Большинство людей предпочитают визуализацию данных большим таблицам чисел. Поэтому визуализация также знакомит широкую аудиторию с результатами исследования в понятной для нее форме. Диаграммы или графики с содержательными интерпретациями обычно помещаются на видное место в научных публикациях.
В этой статье рассматриваем 10 способов визуализации данных:
Гистограммы
Столбчатые/Круговые диаграммы
Точечные/Линейные диаграммы
Временные ряды
Карты отношений
Тепловые карты
Географические карты
3-D (трехмерные) диаграммы
Многомерные диаграммы
Облака слов (или облака тегов)
Гистограммы
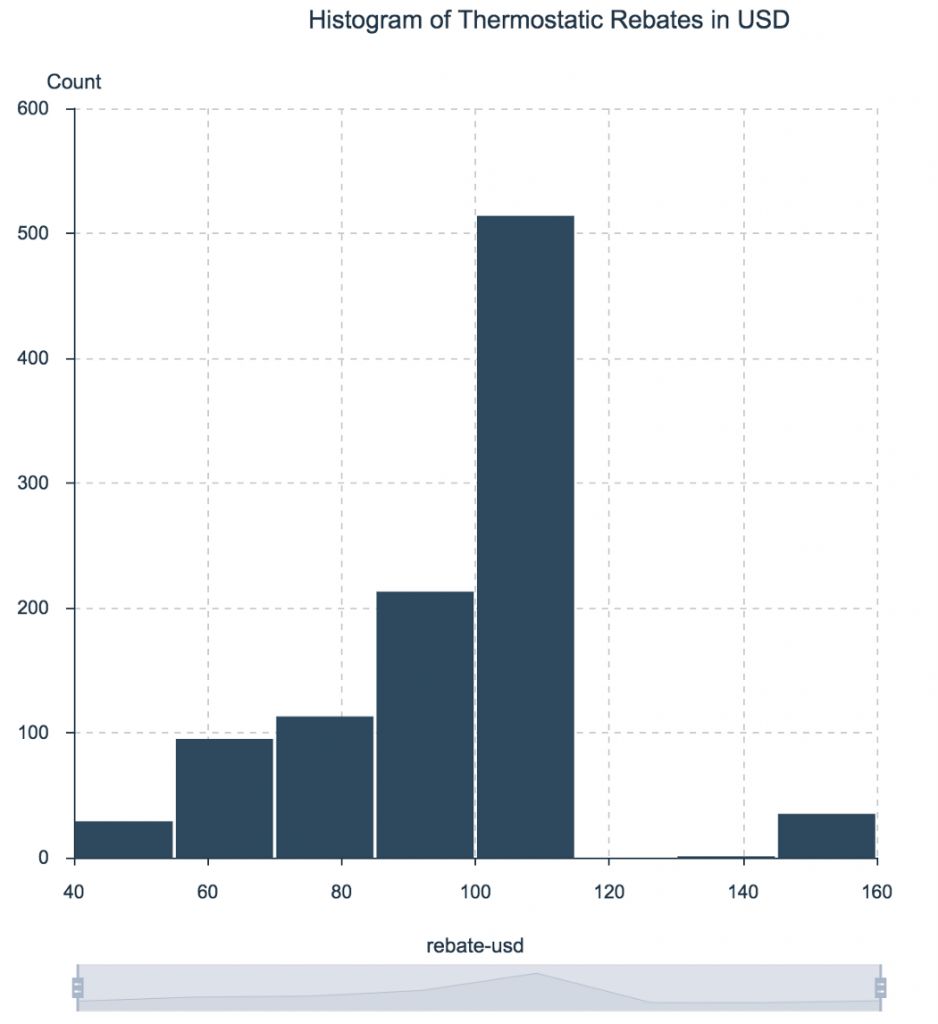
Гистограмма используется для визуализации значений, которые принимает числовая переменная. Гистограмма покажет диапазон ее значений, какие значения она принимает часто, а какие — редко.
Гистограмма работает следующим образом: диапазон значений переменной разбивается на несколько равных интервалов, которые откладываются на горизонтальной оси. По вертикальной оси отражается, сколько значений попадает в каждый из интервалов: чем больше значений попадает в интервал, тем выше столбик гистограммы.
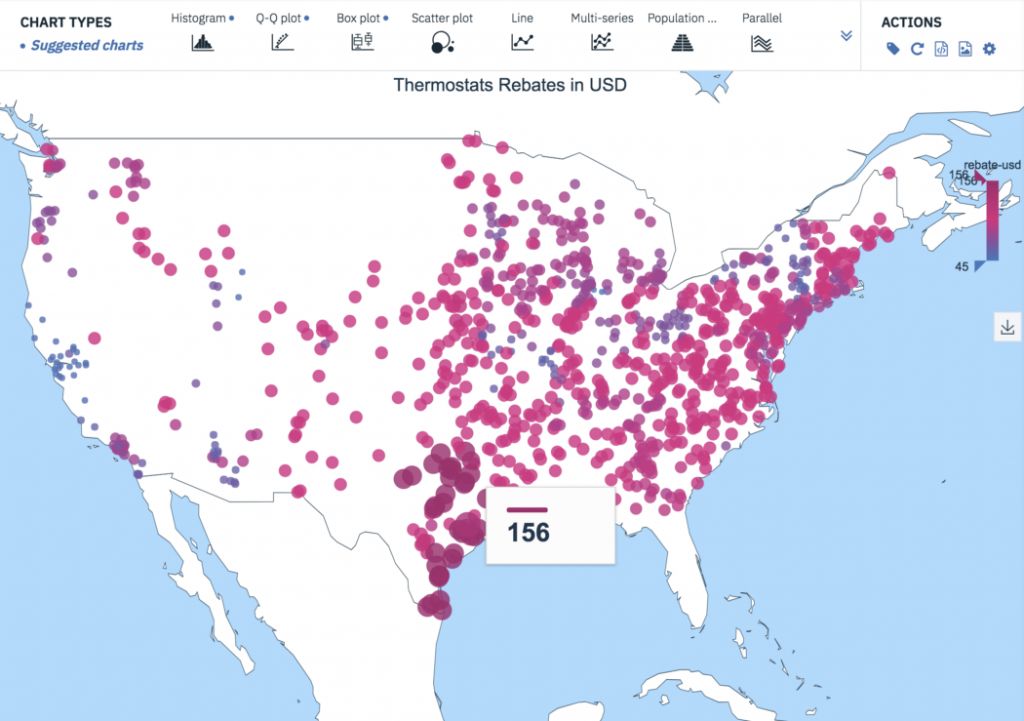
Представьте, что компания хочет повысить интерес покупателей к умным термостатам. При заказе термостатов покупатели получают скидки, размер которых зависит от их почтовой зоны. Гистограмма размера этих скидок помогает понять диапазон их величин (в долларах США), а также частотность каждого значения. Мы видим, что величина около половины скидок составляет от $100 до $120, тогда как всего несколько почтовых зон предусматривают скидки свыше $140 или менее $60.
Источник данных.
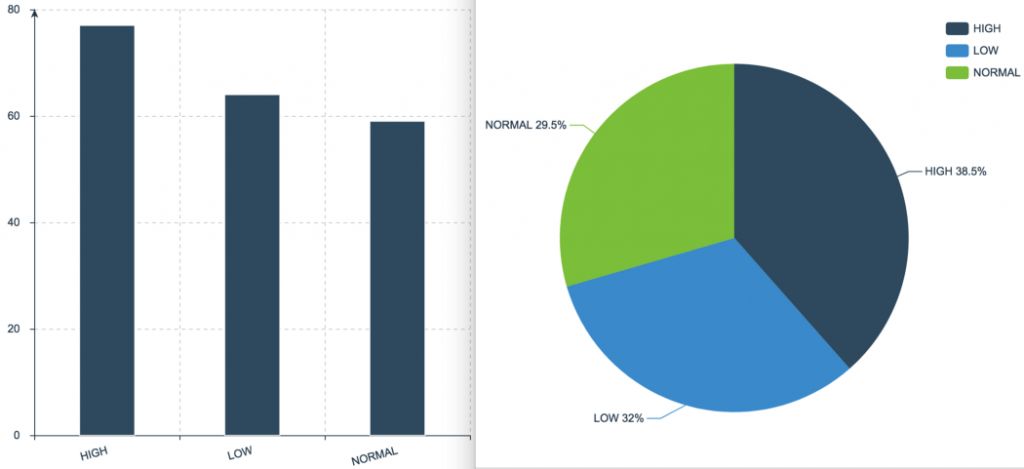
Столбчатые и круговые диаграммы
Вместо гистограмм используем столбчатые и круговые диаграммы, если работаем не с числовой, а с категориальной переменной, которая принимает фиксированное количество значений: низкий, нормальный или высокий; да или нет; обычный, электрический или гибридный, и так далее.
Чтобы выбрать между столбчатой и круговой диаграммой, стоит создать и ту, и другую, и посмотреть, какая будет лучше восприниматься. Круговые диаграммы больше подходят, когда переменная принимает небольшое количество разных значений.
Если категориальная переменная принимает слишком много различных значений, попробуйте визуализировать только N самых частотных из них, иначе визуализация будет перегруженной.
Ниже — примеры столбчатой и круговой диаграмм, которые иллюстрируют результаты измерения артериального давления у пациентов. Данные распределены на 3 категории: НИЗКОЕ, НОРМАЛЬНОЕ и ВЫСОКОЕ давление.
Источник данных
Точечные и линейные диаграммы
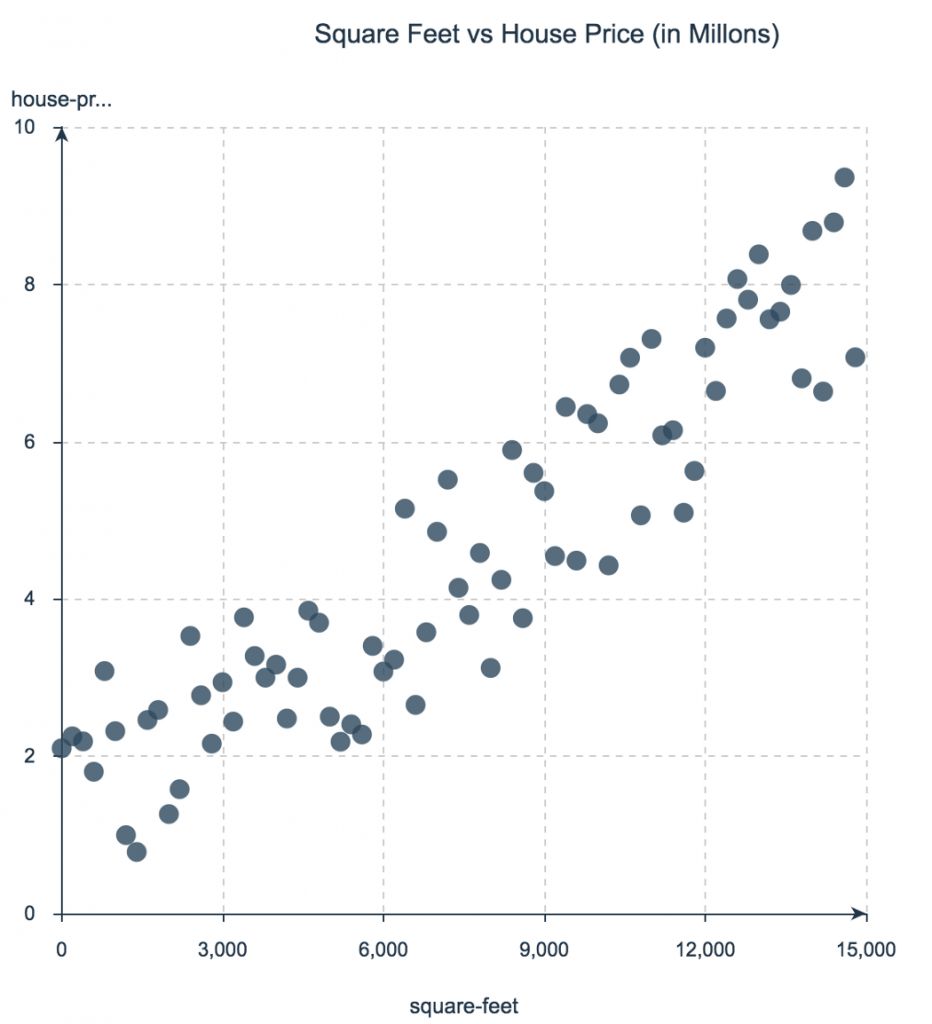
Точечные диаграммы, вероятно, самые простые среди диаграмм. Они отображают данные в двух измерениях в прямоугольной системе координат, позволяют своими глазами увидеть взаимосвязи между двумя переменными и изучить их.
Линейные диаграммы — это те же точечные диаграммы, у которых все точки соединены линией. Они часто используются, когда переменная у непрерывна.
Представьте, что вы хотите узнать, как соотносится площадь дома с его стоимостью. Ниже, на точечной диаграмме цены на жилье (в миллионах долларов) отложены по оси Y, а площадь (в фут2) — по оси X. Посмотрите, график указывает на, в некоторой степени, линейную зависимость между этими переменными. Грубо говоря, чем больше площадь, тем выше цена.
Если поиграть с цветом и/или размером точек, то можно увеличить количество измерений до 3 или 4. Например, можно добавить третье измерение, если раскрасить точки в разные цвета по количеству спален в каждом доме.
Временные ряды
Временные ряды — это разновидность точечной диаграммы, у которой по оси X всегда откладывается время. Время непрерывно, поэтому диаграмма получается линейной.
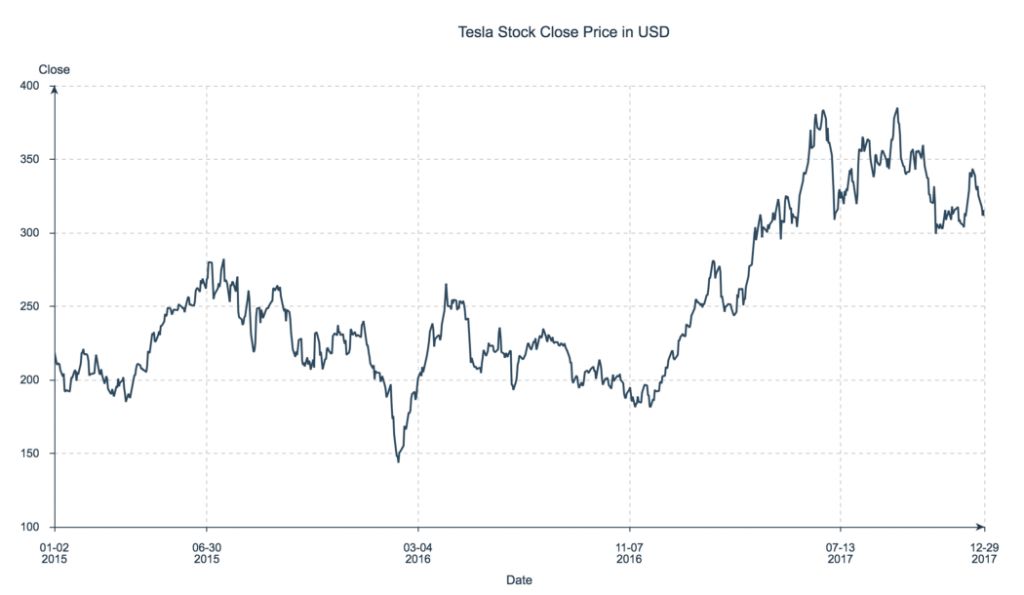
Временные ряды отлично подходят, чтобы исследовать, как изменялись значения переменной в определенный период времени. Можно узнать общее направление развития, обнаружить резкие изменения (скачки) и определить наибольшие и наименьшие значения. Поэтому временные ряды особенно популярны при визуализации финансовых данных и данных различных датчиков.
На графике ниже по оси Y отложен курс акций Tesla на момент закрытия биржи. Временной промежуток — с 2015 по 2017 год.
Диаграммы отношений
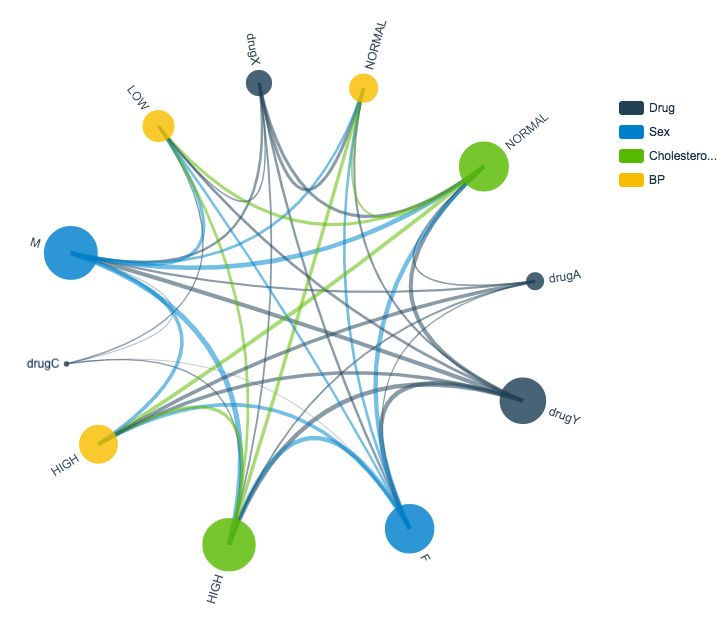
Если ваша цель — разработать всеобъемлющую гипотезу, то визуально представить взаимосвязи между данными особенно полезно. Представьте, что вы — сотрудник медицинской компании. Вы работаете над проектом, цель которого — помочь врачам быстрее назначать лечение. Предположим, есть четыре лекарства (A, C, X и Y), и врачи назначают каждому пациенту только один препарат. В базе данных собраны врачебные назначения пациентам в зависимости от их пола, артериального давления и уровня холестерина.
Как интерпретировать диаграммы отношений? Каждая категория обозначена своим цветом (на диаграмме и в легенде). Толщина линий на диаграмме показывает, насколько важна (частотна) связь между конкретными значениями переменных.
Диаграмма отношений назначения лекарств позволяет сделать следующие выводы:
— препарат А прописывали только пациентам с высоким давлением;
— препарат С прописывали только пациентам с низким давлением и высоким уровнем холестерина;
— препарат Х не прописывали ни одному пациенту с высоким давлением.
По этим данным можно сформулировать ряд гипотез и начать исследования в новых областях. Например, нейросеть после обучения с учителем может точно прогнозировать назначение препаратов А, С и, возможно, Х. Тогда как препарат Y назначался при всех возможных характеристиках, поэтому, чтобы начать делать прогнозы, нужно учитывать дополнительные характеристики.
Тепловые карты
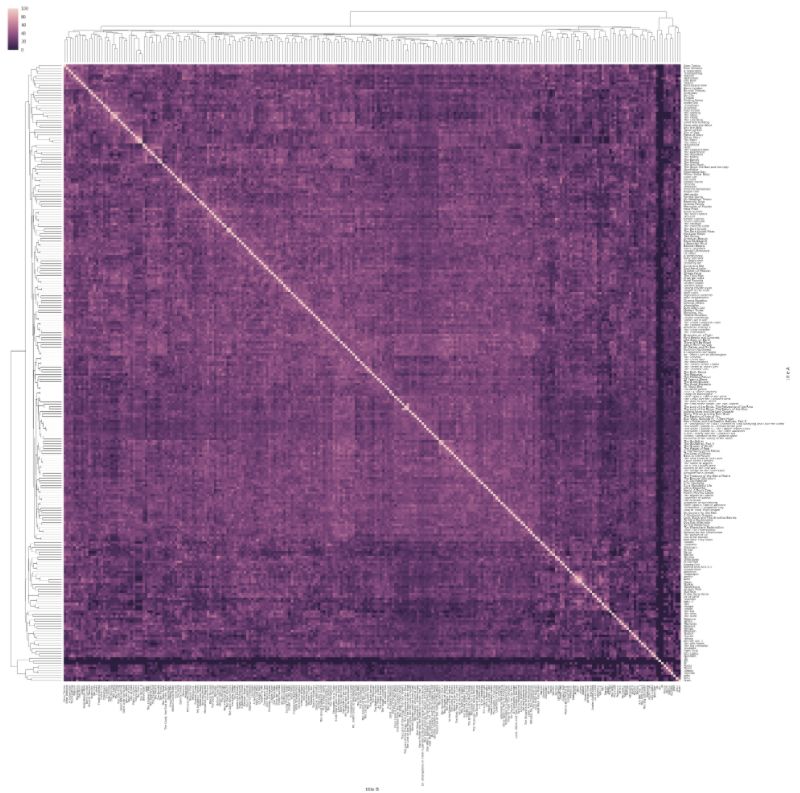
Тепловые карты — это еще один интересный и красочный способ отображения дополнительного измерения на 2D графике. Вся таблица или карта закрашивается цветами разных оттенков, а интенсивность цвета может выделять частотность или выявлять тенденции и зоны повышенного интереса. Большинство пользователей считают, что тепловые карты интуитивно понятны.
Ниже визуализированы расстояния Левенштейна между названиями фильмов в базе данных IMDB. Расстояние Левенштейна — это минимальное количество операций (вставки, удаления или замены одного символа), необходимых для превращения одной строки в другую. Чем больше операций нужно совершить, тем дальше название фильма от других названий, и тем темнее оно отображается в таблице. Например, «Супермен» далек от «Бэтмена навсегда», но близок к «Супермену 2».
Эта визуализация создана Майклом Заргхамом¹.
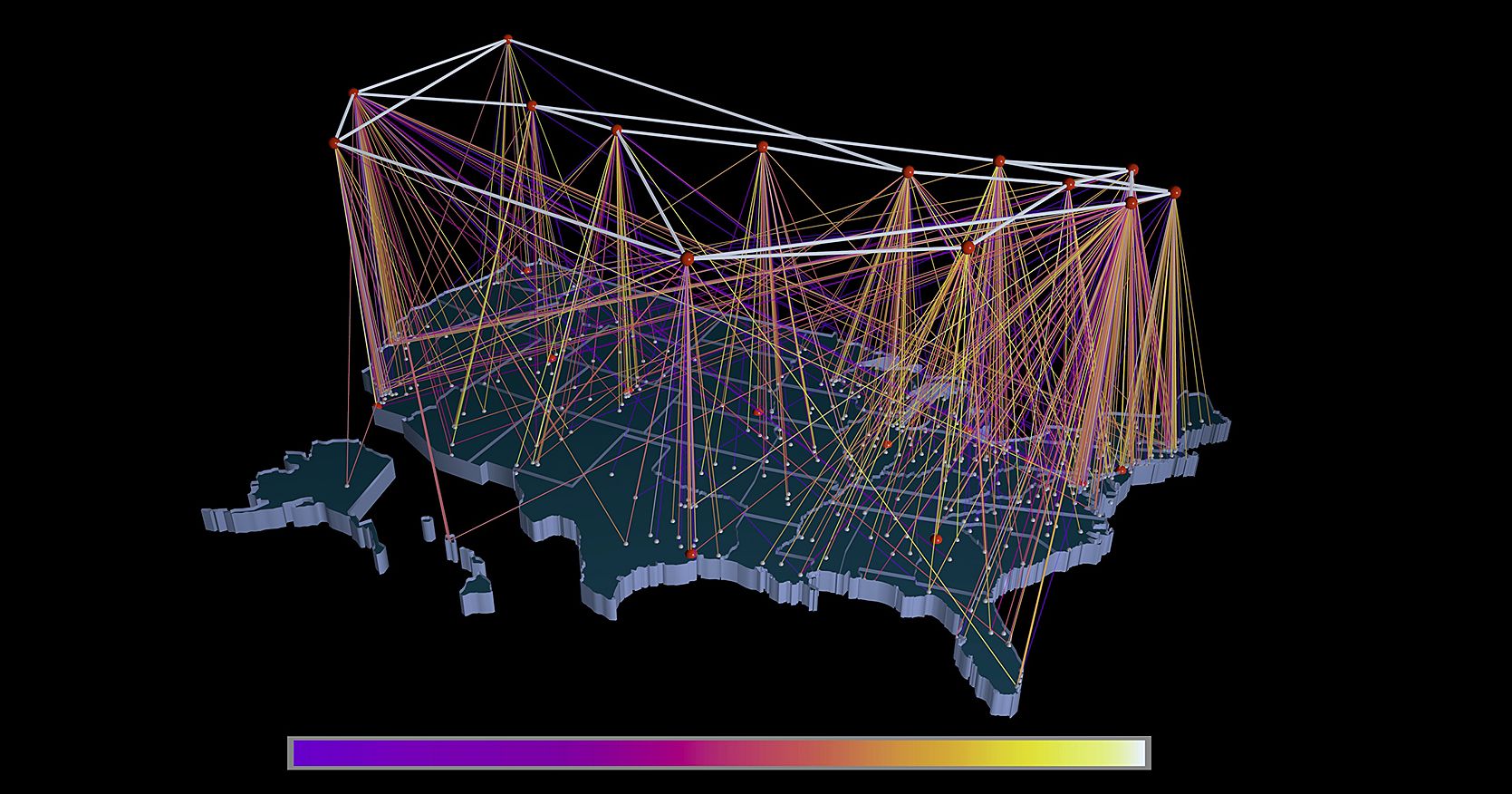
Географические карты
Если данные географически организованы (известны долгота и широта, почтовый индексов или данные аэропортов и т.д.), то карты могут обогатить вашу визуализацию.
Рассмотрим пример со скидками на покупку термостата из раздела Гистограммы. Напомним, что размер скидки зависит от региона. Поскольку известны долгота и широта, мы можем отобразить данные на карте. Назначаем цветовой спектр — от синего цвета для наименьшей компенсации до красного для наибольшей компенсации — и помещаем данные на карту штатов:
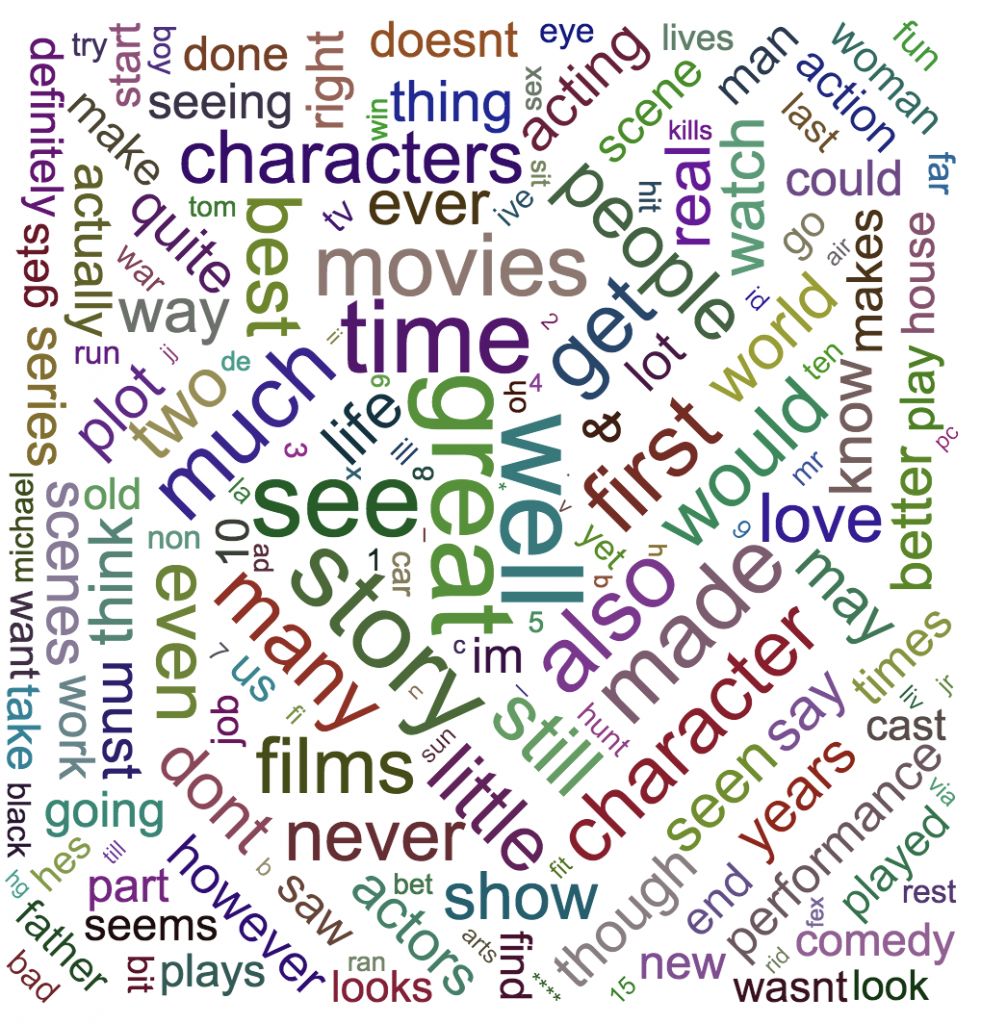
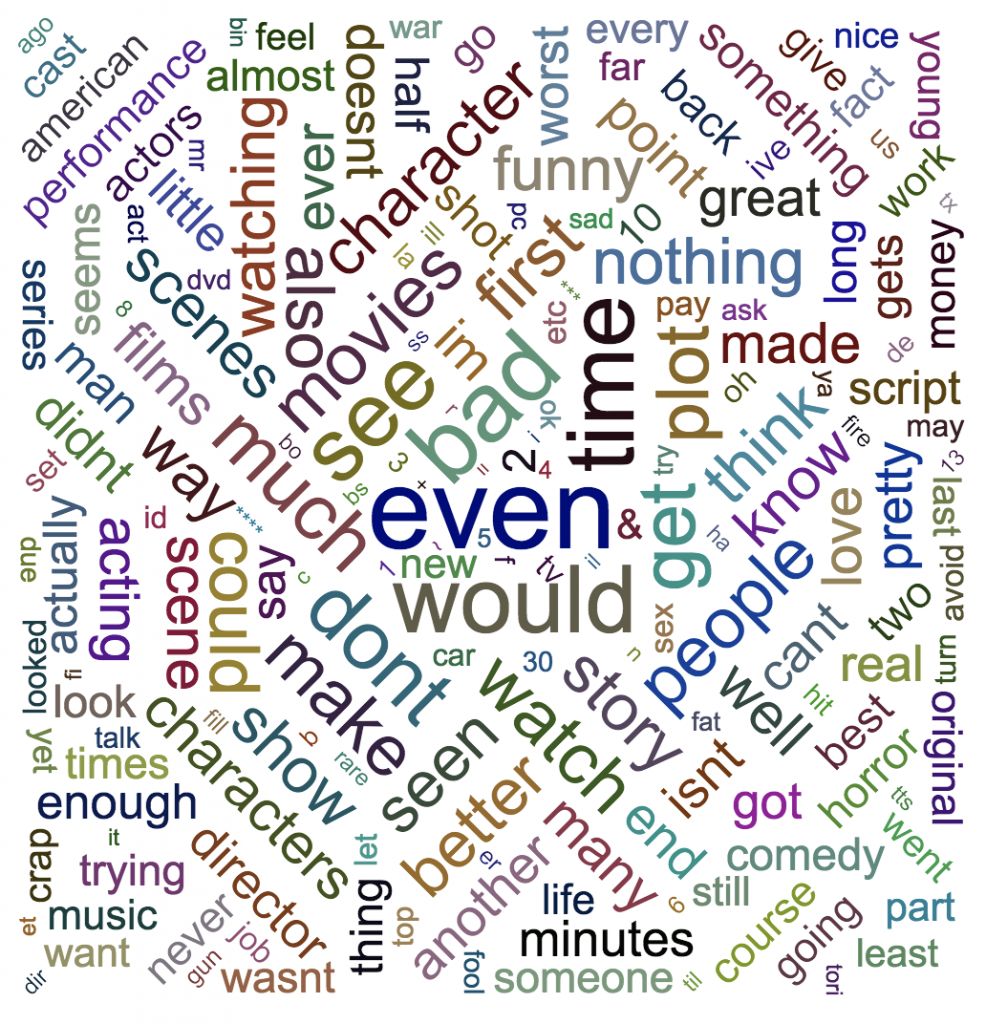
Облака слов (или облака тегов)
Огромное количество информации доступно для изучения только в форме не размеченных текстов на естественном языке. В начале работы с данными такого формата мы, возможно, захотим узнать, какие слова встречаются в корпусе чаще всего. Как было сказано выше, если мы имеем дело с цифрами, то для определения частотности лучше всего нам подходят гистограммы. Однако для визуализации текстовых данных лучше работают облака слов (иногда их еще называют облаками тегов).
Работу с такими текстами можно начать с удаления стоп-слов типа «и», «а», «но» и «как». Также надо привести все символы текста к одному стандарту — нижнему регистру. В зависимости от ваших целей часто нужно дополнительно почистить и организовать данные: удалить диакритические знаки, выделить основы слов и так далее. Когда данные будут готовы, облако слов наглядно расскажет вам, какие слова встречаются в корпусе чаще всего.
В нашем случае был использован корпус рецензий на фильмы². Получилось по облаку слов для положительных и для отрицательных отзывов:
3D (трехмерные) диаграммы
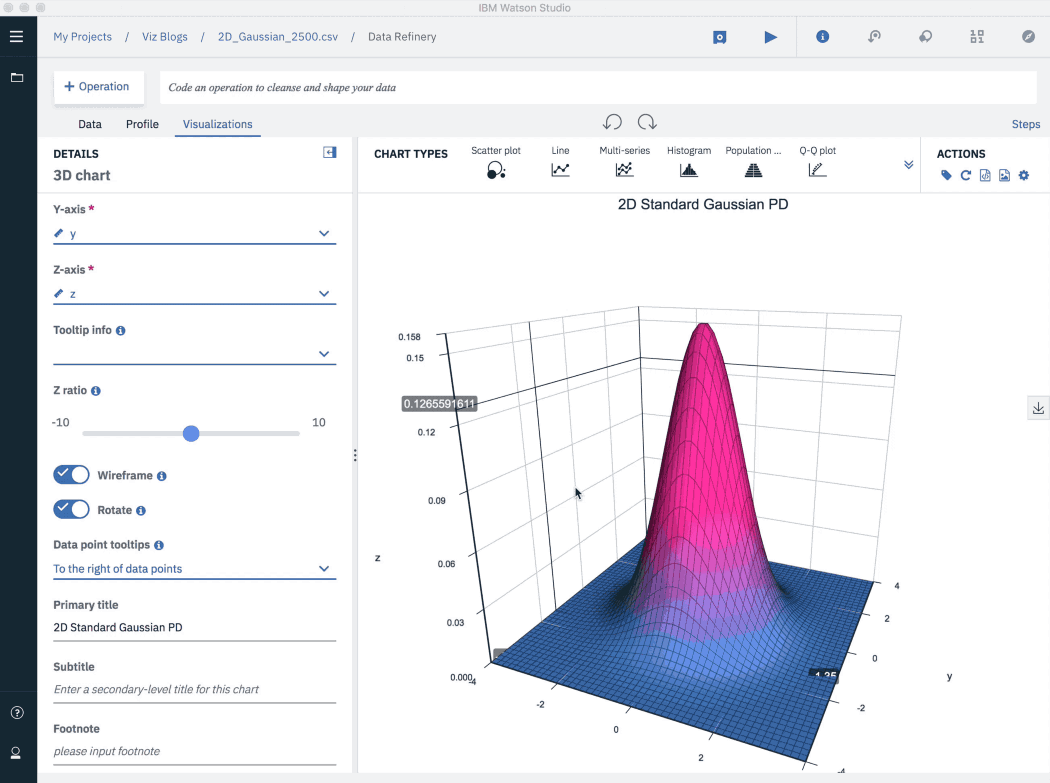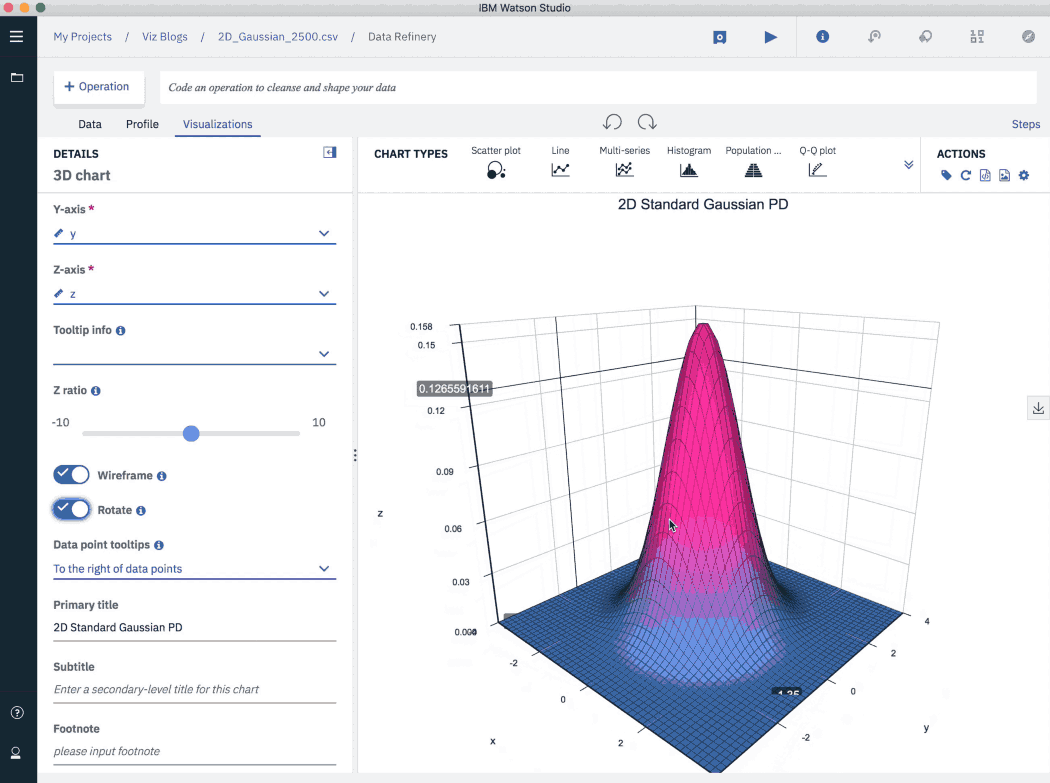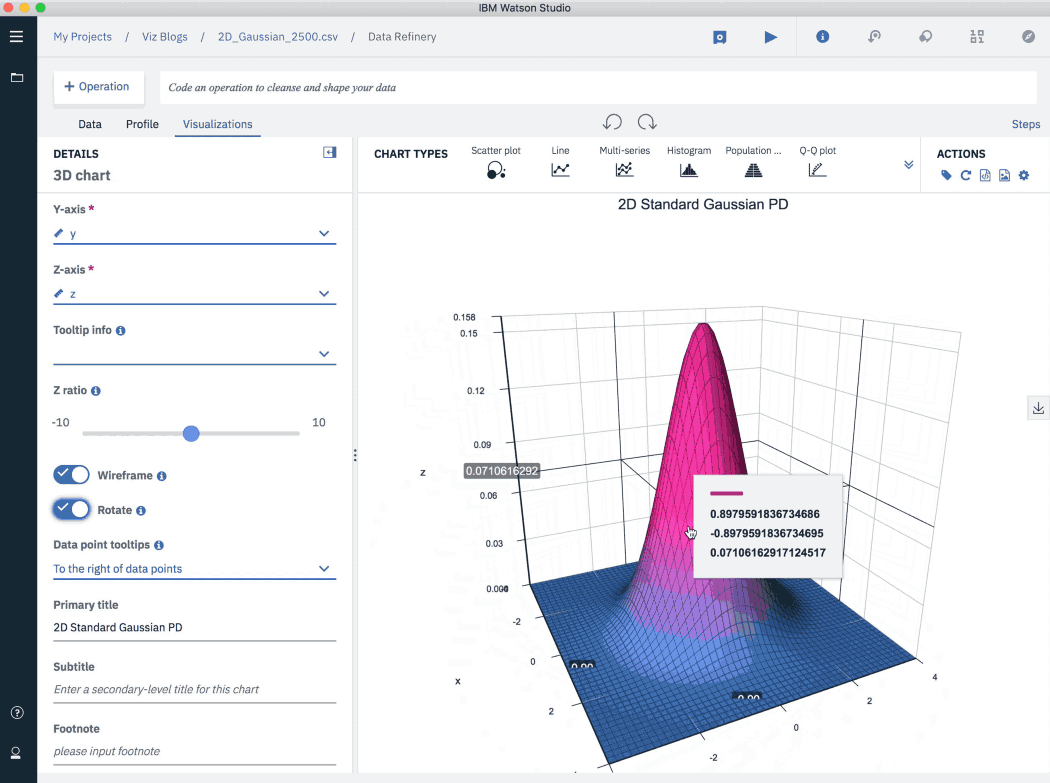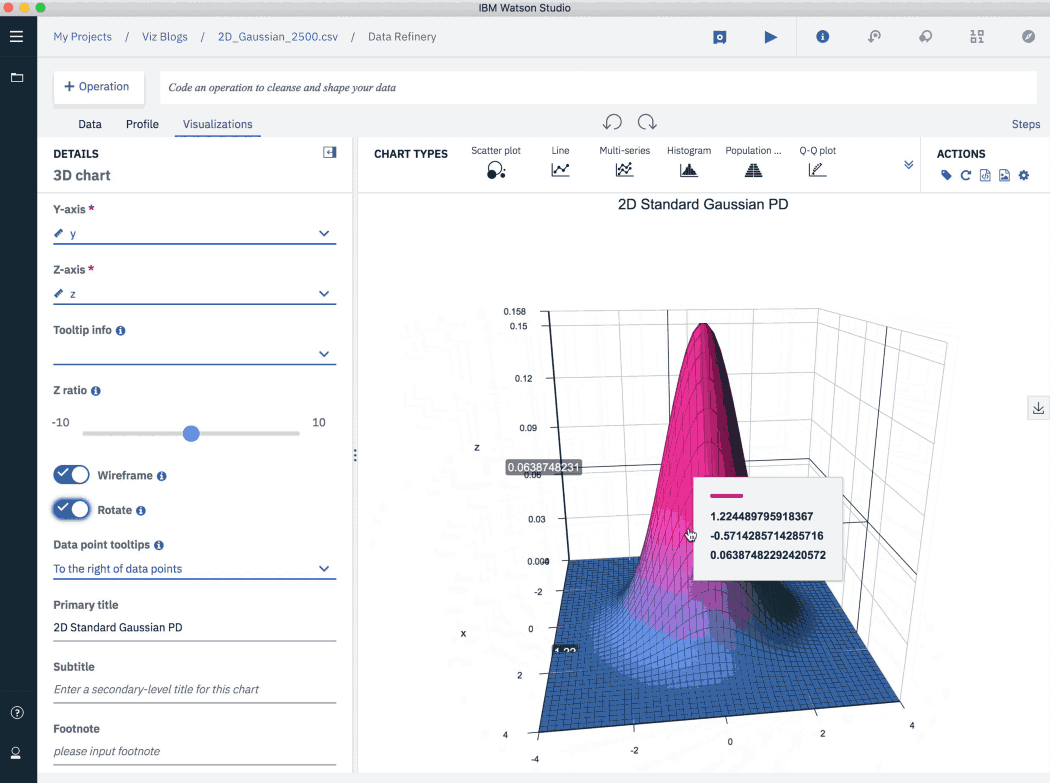
В точечные диаграммы все чаще и чаще добавляют третье измерение. Так у пользователя появляются новые возможности: теперь он может вращать диаграмму, а также изменять ее масштаб. Таким образом, график становится более интерактивным, и пользователь получает более полное представление о данных.
В примере ниже визуализирована двухпараметрическая функция плотности вероятности (или функция Гаусса). Обратите внимание на панель управления диаграммой и доступные настройки ее представления.
Многомерные диаграммы
Если у данных много параметров, мы можем захотеть визуализировать взаимовлияние четырех, пяти или более функций одновременно. Для этого мы можем сначала создать двух- или трехмерную диаграмму — любым способом, упомянутым ранее.
Например, представьте, что вы хотите добавить третье измерение в нашу карту скидок на покупку термостата. Вы превращаете каждую точку в вертикальную линию, которая указывает среднее потребление энергии для этого местоположения. Это дает вам визуализацию четырех измерений: долготы, широты, величины компенсации и среднего потребления энергии.
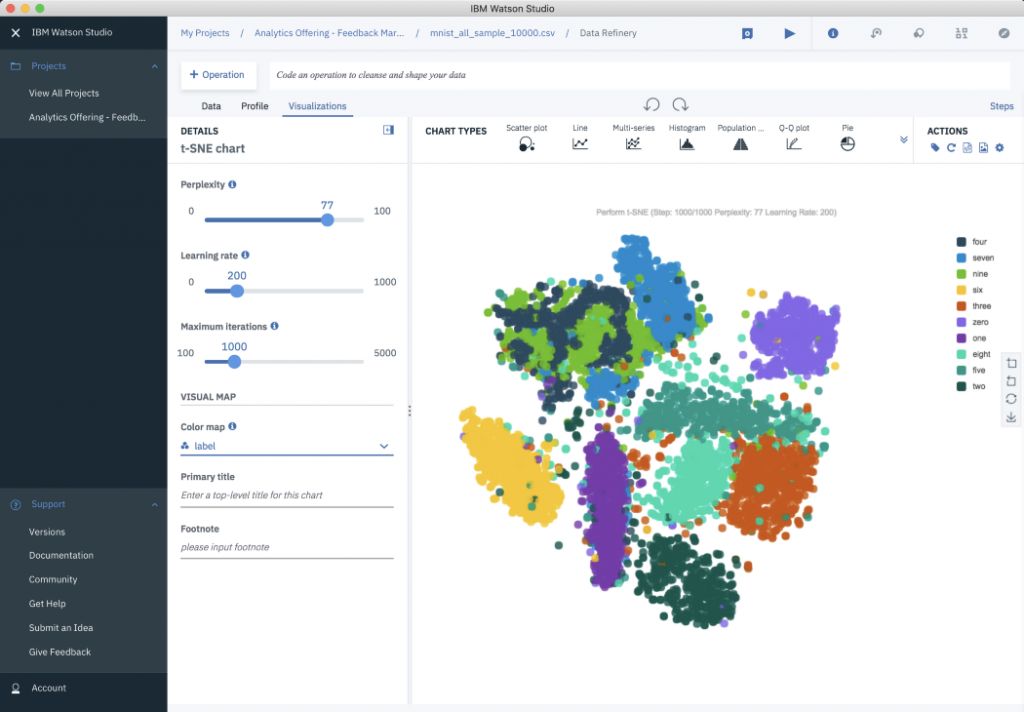
При работе с многомерными данными для визуализации нам часто необходимо их размерность сократить. Для этого мы можем использовать следующие методы: метод главных компонент или стохастическое вложение соседей с t-распределением (t-SNE).
Метод главных компонент — самый популярный, линейный. Он уменьшает размерность данных посредством нахождения новых векторов, которые максимизируют линейное изменение данных. Когда линейные корреляции данных сильны, метод главных компонент может значительно уменьшить размерность данных почти без потери информации.
А t-SNE — это нелинейный метод. Он уменьшает размерность данных, сохраняя при этом расстояние между параметрам точек в исходном многомерном пространстве.
Давайте рассмотрим пример из базы данных рукописных цифр MNIST. Эта база данных содержит тысячи изображений цифр от 0 до 9, которые используются исследователями для тестирования своих алгоритмов кластеризации и классификации. Размер этих изображений составляет 28×28 = 784 пикселя, но с помощью t-SNE мы можем уменьшить эти 784 измерения всего до двух:
Итак, мы рассмотрели десять наиболее распространенных способов визуализации данных. Каждый способ был проиллюстрирован примером. Все визуализации были сделаны с помощью Watson Studio Desktop. Кроме Watson Studio Desktop, обязательно стоит обратить внимание на такие инструменты, как R, Matplotlib, Seaborn, ggplot, Bokeh, plot.Ly и другие.
Источник: 10 Visualizations Every Data Scientist Should Know

