Кто ещё не слышал про компьютерную лингвистику, обязательно про нее услышит. Перспективное направление на стыке лингвистики и computer science даёт голос и подобие разума чатботам, голосовым помощникам и всем возможным диалоговым системам. Но только интуитивно понятное название «компьютерная лингвистика» не совсем точно отражает что происходит с языком в цифровом представлении.
Компьютерная лингвистика зародились в США в 50 годах прошлого века, и получило название «computational linguistics», что буквально означает «вычислительная лингвистика». Изначальной целью была автоматизация перевода, позже к ней присоединились задачи создания корпусов, извлечения информации, создания вопросно-ответных систем, оптическое распознавание символов (OCR) и некоторые другие — все это может быть обобщено до «научить компьютеры распознавать и генерировать речь». Но «мышление» компьютера совершенно отличается от мышления человека. Человеческое мышление основано на языке, а компьютер — это невероятно сложный калькулятор, чье «мышление» (или его имитация) базируется на математических операциях. Таким образом основной проблемой вычислительной лингвистики стало построение математической модели, способной максимально точно отразить живой человеческий язык.
До сих пор не существует идеальной модели или совершенного подхода к решению этой задачи. Зато существует целый набор математических инструментов, с помощью которых она может быть решена с переменным успехом.
Логика
Одним из способов моделирования значений предложений является логика — инструмент выражения отношений между элементами. Например, человеческое «I only have five dollars and I don’t have a lot of time» в логическом машинном представлении выглядит как: Have(Speaker,FiveDollars)∧¬Have(Speaker,LotOf Time), где Have является предикатом, выражающим отношение Have (отношение владения) между двумя переменными: Speaker и FiveDollars, логический оператор коньюнкции ∧ соответствует союзу «and». Логический оператор отрицания ¬ соответствующий частице «not» применяется к предикату Have, примененному к переменным Speaker и LotOfTime. При этом каждый предикат обладает параметром «истинности», и может читаться примерно следующим образом: «для переменных Speaker и FiveDollars истинно отношение Have». Не очень понятно? Зато компьютеру теперь немножечко понятно.
Линейная алгебра
Но логика хороша скорее для синтаксических отношений. А что с лексическими значениями? В одном из подходов к моделированию значений слов используется линейная алгебра — в дистрибутивной семантике слова моделируются как векторы в пространстве, где расстояние между векторами отражает отношения между словами:
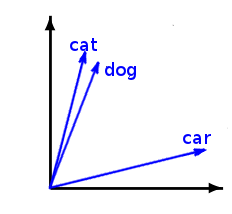
Самые популярные алгоритмы этого подхода — GloVe и Word2vec. Они используются в нейронных сетях, которые на основании анализа корпуса текста моделируют многомерное векторное пространство значений. А расстояния между векторами вычисляются традиционными для линейной алгебры способами — например, расчетом косинуса угла между ними.
Статистика
Основываясь на частоте совместного появления слов (word co-occurrence), алгоритмы становятся способны предсказывать, появление какого слова может быть наиболее вероятно после данной словоформы. Что интересно, этот подход может дополнить любой другой подход: например, в оптическом распознавании текста, применение статистических методов уменьшает неоднозначность толкования некоторых знаков — при неточности оптического распознавания статистические данные могут помочь распознать слово:

Вероятности совместного появления слов основанные на статистических данных являются одним из самых важных инструментов компьютерной лингвистики. Более того, статистические данные могут дополнить любой другой подход или модель: например, хорошие результаты дает совмещение систем, основанных на правилах (rule-based) и статистических систем.
Основанные на правилах системы представляют собой словари и грамматики — слова и правила их изменения и сочетания. Немного похоже на то, как люди изучают язык во взрослом возрасте основываясь на лексике и грамматике. Эти системы сами по себе несовершенны, поскольку могут использовать только прописанные экспертами правила и лексические единицы: перенести таким образом весь язык в цифровую форму без потери выразительности и вариативности пока невозможно. Однако, будучи дополненными статистическими данными, правиловые системы «оживают», приобретают гибкость и способность к адаптации.
Вычисления как фундамент «компьютерной» лингвистики
Язык человека — это основа его мышления, тогда как компьютерные системы в языке не нуждаются, они уже имеют свою основу — вычисления. Чтобы научить компьютер языку людей, нужно, чтобы его алгоритмы могли смоделировать сложный, естественно возникший феномен, который практически невозможно однозначно представить формальными средствами. Для этого необходимы сложные расчеты, статистические данные, множество вычислительных инструментов и моделей. Именно поэтому компьютерные лингвисты вынуждены много думать о вычислениях, происходящих внутри процессов компьютерной обработки языка. А компьютеры — это лишь очень удобный инструмент таких вычислений.



