
Технологии меняют естественные, социальные и гуманитарные науки — частично потому, что порождают диалог между дисциплинами. Гуманитарии обращаются к этому диалогу, когда появляется необходимость в цифровых инструментах для автоматизации решения привычных задач.
Статистические модели, к примеру, которые помогают социологам изучать социальную стратификацию и отслеживать изменения в обществе, раньше мало чем были полезны в гуманитарных науках, их трудно было использовать для данных из письменных источников. Сейчас этот барьер исчезает. Благодаря новым способам обработки информации теперь легче преобразовать неструктурированные тексты в статистические модели, что значительно расширяет возможности как социальных, так и гуманитарных наук.
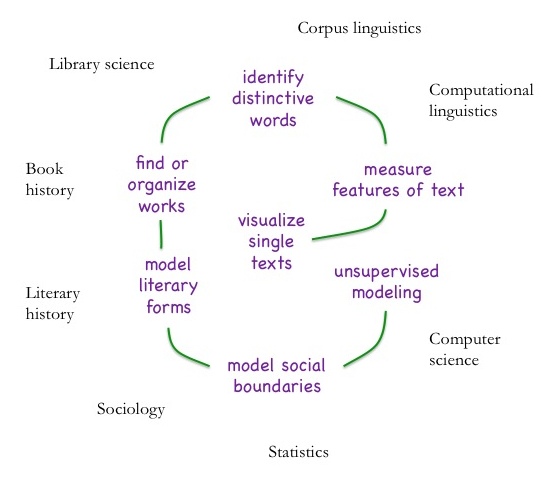
Визуализация отдельных текстов
Существуют способы анализа текста, похожие на поверхностное чтение, поскольку они отражают элементы текста, доступные при беглом прочтении.
Для наглядности приведем в пример популярные на Западе комиксы Рэндалла Манро по мотивам фильмов: они не содержат новых для читателя данных, а просто обобщают то, что ему и так известно. Тем не менее они находят свою аудиторию. То же и с конкордансами: они не показывают нам ничего такого, чего бы мы не нашли самостоятельно. Но даже критики признают их практическую пользу.
В работе над отдельным корпусом прекрасным подспорьем может стать AntConc.

Отбор репрезентативных характеристик текста
На практике исследователи чаще всего выбирают подсчет частотности слов, встречающихся в тексте, — так называемую модель bag of words («набор слов»). Такой способ сильно отличается от привычного нам способа восприятия текста, так что некоторых удивляет его эффективность. Основываясь на частотности слов, можно определить общие характеристики текста: автора, тему, жанр, целевую аудиторию и так далее. Популярность сервиса Ngram Viewer от Googleговорит о том, что люди находят применение таким данным.
Однако способов репрезентации текста множество. В компьютерной лингвистике уже широко применяется парсинг; в Сети можно найти много интересных проектов вроде Natural Language Toolkit.
Определение характерной лексики
С помощью новых технологий можно под другим углом взглянуть на свойственную определенному автору манеру изложения.
К примеру, считается, что Уильям Вордсворт воспевал и романтизировал одиночество, поскольку в его произведениях часто встречаются слова «одиноко», «сам», «один». Конечно, Вордсворт использовал их очень часто. Но чаще ли, чем другие авторы? Можно ли это считать характерной особенностью его творчества?
Специалисты в области корпусной лингвистики разработали множество способов находить выражения, которые чаще остальных встречаются в одном тексте по сравнению с другими. Наиболее широко для этой цели применяется логарифмическое правдоподобие — эту функцию можно опробовать онлайн с помощью проекта Voyant или загрузив приложение AntConc. Имея образец текста, например стихотворение того же Вордсворта, и корпус для сравнения, скажем собрание стихотворений других поэтов, вы легко сможете найти выражения, которые выделят Вордсворта среди остальных поэтов. И, да, Вордсворт действительно слишком часто писал про одиночество.

Поиск по тексту или организация текстов
Очевидно, что способов использовать компьютерные технологии, для того чтобы организовать тексты или ориентироваться в них, великое множество. Гуманитарии прибегают к подобным инструментам постоянно, будь то веб-поиск или поиск по ключевым словам в каталогах и полнотекстовых базах данных. При желании они могут использовать карты для визуального представления связей с конкретной территорией или местом публикации. Или группировать тексты по определенным критериям.
Однако существующие на данный момент стратегии не всегда позволяют найти то, что нам нужно. Это особенно проблематично для историков, поскольку им приходится работать с данными, которые не представлены в текстовой форме или не оцифрованы. Актуально это, впрочем, и для опубликованной литературы: для большей части текстов, увидевших свет до 1960 года, даже не указан жанр.
В каждом случае инструменты подбираются индивидуально, однако зачастую наибольшую трудность представляет сбор метаданных для анализа, нежели поиск подходящего программного обеспечения.
Моделирование литературных форм или жанров
В социальных науках статистические модели зачастую представляют собой формулы, описывающие вероятность существования взаимосвязи между переменными. Исследователи выбирают явление, которое хотят изучить, и пытаются его смоделировать.
Гуманитариям создание модели на основании такого подхода тоже может принести пользу. Например, чтобы понять разницу между двумя жанрами, нужно построить модели, демонстрирующие особенности каждого из них.
В ходе исследования можно даже создать модель абсолютно нового жанра: не так давно Эндрю Пайпер опубликовал работу, посвященную конверсионному роману (conversional novel).

Причина популярности статистических моделей заключается отчасти в том, что, в отличие от большинства методов, они делают возможным использование сотен и тысяч переменных, позволяя обрабатывать неструктурированный текст. Кроме того, некоторые модели могут не только описывать изучаемый объект, но и строить определенные прогнозы в отношении него.
Моделирование социальных разграничений
Статистические модели текстов не привязаны только лишь к вопросу жанра и формы. Текст практически всегда отражает социальные взаимодействия самого разного характера, а потому его всегда можно рассматривать в этом контексте.
К примеру, можно отследить историю социальной стратификации в литературе с помощью моделей, отличающих поэзию, которая обсуждалась в элитарных изданиях, от случайных текстов из цифровой библиотеки. Результаты будут разнообразными, но основной вывод будет заключаться в следующем: имплицитные характеристики, отличающие высокую поэзию, оставались относительно неизменными.
Неконтролируемое моделирование
Модели, которые мы уже рассмотрели, можно считать контролируемыми — в том смысле, что от исследователей они получают точные параметры для анализа. Но преимущества машинного обучения заключаются еще и в том, что учить можно и неконтролируемые модели. Например, у вас есть необработанная коллекция текстов, и вы просите алгоритм ее организовать на основании кластеров или каких-либо характеристик. Точно задавать эти характеристики вам необязательно.
В последние годы широкий интерес вызвала совокупность неконтролируемых алгоритмов, осуществляющих так называемое тематическое моделирование. В частности, Роберт К. Нельсон применял тематическое моделирование к текстам, публиковавшимся в газетах Ричмонда в период Гражданской войны. Его удобно использовать на семинарах, когда у исследователя нет конкретной цели, — можно просто загрузить в систему разноплановые тексты и посмотреть, что получится, ведь результаты могут впечатлить, подать какую-либо идею и вдохновить на дальнейшую работу. Однако в качестве основного инструмента лучше использовать контролируемые модели.
В последнее время представители гуманитарных наук не только открыли для себя новые способы решения старых задач, но и расширили горизонты. Некоторые из доступных и интересных им инструментов оформлены в виде готовых программ, однако есть и те, что требуют хотя бы поверхностного знакомства со средами для разработки программного обеспечения, как, например, Rstudio, или даже владения языками программирования. По этой причине они, к сожалению, не скоро обретут популярность среди гуманитариев.
Источники:
Ted Underwood «Seven ways humanists are using computers to understand text»

