоем и с условными обозначениями, CNN и глубокое обучение (deep learning). Это развило технологию поиска необработанных или затемненных изображений лица.

Модели определения лиц
Чтобы получить представление о внешнем облике человека, необходимо перевести изображение в двухмерную систему координат. Так сохраняется качество картинки и решается проблема размерности. Для ее сокращения применяют следующие методы:
- Преобразование Карунена-Лева (анализ основных компонентов);
- Аппроксимация Ритца (представление на базе образцов);
- Представление с редкой фильтрацией (струйные и волновые преобразования Габора);
- Гистограммы признаков;
- Анализ независимых компонентов.
В методологии существуют еще модели отличий. В них моделируются различия между классами изображений. Системы могут превосходить по точности и эффективности PDF (плотность вероятности) и использовать классификаторы отличий.
Для поиска, выравнивания и проверки лица широко применяют глубокие нейронные сети. Раньше в качестве вводных функций для них использовались входные данные LBP. Вместе с HOG (гистограммой направленных градиентов) они показали лучшее обнаружение при сочетании с традиционными методами. Сегодня эта технология снова становится значимой. Результаты алгоритмов нейроструктур стали качественнее и научились быстрее выделять признаки и размеры лиц.
Самые популярные современные методы — это алгоритмы извлечения признаков по голографии Габора и функции, которые используют графическую модель вероятности. Их создают вручную и часто объединяют для повышения производительности с разработками LFW. В этих алгоритмах элементы извлекаются и сопоставляются с «галереей» путем поиска и подгонки данных к ключевой точке. Системы, которые возглавляют графики производительности, используют десятки тысяч дескрипторов изображений лиц. Вектор признаков может обрабатываться алгоритмами машинного обучения для классификации внешности.

В других методах применяют графические модели вероятности для определения взаимосвязи между пикселями и функциями. Марковские случайные поля используют созвездия, которые могут образовывать точки лица. Метрические методы обучения с конкретными задачами также широко распространены. Наиболее успешные системы работают на большом наборе данных помеченных лиц и технике обучения переноса. Они адаптируют объединенную байесовскую модель на наборе данных, которая содержит 99 773 изображения из 2 995 различных предметов.
Репрезентативный метод распознавания носит описательный характер. В нем используются обучающие изображения, которые характеризуют диапазон двумерных обликов объекта. В начале применялись простые методы моделирования, теперь же это функция PDF.
О красоте, геометрии и технологии
Одна из самых больших проблем для обнаружения лицевых ключевых точек — сложность вычислений. Например, лицо на видео отслеживается в трех измерениях. Сюда входят оценка позы головы, концентрация внимания и взгляда и распознавание зрительной речи. Для полной информации также важно обнаружить человека на видео и отследить его движение. Такие параметры необходимы, например, для создания масок и эмодзи, управления анимацией и технологии motion capture.
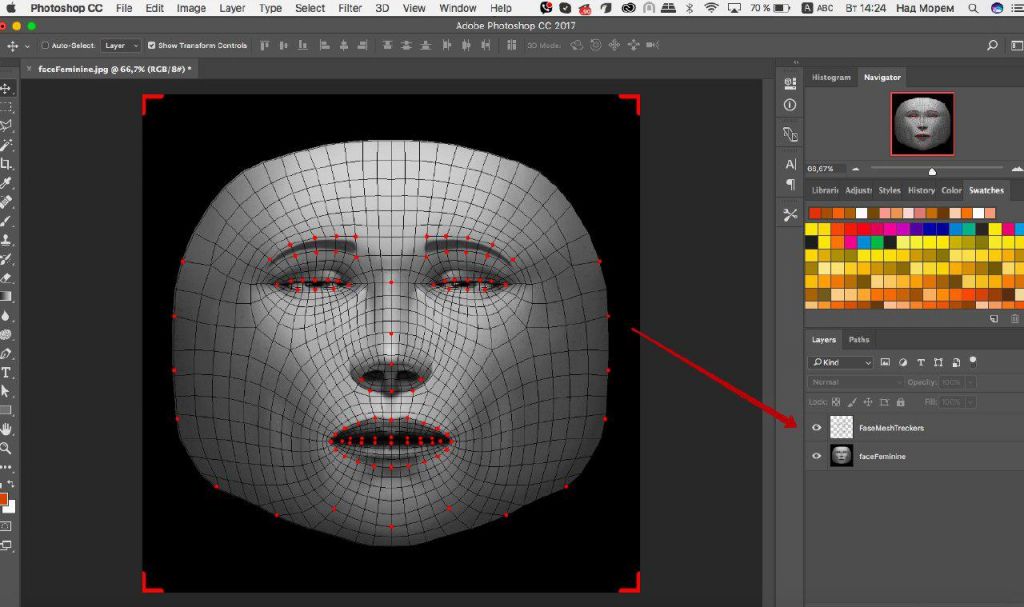
Комбинация тона кожи и ее текстуры применяются при интерпретации внешности. В определении местоположения и размера лица используют пирамиду изображения. Набирают популярность фронтальные системы, которые реагируют на движения. При этом учитываются перемещение, масштаб и вращение в плоскости и в глубину.
Исследователи Брунелли и Поджио сравнили подходы относительно внешнего вида и геометрии лица. Оказалось, что большинство систем сегодня используют сочетание обоих способов. Геометрия более устойчива к маскировке и старению, а внешний вид улучшает точность при определении изображения. Системы находят лицевые ориентиры и деформации с помощью нейтральных позы и выражения.
Немного про PE
Pose estimation — это поиск положения ключевых точек человеческого тела и иногда тел животных. При этом технология часто «конфликтует» с «объектами». Во-первых, наложения и сочленения конечностей, анатомические и внешние особенности затрудняют захват и создают трудные пространственные помехи. Во-вторых, изображение может содержать неизвестное количество людей в любом положении или масштабе. Из-за этого у детекторов и датчиков движения возникает много сложностей.
Разработчики рассматривают PE в двух направлениях: регрессии и сегментации. В первом подходе для каждого обнаружения запускается оценка позы и несколько проверок для определения человека в пространстве. Чем больше людей находится на изображении, тем больше вычислений. Во время «обучения» меток используют поверхностные и тепловые карты, которые синтезируются для каждого соединения тела отдельно. Такой подход к ключевым точкам полезен при решении простых задач.

В сегментации предсказывается класс для каждого пикселя тела, «совокупности частей». Эту задачу выполняют детекторы, которые оценивают разные пиксели и показывают пространственные связи между ними. Их время вывода информации пропорционально количеству людей и они допускают меньше ошибок. Минус сегментации в том, что в ней не используются глобальные контекстные сигналы от других конечностей или людей. Она не наращивает эффективность, а конечный вывод данных стоит дорого.
Исследователи Ян и Раманан использовали модель деформирующихся деталей, которая выражает сложные соединения. Это глобальные наборы шаблонов деталей и наборов, которые сопоставляются на изображении для распознавания/обнаружения объекта. Модель на основе деталей может хорошо моделировать сочленения. Такой результат достигается ограничением выразительности и не учитывает глобальный контекст.

Раньше наиболее эффективной библиотекой для PE была DeepCut, которая маркировала детали изображения и связывала их с отдельными людьми. Стоит отметить, что ее не обошла стороной главная проблема технологии: время обработки занимало много времени. Попытки использовать DeepCut с более мощными детекторами деталей на основе остаточных сетей и попарно-зависимых ядер были малоудачными. Количество деталей оставалось ограниченным в каждой позиции, и они по-прежнему долго обрабатывались.
Методы для изучения поз
В дальнейшем ситуацию изменили DeepPose на CNN и глубокое обучение. Большинство современных систем приняли ConvNets в качестве основного строительного блока. Такая стратегия заменила созданные вручную функции и графические модели и создала новый эталон тестов. DeepPose был первым, кто применил глубокое обучение к оценке позы человека. Подход предполагает целостное оценивание, что является сильной стороной технологии.

Ещё один современный подход к определению позы — это применение полей сходства деталей. Такой метод использует все изображения в качестве входных данных для многоступенчатой CNN с двумя ветвями. Это позволяет лучше «угадывать» и находить части тела и конечности и ассоциации для них.
Каждая стадия в первой ветви предсказывает «карты достоверности» конечностей, а во второй ветви предугадывается их положение. После каждого этапа прогнозы и характеристики изображения из двух ветвей объединяются для уточнения. Оценки становятся чётче с помощью глобального вывода на более поздних стадиях. Для видео же используют технологию ConvNets.
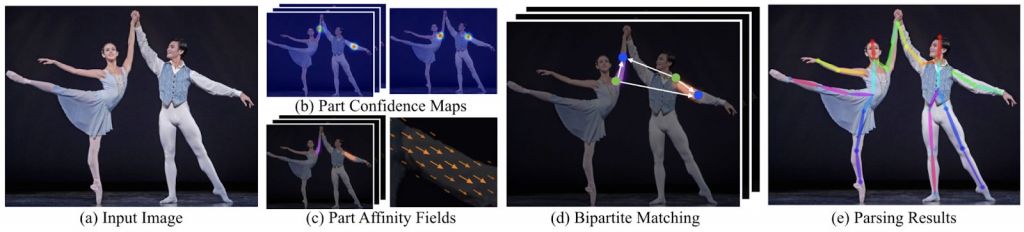
Чтобы собрать позу, нужна «мера доверия», под чем подразумевается ассоциация частей тела с друг другом и с объектом. Предсказывается не только их местоположение, но и ориентация, принадлежность и формирование. В этом снова помогают поля сходства деталей, которые являются 2D векторными полями для частей тела. Для каждого пикселя в области конкретной конечности двумерный вектор кодирует направление от одной ее части до другой. Ключевые точки дают «карту доверия», на основе нейронных сетей и ориентации которой строится поза.
Модель сети с песочными часами с накоплением состоит из объединенных шагов и слоев с повышенной дискретизацией. Информация собирается в любом масштабе, благодаря чему сеть изучает прогнозы. Другая модель, HRNet, использует наборы данных среды COCO. Ее архитектура на первом этапе начинается с подсети с высоким разрешением и постепенно добавляет более высокие и низкие из них. Слияния проводятся путем обмена информацией между параллельными подсетями с множественным разрешением.
Переход к 3D
Оценка 3D позы представляет собой прогнозирование и преобразование объекта из заданной контрольной позы. При этом учитывается не только изображение, но и его сканирование. После позу или объект можно использовать для различных целей. Технология сильно развивается благодаря кинематографу, рекламе и индустрии компьютерных игр. Да-да, актеры в серых костюмах с датчиками и разметкой на лице как раз отсюда.
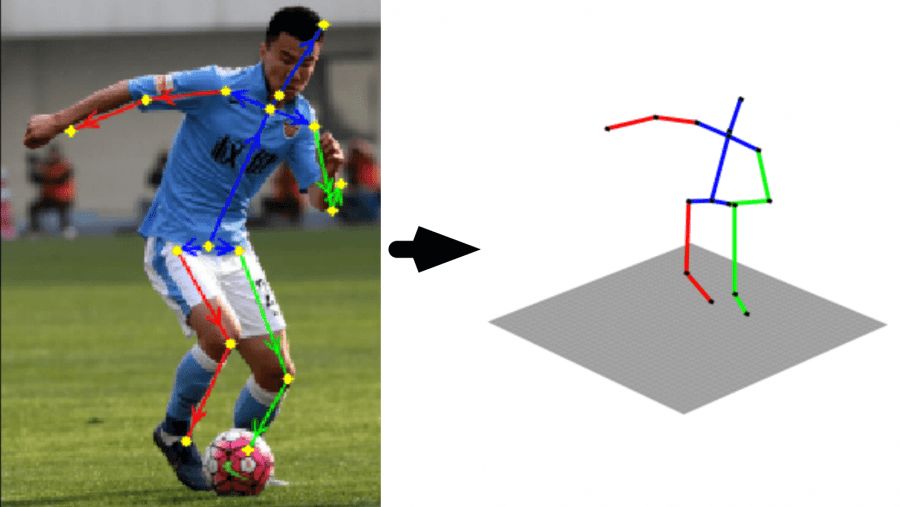
Трёхмерную модель можно создать как с некалиброванной, так и с калиброванной 2D камерой. Для этого необходимо знать ключевые точки в исходном изображении или оптимизировать расстояние по параметрам позы. В первом случае лучи из двухмерных точек картинки «восстанавливаются» до трехмерных и совпадают с восстановленным. В другом используется итерационный алгоритм ближайшей точки. В результате определяются соответствия между особенностями 2D-изображения и точками на кривой 3D-модели.
Существуют также системы, которые используют базу данных объекта при различных поворотах и трансляциях. Их точность имеет ограничения, но их используют только для распознания позы. Таким способом определяется входное изображения и оценка положения.

