Национальный корпус русского языка (НКРЯ) — важнейший инструмент любого исследователя, который занимается русским языком, русской литературой и вообще русской словесной культурой. Изменения в работе НКРЯ были заметны ещё в 2019 году: тогда лингвисты высказали опасения о возможном закрытии сервиса. К счастью, проблемы оказались временными, и НКРЯ не только не прекратил свою работу, но и заметно изменился и расширился. Самым заметным обновлением стал новый дизайн сайта, но есть и много глубоких содержательных перемен. Об основных обновлениях в корпусе, очевидных и не очень — в нашем сегодняшнем материале.
Иллюстрация: Женя Родикова
Невозможно представить себе корпус без текстов. За последние пару лет в НКРЯ не только появились новые коллекции, делающие его еще более репрезентативным, но и целые новые корпуса.
Один из наиболее важных новых корпусов — панхронический. Как можно догадаться из названия, в корпусе присутствуют тексты разных периодов времени, от средневековых до современных. Чтобы подготовить его, лингвисты и разработчики объединили данные трех исторических корпусов — древнерусского, старорусского и корпуса берестяных грамот — и основного корпуса.
Это делает возможным составлять запросы, релевантные для нескольких веков развития русского языка. Грамматические признаки в новом корпусе унифицированы для всех корпусов, а искать можно по любой из форм слова: нормализованной раннедревнерусской (сълати), позднедревнерусской/старорусской (слати) или в современном русском облике (слать).
Пример запроса:
Имена собственные на -славъ:
Ссылка: https://ruscorpora.ru/s/epoQd
Пример из XI века:
Пример из XXI века
Произведения русских классических писателей, разумеется, присутствовали в корпусе и ранее. Тем не менее, добавление полных собраний сочинений в основной корпус могло бы негативно повлиять на сбалансированность корпуса. В собраниях сочинений тексты, в том числе и весьма объемные, очень часто печатаются в нескольких вариантах: так заинтересованный читатель может проследить, как менялся текст от первоначальной правки к изданию. Однако для сбалансированного корпуса такие повторы становятся ненужным дублированием данных.
Новый корпус «Русская классика» позволяет максимально полно представить наследие русской классики без каких-либо ограничений: например, включить даже черновики и редакционные варианты произведений.
Пример запроса:
Поиск оборота «она немедленно же» показывает, что он действительно характерен только для произведений Лескова
Ссылка: https://ruscorpora.ru/s/bWyge
Чтобы создать корпус детской литературы «От 2 до 15», был проведен масштабный опрос среди детей, подростков и их родителей. В ходе опроса авторы собрали информацию о самых популярных произведениях среди детей разных возрастов. Для каждого произведения была проведена разметка с помощью нейросетевых технологий: книги были разбиты на фрагменты, и для каждого фрагмента был предсказан возраст, в котором будет понятен этот текст.
В корпус вошли 75 наиболее популярных прозаических произведений зарубежных и отечественных авторов.
Пример запроса:
Можно, например, изучить несловарные формы в книгах о Гарри Поттере — в примеры из выдачи вошли не только имена собственные, но и специфичные для книг понятия, например, квиддич или зельеварение.
Ссылка на запрос: https://ruscorpora.ru/s/bDjBe
Корпус записей из блогов и социальных сетей появился совсем недавно (пришлось дополнять статью в процессе работы над ней :)) и явно будет очень активно развиваться: например, разработчики планируют ввести разметку эмоджи и поиск по ним 🤯
Уже сейчас можно исследовать диалоговую природу текстов: смотреть как на сами записи, так и на комментарии к ним.
И, конечно же, материал блогов и социальных сетей серьёзно отличается от текстов других корпусов.
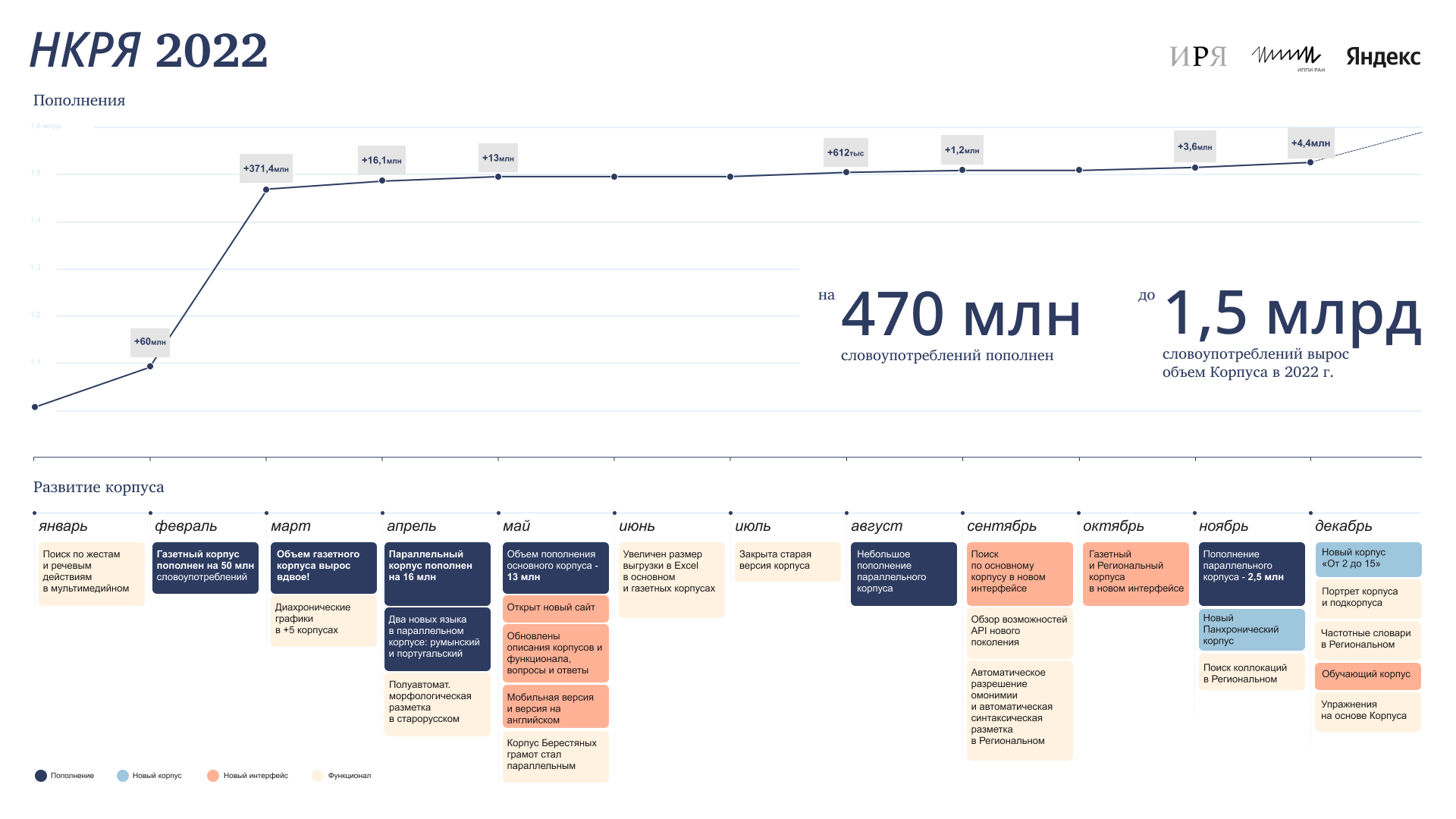
Кроме того, были существенно дополнены и расширены и другие корпуса: в 2022 году объем НКРЯ вырос на 470 млн словоупотреблений и сейчас достигает более 1,5 миллиардов. Появились и новые параллельные корпуса: например, румынский и португальский.
Другим направлением по развитию корпуса стало внедрение новых функций, как в поиске, так и в описании корпусов.
Для того, чтобы качественно оценивать статистические метрики в НКРЯ, а значит, внедрять большую часть нового функционала, нужно было решить проблемы неснятой морфологической омонимии. Например, слово «пирога» может быть и родительным падежом от «пирог», и именительным от лодки «пирога».
Раньше корпус делился на «снятник» и «неснятник» — для относительно небольшой части текстов основного корпуса омонимия была снята вручную. Но за последние годы нейросети научились разрешать омонимию настолько хорошо, что стало возможным сделать это для всего корпуса. С помощью нейросетевой программы РуБик морфологическая разметка была улучшена и обновлена.
Сейчас версии с омонимией, снятой РуБиком, доступны для основного корпуса и корпуса региональных СМИ.
Ранее в НКРЯ были доступны два основных вида поиска: поиск точной формы слова и лексико-грамматический поиск. В первом случае пользователь получал в выдаче только те примеры, в которых слово встречалось в форме, заданной в запросе. В лексико-грамматическом поиске можно было искать слово по лемме (начальной форме слова, например, по слову «кот» в выдаче попадались «коты», «котом» или «коту»), а также задавать грамматические, семантические и другие признаки (например, падеж или число для существительного, время или лицо для глагола).
Поиск коллокаций отличается от других видов поиска тем, что помимо употреблений интересующего пользователя слова ищутся также слова, с которыми оно часто встречается вместе.
Например, со словом «блок» часто встречаются такие прилагательные, как «избирательный» или «прогрессивный», а «системный» даже не попал в первую десятку.
Ссылка на запрос: https://ruscorpora.ru/s/eEkNb
Частотность, таблицу которой мы показали вам выше — ещё одна новая функция. Теперь в выдаче можно найти не только список примеров (отрывками из текста или конкордансом), но и информацию о наиболее частотных употреблениях форм слова или словосочетаний.
Например, форма «дождичка» достаточно популярна для слова «дождичек» — сказывается популярность идиомы «после дождичка в четверг».
Ссылка на запрос: https://ruscorpora.ru/s/dGmya
Кроме изменений в поиске и выдаче, дополнены и описания самих корпусов. Теперь пользователь может, нажав на кнопку «Об этом корпусе», получить основную информацию: описание корпуса и его особенностей, частотный словарь корпуса и статистику.
В описании указан состав корпуса, описание его разметки — морфологической и метатекстовой, а также релевантные публикации.
Описание на примере древнерусского корпуса
500 самых частотных лемм корпуса — чаще всего это служебные слова.
Частотный словарь для основного корпуса:
Показаны статистические характеристики корпуса: можно посмотреть, например, на распределение текстов по метаатрибутам.
Статистика корпуса на примере основного:
В портрете подкорпуса содержатся те же функции, что и в портрете корпуса, но теперь они сравниваются с исходным корпусом.
Например, посмотрим на разницу между полным вариантом основного корпуса и его подкорпуса, отобранного с признаками «художественные тексты, место и время действия — ирреальный мир». В этом примере слова отсортированы по изменению ранга: так, чтобы видеть значимые лексические отличия.
Слова, которые заметно чаще встречаются в художественных текстах, чем во всем корпусе:
А ещё, например, в подкорпусе одновременно больше доля текстов, где автор — мужчина, и текстов, где автор — женщина: кажется неинтуитивным, но дело в том, что для всего корпуса больше доля текстов, где автор неизвестен.
Инструмент для тех, кто хочет собрать всю информацию об интересующем их слове.
Такой функционал уже был ранее в других национальных корпусах, теперь же исследовать слова можно и на материале русского языка.
В портрете слова есть:
Слова, похожие на «чипсы»:
До 1960-х чипсов не существовало (по крайней мере, в русскоязычных текстах в НКРЯ):
А в 1960-х появились в журнале «Химия и жизнь»:
Отдельно отметим, что этот материал охватывает многие из изменений, но всё же не претендует на то, чтобы быть исчерпывающим.
Во-первых, часть из этих изменений могут быть достаточно специальными или не слишком заметными рядовому пользователю: например, появление автоматической синтаксической разметки в региональном корпусе или увеличение размера выгрузки (документа с примерами, который пользователь может скачать на своё устройство).И во-вторых, в самом Национальном корпусе русского языка освещаются все значительные изменения в корпусе. Про все основные новости можно прочесть здесь, а разобраться с тем, как работать с корпусом, если вы новичок — здесь. Документация корпуса, как и сам портал, тоже развивается постоянно 🙂
США усилили контроль над лидирующими ИИ моделями, ученые смогли полностью прочитать античный свиток, не разворачивая его — что произошло в…
Агенты, которые самостоятельно планируют свои действия и пользуются внешними инструментами. Модели, способные работать с миллионами токенов. Системы, которые помогают сохранять…
Теперь в него входят тексты ВКонтакте — почти 11,3 млрд слов из соцсетей
{kind=link}