
Как ИИ и мультиязычные модели могут помочь в каталогизации материалов на китайском языке? На этот вопрос отвечают Сай Дэн, библиотекарь по метаданным и заместительница библиотекаря в Университете Центральной Флориды, и Лихон Жу, заведующая отделом технических услуг в Университете штата Вашингтон. В своей совместной статье для The Digital Orientalist исследовательницы предлагают разработанный ими ИИ-инструмент, который не просто переводит слова текста, но и «понимает» его смысл.
Нюансы работы в библиотечном деле
В современных библиотечных системах каждое издание имеет собственную машиночитаемую каталогизационную запись формата MARC для хранения метаданных. Среди различных полей записи MARC есть поле тематики описываемого издания. Тщательный анализ тематики и точное внесение данных в MARC-запись повышают доступность и эффективность библиотечных ресурсов.
При анализе содержания изданий библиотекари (например, в англо- и немецкоязычных странах, а также в России) выявляют их тематику и преобразуют ее в краткую словесную формулировку (предметную рубрику), а также присваивают соответствующие дескрипторы (лексические единицы, общеупотребительные термины), что облегчает поиск нужной информации. Для этого каталогизаторы используют такие контролируемые лексические словари предметных рубрик, как «Предметные рубрики Библиотеки Конгресса» (LCSH) или «Фасетное применение предметной терминологии» (FAST), упрощенный словарь фасетно-категориального типа (в нем каждая единица информации классифицируется по нескольким явным и независимым друг от друга характеристикам) на основе LCSH.
В академических библиотеках, специализирующихся на исследованиях стран Восточной Азии, библиотекари-каталогизаторы должны быть знакомы с различными аспектами, например, китайской истории и культуры, чтобы при работе с источниками на этом языке точно анализировать их тематику и обеспечивать эффективность научной работы в области синологии.
Основной проблемой для крупных академических библиотек на протяжении долгого времени был найм библиотекарей с достаточным уровнем владения иностранными языками. В библиотеках по всему миру не хватает специалистов, которые могут качественно описывать и анализировать издания, особенно на китайском языке. Кроме того, вузовские библиотеки по всему миру сталкиваются со значительными сокращениями бюджета и личного состава.
Словарь для ИИ
Чтобы решить эти проблемы, многие академические библиотеки изучают способы интеграции больших языковых моделей (LLM) в свой рабочий процесс. Такая интеграция имеет смысл, учитывая, что LLM специализируются именно на лингвистической обработке, что подходит под задачи каталогизации, которые включают в себя анализ контента, интерпретацию и оформление метаданных. Перед тем как создать свой инструмент для каталогизации материалов на китайском языке, Сай Дэн и Лихон Жу выбирали между двумя словарями предметных рубрик — LCSH и FAST.
LCSH — это контролируемый лексический словарь заголовков, которые могут назначаться как отдельно, так и в сочетании с подзаголовками. LCSH имеет четыре категории: тематическую, формальную, хронологическую и географическую. Предметные рубрики формируются заранее для представления конкретных сложных тем в виде единого заголовка. Например, книга об архитектуре времен династии Суй может быть представлена таким предметным заголовком LCSH: Архитектура — Китай — История — Троецарствие — династия Суй, 220–618 гг.
У словаря LCSH есть большой недостаток: жесткие и сложные правила составления тем. В LCSH указана лишь небольшая часть всех возможных комбинаций заголовков и подзаголовков. Поэтому каталогизаторы могут также собирать так называемые свободно плавающие подзаголовки для более точного описания изданий. Но их применение подчиняется сложным и часто неочевидным правилам, что создает значительные трудности не только для неопытных каталогизаторов, но и для LLM. Поэтому автоматизировать работу с предметными заголовками LCSH с помощью ИИ пока трудно.
Именно поэтому авторы выбрали лексический словарь FAST для своего GPT-бота — его структура лучше подходит для автоматической обработки. FAST сохраняет богатый словарный запас LCSH, но упрощает его структуру и использование. Более того, в словарь FAST можно добавлять неограниченное количество новых фасет, не внося изменений в предыдущие. В нем предметные данные разделены на понятные категории (имена, названия компаний, географические названия, события, временные периоды, общие темы и т. д.), и их проще использовать как людям, так и ИИ. Все предметные рубрики FAST связаны со стандартизированными формами имен и терминов, хранящимися в базе данных. Благодаря этому присвоение рубрик FAST — просто выбор подходящих терминов из списка. Библиотекарям-каталогизаторам не нужно вручную собирать сложные заголовки из нескольких частей, как в случае с LCSH. Пользователи и каталогизаторы могут применять фасеты в произвольном порядке и, комбинируя их, создавать сложные запросы.
Учитывая это, авторы создали GPT для рекомендаций FAST, доступный на платформе OpenAI. Этот инструмент поможет библиотекарям быстрее и точнее подбирать темы для книг.
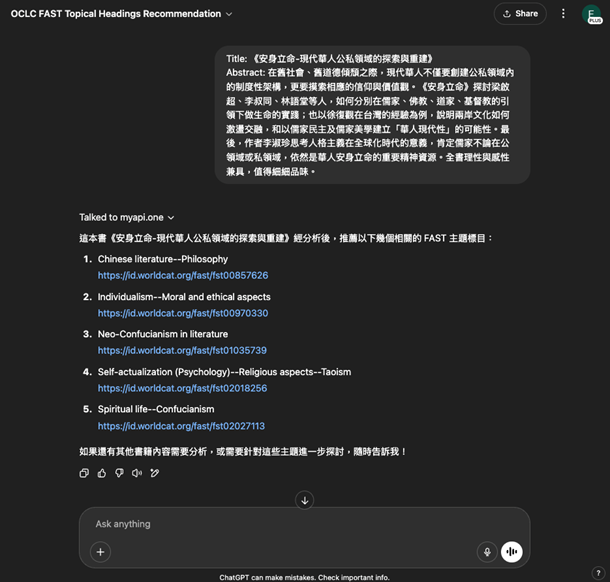
GPT-бот и каталоги: принципы работы
Словарь предметных рубрик FAST доступен на сайте Online Computer Library Center. Используя этот словарь, авторы создали векторную базу, предназначенную для хранения данных в виде многомерных числовых представлений (эмбеддингов). Это позволяет эффективно искать сходства на основе контекста, а не простого совпадения ключевых слов. В векторную базу данных при помощи модели «Text-embedding-3-small» были заранее загружены и преобразованы в векторы все стандартные тематические рубрики (на момент написания статьи их было около 486 тысяч). Эта модель поддерживает множество языков, помимо китайского, что делает ее подходящей для крупномасштабных проектов.
Векторная база данных используется в системе генерации, дополненной поиском [Retrieval-Augmented Generation (RAG)]. Когда пользователь или библиотекарь вводит, например, название и аннотацию книги на китайском языке, система находит в своей векторной базе наиболее подходящие по смыслу тематические рубрики. Благодаря возможностям модели «Text-embedding-3-small» система может эффективно искать подходящие по смыслу заголовки FAST даже на китайском языке, поскольку векторные представления (эмбеддинги) отражают семантическое значение на разных языках. Затем эти проверенные рубрики передаются языковой модели, которая формирует достаточно точный ответ на основе предметной терминологии.
В статье также приводятся конкретные примеры, как инструмент предлагает рекомендации по предметным рубрикам FAST для реальных китайских книг. Так, например, для книги о поиске современными китайцами ценностных ориентиров GPT-бот предложил рубрики: «Китайская литература — Философия», «Индивидуализм — Моральные и этические аспекты», «Духовная жизнь — Конфуцианство» и другие.
Заключение
Пока ИИ не заменяет библиотекарей, но может им помочь. Предлагаемый авторами GPT-бот может снизить трудовую нагрузку на работников библиотек. Его использование также может уменьшить влияние человеческого фактора на эффективность научной работы. Например, недостаточная лингвистическая экспертиза каталогизаторов будет компенсирована GPT-ботом. Это пример того, как цифровые технологии становятся инструментом для помощи экспертам-гуманитариям. Он демонстрирует потенциал интеграции LLM и векторных баз данных в рабочий процесс людей, занятых сохранением и систематизацией знания.
Источники
- Chow E. H. C., Deng S., Zhu L. Exploring the Future of Library Cataloging with AI and Multilingual Embeddings // The Digital Orientalist. 2025. URL: https://digitalorientalist.com/2025/05/09/exploring-the-future-of-library-cataloging-with-ai-and-multilingual-embeddings/ (дата обращения: 20.12.2025).
- Rabinowitz С. Staffing and Budget Cuts Limit Libraries’ Ability to Evolve // Inside Higher Ed. 2024. URL: https://www.insidehighered.com/opinion/letters/2024/10/30/staffing-budget-cuts-limit-libraries-ability-evolve-letter (дата обращения: 20.12.2025).

