
(Не)понятность русского текста
Как оценить понятность русского текста? Кажется, что детская сказка будет проще, чем научная статья. А официальные тексты, написанные на русском «канцелярите», наверное, самые запутанные и непонятные. От чего зависит сложность текста и в чем ее выразить? Компьютер может помочь ответить на эти вопросы, нужно только создать подходящий алгоритм.
Мы рассказывали про автоматическую оценку сложности текста: для этого придумано множество метрик. Алгоритмы основаны на различных языковых параметрах, например на количестве частотных слов или длине предложений.
Лучше всего эти методы работают для текстов на английском языке: им посвящают научные работы, их применяют на практике. Но для русского языка имеющиеся формулы не подходят. Здесь мы расскажем об очередной попытке решить эту проблему.
Поиск решения
Вопросом понятности русских текстов заинтересовался Иван Бегтин, директор некоммерческой организации «Инфокультура». Он не только организовал вместе с коллегами конкурс приложений по этой теме (см. Конкурс Apps4Russia 2014), но решил и сам заняться разработкой.
Создать свою метрику по примеру имеющихся оказалось непросто: американские алгоритмы тестировались в университетах и школах — так исследователи смогли определить, одинаково ли сложность текстов оценивает формула и люди. У Бегтина не было ни времени, ни ресурсов для такой проверки, поэтому он нашел другой подход: попытался адаптировать существующие формулы для русского языка.
Для этого он собрал тексты с известной степенью сложности. Это тексты для внеклассного чтения, для которых обычно указывают рекомендуемый возраст и класс, и заведомо сложные официальные тексты.
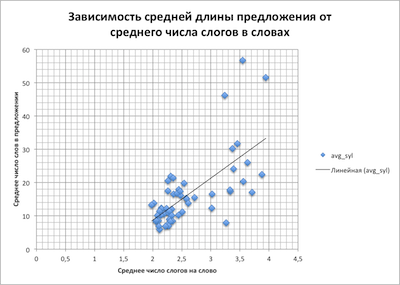
Затем он рассчитал значения всех языковых параметров, входящих в метрики, и проверил, как они зависят друг от друга. Получилось, например, что чем больше в предложениях слов, тем больше в них слогов:
Уточнение формул
Чтобы понять, что нужно было адаптировать, посмотрим на одну из метрик читабельности:
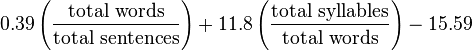
Это тест Флэша-Кинкайда. Для расчёта сложности используются 3 параметра:
· total words — всего слов
· total sentences — всего предложений
· total syllabes — всего слогов.
Константы для формулы подбирали создатели. В результате получаем число — столько лет нужно проучиться по американской системе образования, чтобы понять исследуемый текст.
У Бегтина было 55 русских текстов. Все переменные были известны: уровень образования, необходимый для понимания каждого текста, и все количественные параметры (среднее число слогов на слово, среднее число слов на предложение, среднее число букв на слово и так далее).
Осталось только подобрать константы. Для этого достаточно подставить в формулы уже известные значения, принять константы за неизвестные и решить уравнения. В итоговую формулу были включены средние значения констант. Таким образом, удалось адаптировать формулы к русскому языку.
Результат и его применение
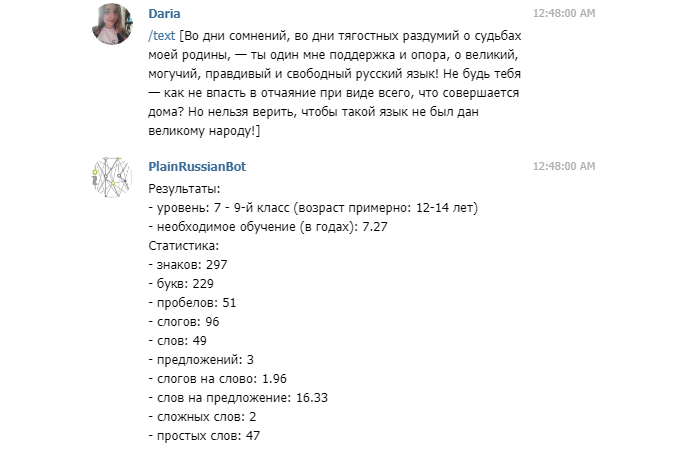
На основе своих разработок Бегтин создал онлайн-сервис. Туда можно загрузить любой текст и проверить его сложность. У этого сервиса есть API* и даже бот в Телеграм: @PlainRussianBot. Сервис выдаёт средний по пяти метрикам уровень читабельности текста и статистику его языковых параметров.
Что дальше?
На этом изучение сложности русских текстов не заканчивается. При всей эффективности разработок, Бегтин признает, что его формулы несовершенны. Нужны дополнительные тестирования, в том числе с привлечением людей.
Вопросы о том, какие параметры формируют сложность текста, как создать подходящую метрику и как ее проверить, остаются открытыми. Больше об эксперименте Ивана Бегтина читайте здесь.
*API — готовый код какого-либо приложения, который можно дописать и приспособить к своей задаче.

