
Практически все системы нейронного машинного перевода создавались для одной языковой пары — обработать несколько языковых пар, не изменяя базовую модель НМП, было невозможно.
В 2016 г. исследователи создали такую модель: они объединили одноязычные модели в одну структуру и добавили в начало исходной последовательности специальный символ, чтобы указать требуемый язык перевода. Все остальные части системы, такие как кодировщик (энкодер), декодер, механизм внимания и общий словарный запас модели остались без изменений.
Структура такой многоязычной модели идентична системе нейронного машинного перевода Google (GNMT), но в некоторых экспериментах к ней были добавлены прямые соединения между уровнями энкодера и декодера. Чтобы использовать многоязычные данные в рамках одной системы, специалисты предложили изменить входные данные и добавить в начале исходного предложения специальный токен, указывающий язык, на который должен быть осуществлен перевод. Например, при переводе в паре английский→испанский
How are you? -> ¿Cómo estás?
нужно внести следующее изменение:
<2es> How are you? -> ¿Cómo estás?
чтобы показать, что целевой язык (язык перевода) — испанский язык. Исходный язык не указывается — модель учит это автоматически. После добавления токена к исходным данным модель обучают на всех многоязычных данных, состоящих из нескольких параллельных корпусов одновременно. Чтобы решить проблему перевода неизвестных слов и ограничить словарный запас для эффективности вычислений, применялась общая модель в 32 тыс. слов для всех исходных и целевых данных.
Модели могут включать один или несколько исходных или целевых языков. Разработчики рассмотрели три случая: несколько исходных языков и один язык перевода, один исходный язык и несколько языков перевода, несколько исходных и несколько языков перевода.
Несколько исходных языков и один язык перевода
Это самый простой способ объединения языковых пар. Поскольку существует только один целевой язык, не нужно вводить дополнительный токен. Провели три группы экспериментов: для пар немецкий → английский / французский → английский, японский → английский / корейский → английский, испанский → английский / португальский → английский. Все модели многоязычных и одноязычных пар имели такое же количество параметров, как и базовые модели НМТ, обученные на одной языковой паре. Во всех экспериментах многоязычные модели превзошли базовые одноязычные системы, несмотря на некоторые недостатки в отношении количества параметров, доступных для языковой пары. Объяснить такой успех многоязычной НМТ можно еще и тем, что в модели было представлено больше данных для английского языка и что некоторые исходные языки принадлежат к одним и тем же языковым группам.
Один исходный язык и несколько языков перевода
Здесь провели три группы экспериментов, очень похожих на эксперименты из предыдущего пункта, добавив в начало исходного предложения токен, указывающий на целевой язык. Результаты показали, что многоязычные модели сопоставимы с базовыми моделями и в некоторых случаях превосходят их (значительное превосходство по шкале BLEU получили, например, для языковой пары английский → испанский).
Несколько исходных языков и несколько целевых языков
Самый сложный случай. Поскольку задано несколько целевых языков, к началу исходного предложения необходимо добавить токен для целевого языка. Эксперименты показали, что многоязычные модели с тем же объемом словаря, что и одноязычные, довольно близки к базовым показателям — средняя относительная потеря оценки по BLEU во всех экспериментах составляет всего около 2,5%.
Проводились и более крупные эксперименты — разработчики попытались объединить 12 рабочих языковых пар в единой многоязычной модели. Многоязычная модель потребовала меньше времени и вычислительных ресурсов на обучение, чем объединенные одноязычные модели, но больше, чем стандартная одноязычная модель. Такая многоязычная модель обрабатывает в 12 раз меньше данных, чем стандартная модель, поэтому она переводит в среднем хуже отдельных (от 5,6% до 2,5% потерь по BLEU в зависимости от размера), тем не менее, её результаты признаны удовлетворительными.
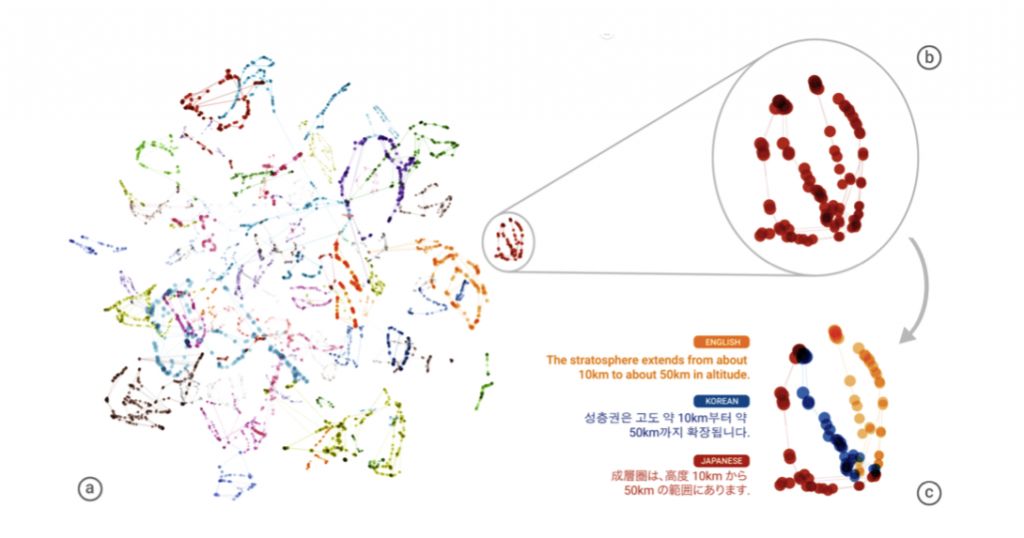
А что, если смешать языки?
После экспериментов с несколькими парами исходных или целевых языков исследователи задумались, что происходит, когда языки смешиваются на входе или на выходе. Может ли многоязычная модель успешно обрабатывать многоязычные входные данные (переключение кода) и что получится, если её запустить со смешением двух токенов для целевого языка?
Чтобы найти ответ, они провели дополнительные эксперименты и установили, что многоязычные модели способны справиться с переключением кода исходного языка в середине предложения. Например, смешивание японского и корейского языков в исходном коде во многих случаях приводит к правильным переводам на английский, что подтверждает: модель может обрабатывать переключение кодов, хотя в обучающих данных таких примеров переключения кодов не было. Интересно, что смешанный перевод немного отличался от переводов отдельных примеров на разных языках на один исходный язык.
Эксперименты же с целевым языком продемонстрировали менее любопытные результаты. В зависимости от определенных параметров модель переводит исходное предложение либо на смесь языков, либо полностью на один из целевых языков с неестественными для него характеристиками (например, порядок слов).
Так откуда разговоры об интерлингве?
Объединив несколько языковых пар в одной модели, разработчики Google получили неожиданный и очень интересный результат: модель научилась переводить в языковых парах, на которых она не обучалась. Например многоязычная модель НМП, использующая примеры языковых пар португальский → английский и английский → испанский, может генерировать допустимые переводы для языковой пары португальский → испанский, даже не используя данные для этой языковой пары. При этом машина больше не переводит через английский («язык-мост»), а использует общие семантические представления между языками. Такой перевод без обучения (zero-shot translation) модель может выполнять только между языками, которые она в определенный момент обучения рассматривала отдельно как исходный и целевой языки.
Больше всего разработчиков удивило, что необученные модели оказались способны выдавать перевод приемлемого качества. Еще бы — ведь изначально это вообще казалось невозможным! Они предположили, что такой эффект возможен потому, что единая структура позволяет модели изучать форму interlingua между всеми этими языками — т.е. модель оказалась способна выявлять общие семантические слои для разных языков и находить им соответствия.
В эксперименте, описанном выше, перевод производился между языками, принадлежащими одной языковой семье (испанский и португальский), и исследователи заинтересовались, насколько хорошо работает перевод без обучения для менее родственных языков. Они сравнили с переводом через английский язык переводы без обучения в паре испанский → японский, использовав свою крупную модель (испанский и японский языки могут рассматриваться как совершенно не связанные). Как и ожидалось, перевод без обучения сработал хуже, и качество перевода упало сильнее (по BLEU — примерно на 50%), по сравнению со случаем для более родственных языков.
Несмотря на снижение качества, исследователи пришли к выводу о том, что такой подход позволяет осуществлять перевод даже между несвязанными языками. Говорить о том, что существует универсальный язык, через который Google научился переводить тексты с любых языков, пока рано. Но возможно Google подобрался еще на шаг ближе к тому, как переводит человек.
Материал подготовлен совместно с группой переводческих компаний AKM Translations
Источник: Google’s Multilingual Neural Machine Translation System: Enabling Zero-Shot Translation
Читать по теме: Нейронные сети в машинном переводе: статус-кво

