
Как можно попытаться узнать автора текста, опубликованного под псевдонимом? Есть разные пути: восстанавливать историю произведения, изучать почерк в рукописи, собирать свидетельства современников… Но иногда ничего этого нет, и у нас остается только одна улика — язык текста. В этих случаях можно попытаться использовать статистические методы определения авторства. Мы попробовали их на примере нескольких спорных музыковедческих текстов — и рассказываем, что получилось.
Что за тексты и почему автор неизвестен?
Материалом для исследования стали несколько статей из «Хроники» журнала «Музыкальный современник» за 1916 год и из газеты «Русская воля» за 1917 год. Статьи, написанные в дореволюционный период и в первые годы после революции 1917 года, с тех пор не переиздавались. Многие из статей написаны под псевдонимом или их автор не указан.
Кто такой Асафьев и почему он наиболее вероятный кандидат?

Борис Владимирович Асафьев (1884–1949) — русский советский композитор, музыковед, музыкальный критик, педагог, общественный деятель, публицист. Академик АН СССР (1943). Народный артист СССР (1946). Лауреат двух Сталинских премий. Один из основоположников советского музыковедения. Асафьев оставил значительное наследие во всех областях музыкальной культуры — как историк, теоретик, композитор, философ, журналист.
Асафьев нередко подписывал статьи псевдонимами. Наиболее известный — «Игорь Глебов». Исследователи наследия Асафьева — Елена Михайловна Орлова (1908–1985) и Андрей Николаевич Крюков (1929–2015) — выявили еще шесть псевдонимов: «Иг. Г.», «К», «B’as», «Ъ» (этот псевдоним наш любимый — прим. Системный Блокъ), «Ф. Новиков» и «Абонент».
Мы решили пойти дальше и использовать стилометрию для того, чтобы попытаться определить, не могут ли принадлежать перу Асафьева несколько статей из дореволюционной периодики, подпись у которых отсутствует.
Был создан корпус текстов Асафьева на основе фундаментального издания советского периода — пятитомника «Б.В. Асафьев. Избранные труды» (Издательство АН СССР, 1952–1958).
Как определить автора текста?
Сколько слов необходимо ученому-филологу, чтобы без узнаваемых героев отличить текст Толстого от текста Достоевского? Насколько мы можем быть уверены в результате? Для проведения эксперимента человек, в первую очередь, должен быть знаком с текстами обоих авторов, а во-вторых — знать их характерные особенности.
Когда задача определения автора достается машине — происходит примерно то же самое. Универсальной шкалы сравнения авторов не существует. Например, один постоянно использует тире и пишет длинные предложения. Другой — вставляет только ему присущие словечки. Поэтому, чем больше характеристик текста мы проанализируем, тем точнее будет стилометрический портрет автора.
Зачем нам нужны тексты других музыковедов той же эпохи?
Для сравнения мы взяли тексты коллег и современников Асафьева: Евгения Максимовича Браудо (1882–1939), Виктора Михайловича Беляева (1888–1968) и Ивана Ивановича Соллертинского (1902–1944). Примеры позволят нам понять, чем тексты Асафьева отличаются от произведений его современников, также пишущих о музыке.
Одинаковая тематика текстов важна, потому что позволит отследить общеупотребительные и редкие слова для данной категории. Время написания статей в нашем случае также имеет значение, поскольку они написаны почти сто лет назад. Язык отличается от современного: часть слов вышла из употребления, стиль изложения сегодняшнему читателю покажется старомодным.
Ищем аномалии
Первый шаг — проанализировать тексты авторов по простым количественным характеристикам: длина предложения, среднее число слов, среднее число запятых и тире. По этим параметрам статистически значимой разницы между текстами авторов не обнаружилось.
Следующий шаг — частотные словари. Для каждого автора мы создали словари: всех лемм, встречающихся у автора, словарь прилагательных и словарь служебных частей речи. Далее мы взяли тексты неизвестного автора, построили такую же статистику для них. И самое интересное: посмотрели, к словарю какого автора эта статистика ближе всего. Применяли стандартный подход расчета Z-score (распространенный в статистике метод нормирования данных).

Следующий метод — поиск уникальных словосочетаний. При помощи библиотеки sklearn для Python мы проанализировали слова, а также словосочетания из двух и трех слов. Для каждого автора выделили наиболее характерные. Это слова и словосочетания, которые очень часто встречающиеся у автора и очень редко — у других. Таким образом, их нельзя назвать общеупотребимыми. Вектор слов текста неизвестного автора пересекли с векторами кандидатов и нашли наиболее вероятного.
Следующий способ — не лексический, а синтаксический. Предположительно, каждый автор склонен строить предложения одинаковым для себя способом, и чтобы это проверить, вместо самого словосочетания мы брали цепочку соответствующих ему частей речи. Например, текст «вступление к опере» дает цепочку «существительное + предлог + существительное».
К такому частотному словарю мы применили ранее описанный подход поиска отклонений от среднего.
Как мы поняли какой способ работает лучше (и работают ли они вообще)?
Чтобы оценить качество каждого из описанных подходов, мы заранее выбрали часть авторизованных текстов Асафьева, Соллертинского, Браудо и Беляева в тестовую выборку. Они не участвовали в построении моделей, зато именно на них мы проверяли результаты — ведь в этих случаях сомнений в авторстве изначально нет. Если предсказанный и реальный автор совпадали — значит, модель отработала отлично. Если нет — доверять такой модели нельзя. Итак, результаты, точность определения автора текста для каждой модели:
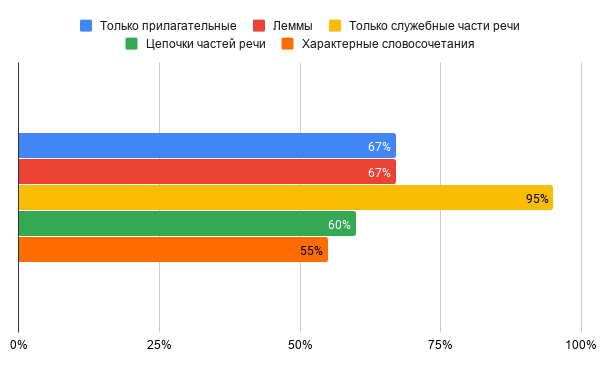
Лучший результат — у статистики по служебным частям речи, худший — у характерных словосочетаний на базе TF-IDF.
Успех использования служебных слов полностью согласуется с достижениями стилометрии последних нескольких десятилетий. Именно опора на частотные и при этом семантически нейтральные предлоги, союзы, частицы и местоимения позволила создать надежно работающие (при условии достаточного объема текстов) методы статистического определения авторства, такие как Delta [Burrows, 2002]. Мы еще расскажем о Delta подробнее в следующих статьях Системного Блока.
Служебные слова как признак авторского стилевого «отпечатка пальца» удачны по двум причинам. Во-первых, они частотны в любом тексте: примерно 15-20% письменного языка состоит из совсем небольшого набора служебных слов; для английского еще больше. Это значит, что на таких словах можно считать статистику, и она не будет подвержена единичным случайностям. Во-вторых, эти слова мало зависят от содержания конкретного текста: предлог «из» или частица «ли» примерно одинаково употребимы в текстах разных тематик. Зато в их частотностях отражаются некоторые черты авторского синтаксиса, излюбленные автором способы построения фраз, предпочитаемые конструкции. Благодаря этому служебные слова оказываются более надежным признаком, который почти не искажает даже намеренная авторская «стилизация» текста. К примеру, стилометрия отлично определяет стилизованный Сорокиным под Тургенева текст как текст Сорокина — и не смешивает его с Тургеневым.
Но вернемся к музыковедам.
Кто же автор?
По итогам тестирования самым точным оказался алгоритм, когда мы анализируем статистику по леммам-служебным частями речи (союз, предлог, частица, междометие). Результат его работы на текстах неизвестного авторства показывает, что с высокой вероятностью первый текст принадлежит Асафьеву, три остальных — неизвестным авторам. Поскольку другие алгоритмы во время нашего предварительного тестирования ошибочно определяли чужие тексты как тексты Асафьева (недостаточная точность при хорошей полноте), их результаты мы не учитываем.
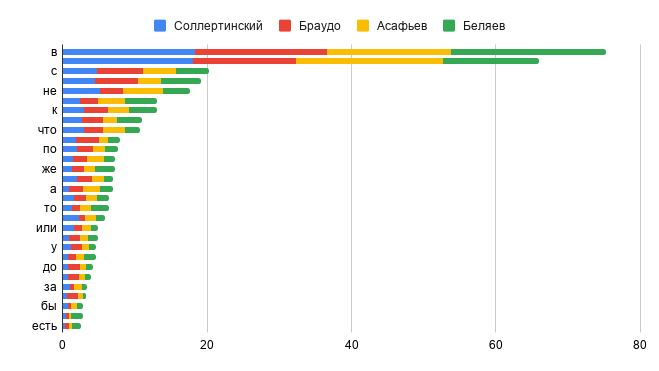
Зачем так сложно, неужели нет стандартной библиотеки?
Есть! И это библиотека Stylo, разработанная для языка R [Eder et al., 2016]. В Stylo реализован тот самый метод Delta, о котором мы говорили выше (и еще поговорим в будущем), а также несколько более новых алгоритмов, производных от Delta. Мы провели ряд экспериментов и с ней. Stylo отлично работает для больших текстов, примерно от 5 тысяч слов. Однако на текстах меньшего объема сигнал теряется, и содержание становится важнее стиля. Например, частое упоминание оперы «Хованщина» в маленькой заметке может приводить к тому, что автором текста определится тот, кто писал обзор на нее. На рисунке видно, что большие тексты безошибочно кластеризовались по автору, но с маленькими статьями есть проблемы.
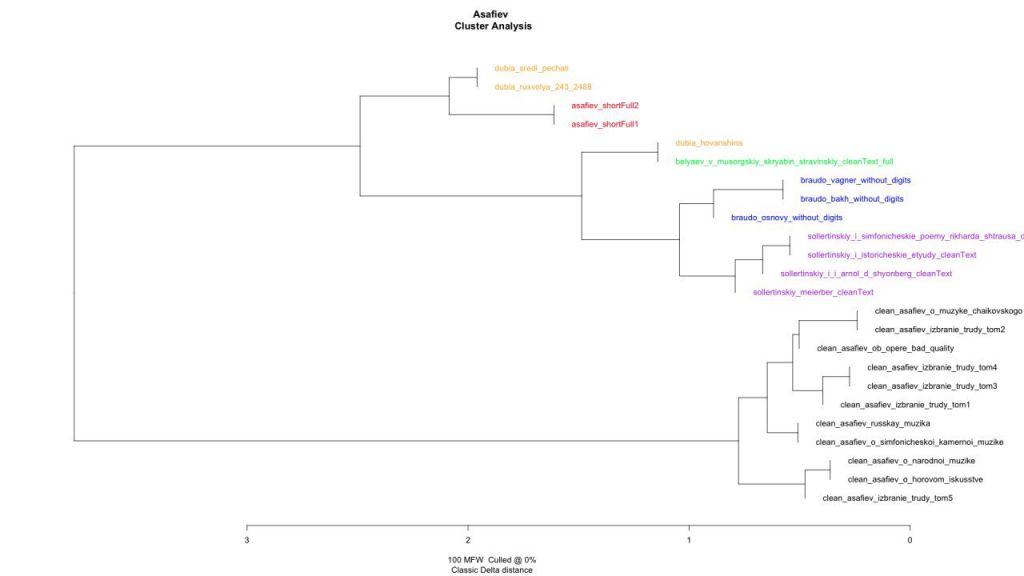
Алгоритм Stylo определил, что Асафьев — автор самого большого из текстов неизвестного автора (1800 слов), что подтверждает наши выводы.
Что дальше?
Короткие тексты не дают достаточно данных, чтобы можно было определить их автора с полной уверенностью. Это известная проблема статистического подхода. К сожалению, три из четырех текстов неизвестного авторства — короткие, менее 500 слов. Однако в результате нашего исследования мы с высокой долей вероятности доказали, что четвертый текст написал Асафьев. Следующий шаг — найти альтернативные способы, хорошо работающие на коротких текстах. Мы готовы обсудить любые ваши предложения и идеи, напишите нам — или присоединяйтесь к команде «Системного Блока» .
При участии Ольги Кельчевской
Источники
- Burrows J. ‘Delta’: a Measure of Stylistic Difference and a Guide to Likely Authorship // Literary and Linguistic Computing. 2002. Т. 17. № 3. С. 267–287.
- Eder M., Rybicki J., Kestemont M. Stylometry with R: a package for computational text analysis // R Journal. 2016. Т. 8. № 1. С. 107–121.

