
Что не так с определением сложности художественного текста?
Главная проблема при определении сложности художественного текста заключается в том, что он сложный по определению: метафоры, эксперименты с синтаксисом и лексической многозначностью, аллюзии и другие средства выразительности отличают художественный текст от обычного. Кроме того, понимание сложности текста меняется. То, что было ново и непривычно для читателя начала XX века, читателя XXI века не удивит и покажется простым в восприятии. Это значит, что измеряя сложность художественных произведений, важно учитывать культурный контекст.
Как методики были раньше и почему они не подходят для анализа современной прозы
В эпоху модернизма сложность была непременным атрибутом художественной литературы. «Улисс» Джеймса Джойса — яркий тому пример. К этому же времени относятся первые попытки литературоведов формализовать это понятие. Английский литературный критик Люциус Шерман (Lucius Sherman) был одним из первых исследователей, пользовавшихся методом, который сейчас в digital humanities называется «дальнее чтение». Сравнивая среднюю длину предложений в произведениях от Чосера (XIV век) до Эмерсона (XIX век), критик оценивал удобочитаемость (readability) этих произведений.
Средняя длина предложений надолго станет главным показателем сложности текста. Самый известный индекс удобочитаемости — индекс Флеша. Он учитывает длину предложений и количество слогов в слове (подробнее об индексе Флеша — в этой статье СБ{ъ}).
Вот какая картина получится, если распределить по этому показателю разнообразные по жанру и стилю (детская литература, авангардная проза, викторианский роман) английские произведения XIX — XX веков.
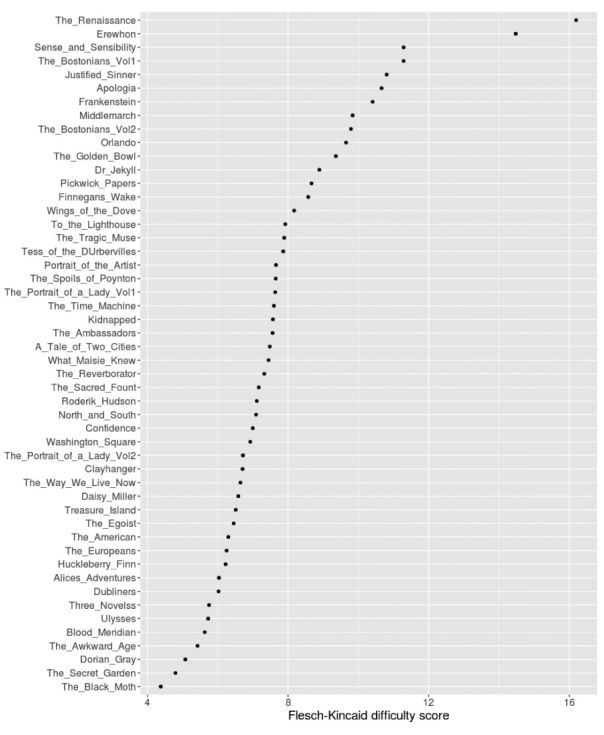
Несмотря на общее представление о модернистской литературе как чрезвычайно многословной (из-за популярного в это время приёма «поток сознания»), многие тексты первой половины XIX века, например, «Чувство и чувствительность» Остин, имеют показатели гораздо выше. А вот у авангардных романов Джойса «Улисс» и «Поминки по Финнегану» показатели невысокие, скорее всего потому, что в этих текстах много как очень коротких, так и очень длинных предложений. Мы видим, что меры удобочитаемости, основанные на длине предложений, не дают объективной картины для художественной литературы.
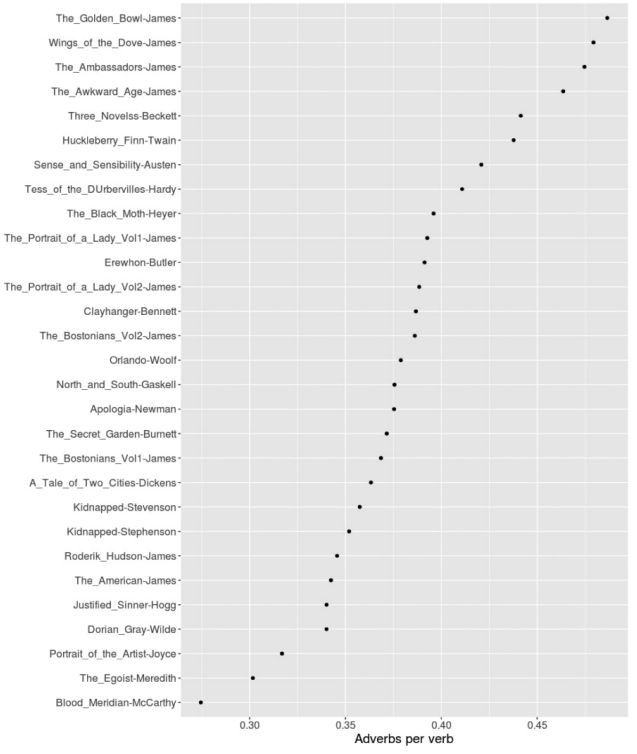
Как еще можно измерить сложность? Например, по использованию частей речи. На графике ниже видно, как распределяются те же тексты, если подсчитать в них частоту использования наречий. Результаты такого анализа интересны, хотя и не скажут ничего нового о сложности текстов. Например, можно убедиться, что Генри Джеймс, для которого «прилагательные — это сахар литературы, а наречия — её соль», щедро сдабривал солью свои тексты.
Некоторые литературоведческие школы считают показателем сложности стиля абстрактность используемых слов: чем больше абстрактных слов, тем сложнее текст. Ewan Jones и Paul Nulty из Кембриджского университета проанализировали уже упомянутые английские тексты XIX-XX веков по этому критерию. Для этого они использовали словарь, в котором слова размечены носителями языка по степени абстрактности-конкретности. Испытуемые оценивали слова, ставя баллы от 1 до 5 напротив каждого слова. Каждый текст был оценен по среднему значению конкретности тех слов, которые есть и в словаре, и в самом тексте. Вот что получилось:
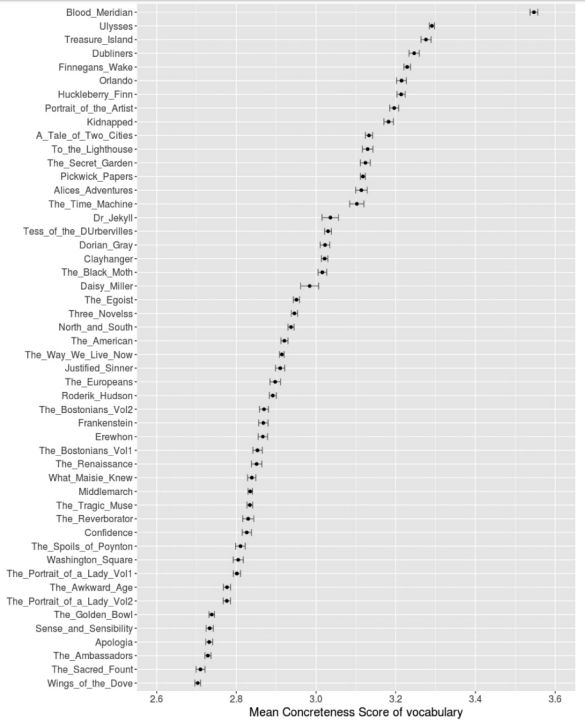
Предсказуемо, что вестерн Кормака Маккарни «Кровавый меридиан» оказался в самом верху шкалы конкретности, а роман Генри Джеймса «Крылья голубки», считающийся одним из самых сложных в его творчестве, — в самом низу, то есть самым абстрактным. Но удивительно, что авангардный «Улисс» соседствует с приключенческим романом «Остров сокровищ» Стивенсона, а степень конкретности Джойса остается одинаковой, несмотря на значительную эволюцию его стиля от реалистических «Дублинцев» до экспериментального романа «Поминки по Финнегану». Этот факт ставит под сомнение тезис, что по лексической абстрактности можно судить о сложности текста.
Различаем понятия
Итак, ни одна из предложенных методик не дает глубокого понимания проблемы. Причины этого авторы статьи видят в неразличении двух понятий — удобочитаемость ( ‘readability’) и сложность (‘difficulty’) текста. Удобочитаемость — показатель легкости восприятия текста носителем языка, и ее вполне возможно измерить теми способами, которые описаны. Сложность же — это свойство, присущее тексту как эстетическому объекту, и ее уже невозможно измерить, не сравнивая произведение с культурным контекстом: текстами предшественников и современников.
Возьмем, к примеру, Шекспира. Кому сложнее его читать — его современникам или же нам, читателям XXI века? С одной стороны, обилие устаревших слов будет затруднять нам чтение. С другой — многие фразы Шекспира (вроде «весь мир — театр») для нас стали уже устойчивыми, а для читателей XVI-XVII веков такие метафоры были новаторством.
Как же измерить этот культурный контекст?
Большие данные в помощь
Ewan Jones и Paul Nulty предлагают новую методику определения сложности художественного текста: они измеряют сложность не конкретного текста, но в сравнении с окружающим контекстом, который измеряется в на основе анализа больших текстовых корпусов.
Авторы статьи использовали для своей задачи Google Books Fiction, раздел с английской художественной литературой с 1800 по 1915 год, который состоит из примерно 7.1 миллиардов токенов.
Эксперимент с измерением сложности исследователи проводят на примере Генри Джеймса. Выбор не случаен. Во-первых, произведения именно этого автора показывали самые неожиданные результаты в предыдущих измерениях. Во-вторых, стиль Джеймса вдохновил многих исследователей на вычислительные методы в литературоведении. Кроме того, он интересен не только в сравнении с другими, но и в сравнении с самим собой: разница между ранним Джеймсом и поздним огромна.
Ключевым параметром становится относительная частота употребления слов. Логика проста: чем больше в тексте знакомых слов, тем текст для нас «предсказуемее», легче. Для каждого слова в датасете и в «испытуемых» произведениях из первых экспериментов вычисляется мера Ципфа: насколько часто встречается слово в конкретном произведении и насколько часто встречается оно же во всем корпусе. При этом учитываются только те слова, которые встречаются и там, и там.
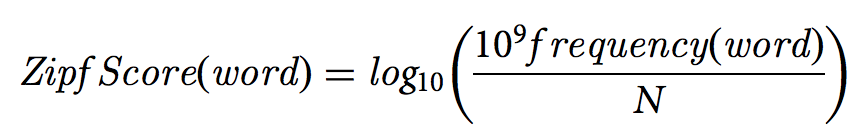
Затем меру Ципфа в корпусе для каждого слова сравнили с мерой Ципфа каждого конкретного произведения. Вот что получилось:
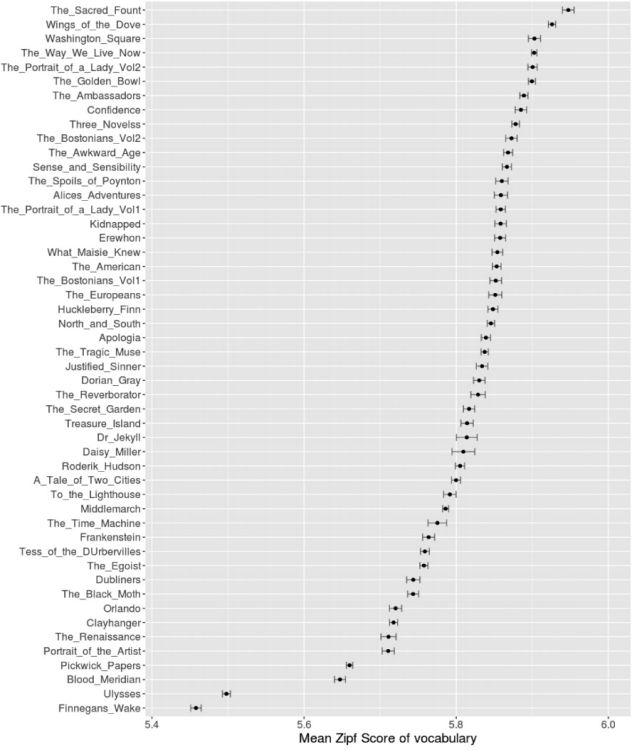
Экстремумы на этом графике — это «Поминки по Финнегану» (Finnegan’s Wake) Джойса: наименьшее значение, и «Крылья голубки» (Wings of the dove) Джеймса: наибольшее значение (на графике наибольшее значение у The Sacred Found Джеймса, но в источнике речь идет о «Крыльях голубки» — прим.ред.). Кажется, это значит, что Джойс максимально отличается от литературного контекста, а Джеймс максимально на него похож. Но это не так: близость к контексту определяется близостью к среднему значению, т.к. сравнивается относительная сложность произведений. Наиболее близкий к контексту текст — это «Записки Пиквикского клуба» Диккенса, его значение 5.65, именно его показатель ближе всего к общему среднему по корпусу. А экстремумы — это непохожесть на контекст, причем эта непохожесть может быть как и простотой, так и сложностью. Джойс добивается этой непохожести благодаря словотворчеству. Джеймс же выделяется даже при большой доле общих слов, при этом язык Джеймса, которого считают многословным и заумным автором, проще, чем язык детских популярных книг вроде «Таинственного сада».
Удивительно и то, что «относительная похожесть» словаря Джеймса возрастает в его поздних работах, которые в литературной критике принято считать самыми сложными.
Это ещё одно подтверждение двум тезисам:
1. Сложность в простоте.
2. Сложность и удобочитаемость — разные вещи.
Источник: Ewan Jones, Paul Nulty. Quantitative measures of lexical complexity in modern prose fiction

