8 сентября ряд функций Национального корпуса русского языка (НКРЯ) стал недоступен: об этом в фейсбуке сообщила профессор русистики Университета Тромсе Лора Янда. В этом же посте Лора высказала опасение, что проект может быть окончательно закрыт 1 января 2020 года. В сообществе ученых-лингвистов пост вызвал тревогу; стали появляться призывы спасти корпус. [1]
Зачем переживать за корпус?
Корпус — это коллекция текстов, размеченных особым образом. У каждого слова есть набор меток, который позволяет искать в текстах самую разную информацию. Самые крупные корпуса, содержащие максимально репрезентативный набор текстов, обычно называются национальными. Национальный корпус русского языка (НКРЯ) содержит более 600 млн слов. В него входят тексты самых разных жанров, стилей и объема: современные письменные тексты (середина XX — начало XXI века), ранние тексты (середина XVIII — середина XX века), газетные тексты (корпус СМИ), параллельные корпуса (в них текст на русском языке сопровождается таким же текстом на иностранном), диалектные тексты, поэтические тексты, корпус устной речи, мультимедийный и акцентологические корпуса и другие.
Такой внушительный размер коллекции текстов позволяет изучать лексику и грамматику языка и их изменения. Но это не значит, что корпус нужен только лингвистам: его ценность как раз в том, что любой интересующийся родным языком человек легко сможет освоить поиск по корпусу и получить ответы на свои вопросы. Как сказала все в той же ветке комментариев старший преподаватель Школы Лингвистики НИУ ВШЭ Анна Левинзон: «Если есть у нас „национальное культурное достояние“, то НКРЯ — это оно».
Национальный корпус русского языка — это далеко не самое большое электронное собрание текстов на русском языке: сейчас есть корпуса текстов, скачанных из интернета, которые в десятки раз объёмнее (Генеральный интернет-корпус русского языка, Araneum Russicum, ruTenTen, Taiga). Но НКРЯ отличается очень удобным интерфейсом и качественной метаразметкой, то есть информацией о том, кем, когда и где был написан текст. Это делает Национальный корпус отличным инструментом для самого широкого круга пользователей — не только для лингвистов, но и для учителей и вообще всех, кто интересуется вопросами типа «А когда такое-то слово начало употребляться в русском языке?» или «А говорили ли так известные писатели?».
Для нашей литературоцентричной культуры НКРЯ хорош ещё и тем, что в нём собраны почти все значимые произведения русской классической литературы (корпуса других языков обычно так не устроены), а кроме того, в его составе имеется отдельный поэтический корпус.
Александр Чедович Пиперски, лингвист, кандидат филологических наук, научный сотрудник и старший преподаватель факультета гуманитарных наук НИУ ВШЭ, доцент УНЦ компьютерной лингвистики РГГУ
НКРЯ представляет особую ценность для зарубежных исследователей русского языка и тех, кто просто изучает русский. Русистика — не самая популярная дисциплина в мировых университетах, и сложности с доступом к НКРЯ (или вовсе его отсутствие) губительно скажутся на исследованиях русского языка за пределами России, а значит, и в целом на популярности русского языка в мире.
Так закрывают или нет?
В комментариях к посту Лоры Янды директор по распространению технологий Яндекса Григорий Бакунов (известный старожилам Рунета как bobuk) заявил, что компания не намерена закрывать проект. Разработчики опубликовали обращение к пользователям, где объяснили ошибки переходом корпуса на новую технологию поиска. В обращении упомянуты важные функции, которые перестали работать или работают ограниченно.
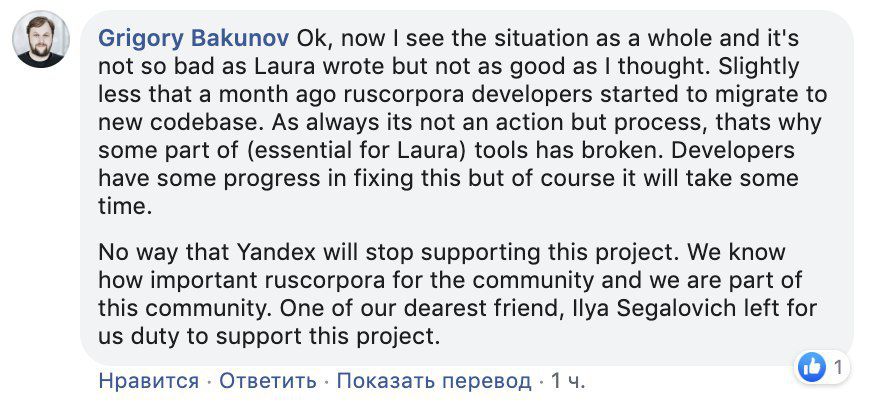
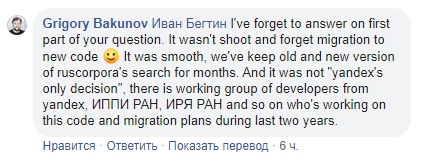
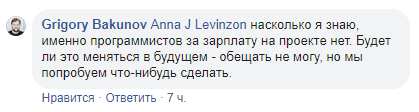
Разгорелась дискуссия между Иваном Бегтиным и Григорием Бакуновым. По мнению Ивана, данные и исходный код проекта должны стать открытыми. В ответ на это представитель Яндекса заявил, что выложить код в open source сейчас невозможно, поскольку проект содержит большое количество внутренних инструментов, открывать которые Яндекс не готов. Бегтин задумался о необходимости публичной кампании:
Наконец, через две с половиной недели появился комментарий от самого НКРЯ:
Дорогие коллеги,
мы всегда знали, что Корпус уникальный и очень нужный ресурс, и мы рады,
что вы поддерживаете Корпус и готовы помогать ему стать лучше. Благодаря обсуждениям последних нескольких дней мы узнали много важного и нового, в том числе о критических ошибках и сбоях, о которых ранее пользователи не сообщали. Мы приносим вам свои извинения за все неудобства, связанные с переходом на новую версию.
Сегодня снова стала доступна предыдущая версия, где можно пользоваться и старым, и новым поиском. Это временная мера, и мы будем продолжать работу над тем, чтобы переход на новую более современную и надежную технологическую платформу произошел и улучшил работу Корпуса. По возможности, пользуйтесь новой версией и помогайте нам тестировать ее.
Мы будем признательны, если вы будете сообщать об ошибках через форму
обратной связи на сайте или по адресу [email protected]. В сообщении
просим вас указывать, о какой функции идет речь, как и для чего вы ей
пользуетесь, и прикладывать скриншот/фотографию/видео того, что работает не так. Это нужно для того, чтобы воспроизвести ошибку и разобраться в причинах ее возникновения.
Мы рады вашим письмам о том, как важен Корпус в вашей работе, но призывы спасать его писать не стоит, потому что Корпус вне опасности.
Пользуясь случаем, напомним, что НКРЯ является партнерством, в котором
участвуют Яндекс, Институт русского языка РАН и Институт проблем передачи информации РАН. Все решения об изменениях в работе Корпуса принимаются участниками партнерства коллегиально и обсуждаются на заседаниях рабочей группы. Мы будем регулярно публиковать сообщения об обновлениях и держать вас в курсе.
С уважением,
представители Яндекса в НКРЯ
Светлана Бочавер,
Анна Булгакова
Почему национальный академический проект вообще связан с коммерческой компанией?
Для всех желающих Корпус доступен с 29 апреля 2004 года, но его открытию предшествовали годы серьезной подготовки. Еще в 1980-е годы первые отечественные корпусные лингвисты задались вопросом, каким должен быть «машинный фонд» русского языка. Тогда для создания корпуса не хватало технических и организационных возможностей, а в 2000 году лингвисты, математики и программисты объединили свои силы. У истоков НКРЯ стояли В.А. Плунгян, Д.В. Сичинава, М.А. Даниэль, И.С.Красильщик, С.К.Ландо, С.А.Шаров, Е.В. Рахилина и многие другие. Все началось в Центре лингвистической документации (кружок московских лингвистов на базе МЦНМО); РАН и ОТиПЛ МГУ тоже работали над Корпусом. А программно-техническую и финансовую поддержку НКРЯ оказала компания Яндекс.

Техническим директором Яндекса тогда был Илья Валентинович Сегалович, именно благодаря его инициативе поисковик начал работать над корпусом. Компания была заинтересована в корпусе, как в важном ресурсе для совершенствования систем автоматической обработки текста. И.В. Сегалович, В. А. Титов и другие сотрудники Яндекса предоставили корпусу поисковый модуль Яндекс.Сервер, системы снятия омонимии и морфологического разбора. [2][3] И до сих пор на странице Яндекса, где рассказывается о том, как работает поиск и встроенная в него система морфологического анализа, есть ссылка на НКРЯ:

Яндекс поддерживает ресурс, которым пользуются тысячи исследователей в России и за рубежом уже 15 лет. Участие крупнейшей российской IT-компании — без сомнения, мощная поддержка, но даже ее недостаточно, если появляются подобные проблемы. Национальный проект нуждается в охране и финансировании, чтобы развиваться дальше; остальным игрокам IT-рынка стоит присоединиться к сохранению важного ресурса.
Но все-таки коммерческие и академические проекты существуют в разных мирах: всегда остается опасность, что поддержка станет экономически невыгодной и будет прекращена. А у волонтеров даже не останется доступа к исходному коду, ведь это собственность компании! Поэтому управление такими ресурсами должно быть в руках сообщества — людей, которые лучше всего понимают их научную ценность и не измеряют ее в коммерческих KPI. В 2019 году это не просто «круто» — это очевидный путь развития.
Источники
[1] Laura Janda
[2] Национальный корпус русского языка: очерк предыстории
[3] Илья Сегалович и развитие идей компьютерной лингвистики в Яндексе
Что такое корпус
В. А. Плунгян Зачем мы делаем национальный корпус русского языка?