
Около шести лет назад я создала в вотсаппе семейный чат, и с тех пор в ежедневной переписке создаётся хроника жизни нашей семьи: весёлое и грустное, дурацкое и значимое, книги, которые мы читаем, фильмы, которые смотрим, фотографии, поздравления, хлопоты, неудачи — рутина, которая важна и интересна только самым близким. Наверное, такие чаты есть сейчас у миллионов семей.
Иногда я думаю о том, как бы мне хотелось прочесть что-то подобное про жизнь моих предков, например, лет сто или двести назад. Но что, если посмотреть на это с другой стороны? Смогут ли мои правнуки — через те же сто или двести лет — узнать, как жила их прабабушка? Не надежней ли будет купить тетрадку и время от времени что-то туда записывать?
Практически каждый день мы слышим о том, как с помощью современных технологий поменяется наше будущее. Но, кажется, не меньшее влияние эти технологии будут иметь на прошлое — вернее на то, каким образом мы будем обращаться из этого будущего к нашему уже совершенно цифровому прошлому.
Коллективная память и осознание рисков
Эбби Смит Рамси, историк и культуролог из Стэнфорда, автор книги When We Are No More: How Digital Memory is Shaping our Future говорит в одной из своих лекций о способности людей к коллективной памяти. Памятью обладают многие живые существа, но только человек научился сохранять её и передавать соплеменникам и потомкам. Для того чтобы транслировать, что они помнят, люди, начиная ещё со времён глиняных табличек, открывают и придумывают технологии.
Удивительно, но именно способность к коллективной памяти о прошлом неразрывным образом связана с нашим пониманием будущего — и умением создавать это будущее. Это абсолютно неразделимые вещи, считает Рамси: что нас ждёт в нашем цифровом будущем, во многом определяется тем, насколько нам удастся создать цифровую коллективную память. Что такое семейный архив, скажем, двух поколений назад? Что осталось нам в память от наших прабабушек и прадедушек? Письма в конвертах, перевязанные ленточками, альбомы с фотографиями или отдельные дагерротипы с нарядными мужчинами и женщинами, или, может быть, тетрадки с дневниковыми записями? Чем больше времени проходит, тем большую ценность, и не только для родственников, представляют материальные артефакты памяти. Именно так проект «Прожито» собирает и публикует дневники и воспоминания, которые приносят ему волонтёры: частные записи становятся частью коллективной памяти.

Страница из дневника Н. Казакова, архив центра «Прожито» ЕУСПб
Но как будут выглядеть свидетельства нашей жизни, которые в какой-то момент получат наши потомки? Ведь наша жизнь документируется нами с потрясающей подробностью. Практически каждый день, так или иначе, мы создаём запись о себе — это может быть пост в соцсетях, или изображение, или просто геолокация. То, что мы видим в текущий момент, и то, как мы видим себя, сохраняется в гигантском множестве фотографий.
Мы ежесекундно создаём огромный цифровой архив человечества, но при этом совершенно непонятно, куда это всё денется дальше и сложится ли из этого действительно коллективная память — та самая, без которой невозможно будет представить наше будущее.
Можно ли будет изучать историю первых десятилетий XXI века без доступа к твиттеру или фейсбуку? Являются ли наши современные технологии надежной заменой олдскульным бумажным архивам? Что мы можем противопоставить нарастающему тревожному ожиданию неминуемой потери артефактов памяти?
Born Digital
Проблему сохранения воспоминаний в новом веке впервые артикулировали ещё в 1975 году, задолго до возникновения интернета и цифровой реальности. Выдающийся архивист Джеральд Хэм говорит в своей статье «Край архива» (Archival edge), что сама профессия архивиста должна критическим образом измениться на фоне огромного количества документов, новой структуры общества, технологий, которые не рассчитаны на долгое хранение объектов. Архивист из хранителя должен стать куратором, то есть активным участником процесса накопления архивных данных.
Через пятьдесят лет статья Хэма нисколько не потеряла своей актуальности — напротив, противоречие только обострилось. Мы живём сегодня с ещё более нестойкими технологиями, внутри бесконечного потока данных, не связанных напрямую ни с каким материальными объектами. Мы почти не создаём артефактов памяти, которые можно убрать в коробку, положить на полку или сложить в папку, — в ожидании тех, кому они понадобятся через десятки или сотни лет.Документы, которые производятся в огромном количестве в XXI веке, получили своё специальное название: born digital, рождённые цифровыми. Они никогда не существовали в материальном виде, а сразу уже были созданы «в цифре» — тексты, написанные на компьютере, письма, отправленные по электронной почте, электронные фотографии, аудио и видеозаписи, веб-сайты, датасеты и базы данных.
Фото: Richard Horvath / Unsplash
Про born digital говорят, что они одновременно перманентны и эфемерны. «Интернет помнит всё», — нередко слышим мы, и действительно, документ, уже распространившийся в сети, практически невозможно уничтожить, вывести из публичного поля. Но одновременно цифровые документы очень легко изменяются или становятся недоступными. Бумажные письма могут храниться столетиями, сохранность электронной переписки зависит от коммерческого провайдера: закрытие компании легко может повлечь за собой потерю доступа ко всем данным её пользователей, скачивание переписки на локальный компьютер ставит её в зависимость от технической исправности компьютера — и даже документы, размещённые в облачном хранилище, могут в какой-то момент стать недоступными из-за устаревания или повреждения форматов.
Практически каждый концептуальный документ, посвящённый сохранению цифровых архивов, начинается с перечисления разнообразных рисков, которые могут привести к утрате документов:
- физические риски повреждения: сгорел компьютер, не читается дискета;
- технологическое устаревание: старый софт, на котором были сделаны документы, несовместим со современным программным обеспечениям, и документы невозможно прочесть;
- утрата доверия к данным: насколько мы уверены, что файлы не менялись;
- сохранение контекста и зависимостей данных: даже простейшие текстовые документы могут зависеть от других файлов, например, шрифтов. А ещё они могут иметь ссылки на веб-страницы, которые больше не существует, или содержание этих веб-сайтов уже изменилось и не имеет отношения к исходному документу.
Из этих рисков вытекают два ключевых требования к процессу цифровой архивации и, соответственно, к компетенциям тех, кто ей занимается.
Во-первых, сохранять нужно вовремя: технологии развиваются так быстро, что можно пропустить момент, и цифровые документы нельзя будет прочесть без прикладывания особых усилий или нельзя будет прочесть совсем. Иначе говоря, сохранять нужно то, что появляется сейчас, не дожидаясь того, как это станет историей.
Во-вторых, цифровое архивирование напрямую связано теперь с компьютерной инженерией, с помощью которой обеспечивается сохранность, неизменность и аутентичность цифровых документов и умение справляться с огромными потоками данных.
Цифровая презервация и её регламент
Первыми инициаторами цифровой архивации стали институты памяти — музеи, библиотеки, архивы. Нужно сказать, что в целом эти процессы начались ещё задолго до интернета и появления born digital документов. Начала внедряться система электронного поиска, существенно повлиявшая на доступность информации. Каталоги библиотек переводились в электронные базы данных, а научные статьи организовывались в электронные коллекции. Так, в 1976 году был создан Оксфордский текстовый архив, а Библиотечный центр Колледжа Огайо (OCLC), связавший революционным образом в 1967 году каталоги всех библиотек штата, к 2001 году вырос до крупнейшей международной системы, связывающей главные библиотеки мира, и cменил название на Online Сomputer Library Center.С развитием интернета достаточно быстро возникло понимание необходимости архивного хранилища сайтов — Интернет-архива. WaybackMachine, открытый в 1996 году, работает уже больше 25 лет и за это время вырос в огромное хранилище сначала сайтов, а потом и документов, обнаруженных в сети: радиопрограмм, фильмов, книг и даже компьютерных игр.
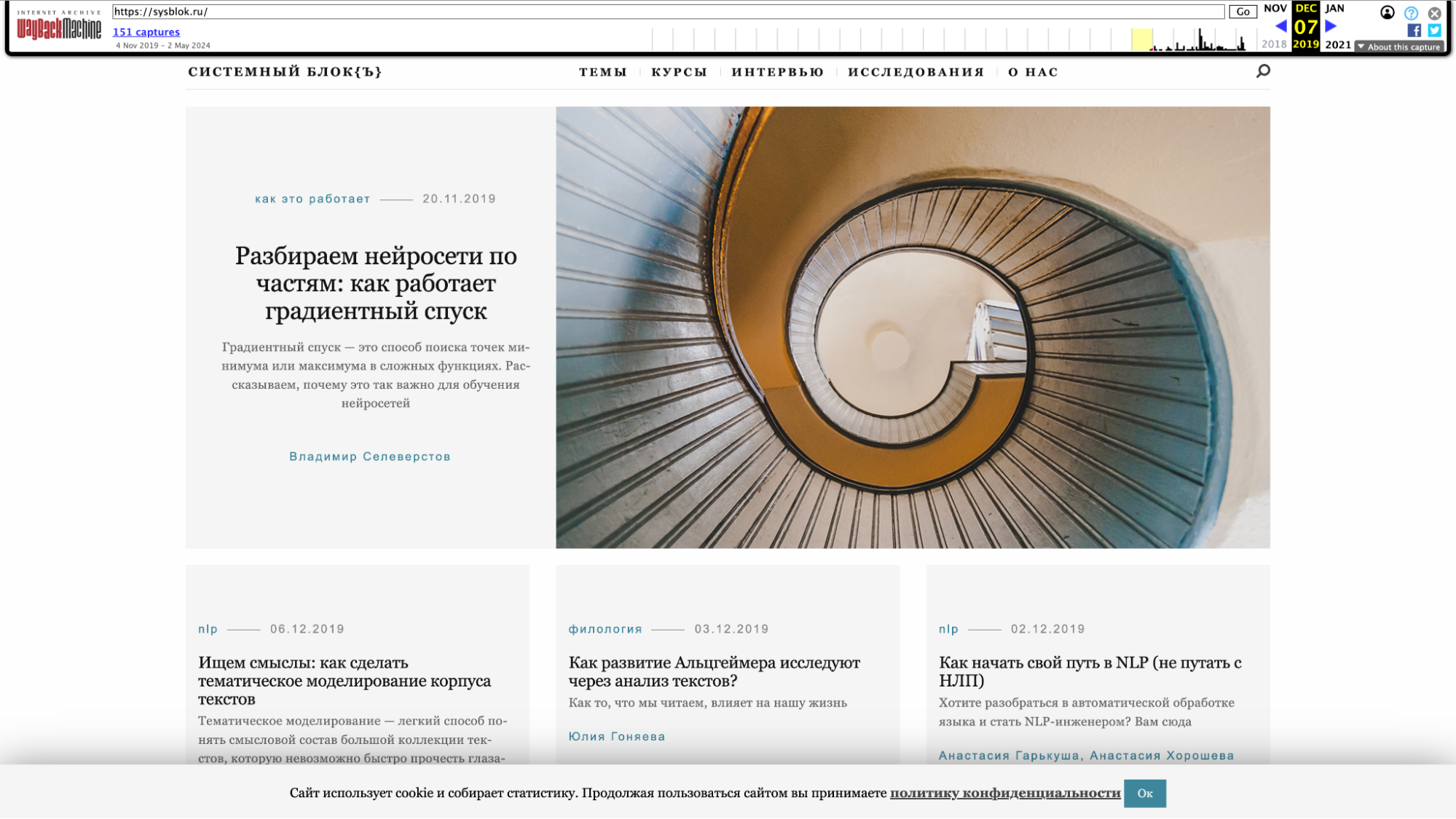
Самый ранний слепок сайта «Системного Блока», доступный в интернет-архиве
В течение 2010 годов формируется глобальная инфраструктура цифровой архивации: разворачиваются облачные хранилища, создаются программы, приложения и среды для архивации, наиболее известная из них — Preservica. Но, наверное, самое важное, что происходит, — формируется идеология цифровой презервации, digital preservation. Цифровые документы нужно не только сохранить в архив, но и обеспечить им доступность для поиска, чтения и использования в будущем.
Любопытно, что никто не может точно сказать, о каком периоде сохранения идёт речь — 5 лет, 10 лет, 100 лет или больше? В 2017 году вышло исследование того, насколько актуальны ссылки на веб-ресурсы в научных статьях, опубликованных с 1997 до 2012 года. Содержание веб-ресурсов, которое было найдено в веб-архивах, соответствующее времени, когда эти статьи были написаны, сравнивалось с тем, что содержится по этим же ссылкам сегодня. Результаты были совершенно поразительны: более чем 75% веб-ресурсов, ссылки на которые имеются в научных статьях, изменили с тех пор своё содержание. Получается, что цифровизация фантастически ускоряет обмен научным знанием, но одновременно ставит под удар сам процесс его трансляции будущим поколениям учёных — то, что до сих пор считалось основой развития науки.
Ключевая идея цифровой презервации состоит в регламентации. Бороться с цифровым хаосом следует регулированием последовательности действий, которые должны, по крайней мере, обеспечить предсказуемость того, как и в каком виде сохраняются born digital. Технологии сохранения должны быть максимально прозрачными, это даёт хоть какую-то надежду, что даже при непредсказуемом технологическом развитии они останутся доступными.
Современная инфраструктура цифровой презервации определена гайдами, которые разрабатываются коалициями и ассоциациями, куда входят всё те же крупнейшие институты памяти и государственные институции. Но есть проблема, которую не вполне понятно, как решать, даже следуя гайдам и чек-листам. Идея сохранять всё и сразу, пока оно не пропало или не устарело, входит в прямое противоречие с тем, что некоторая частная информация должна устареть, прежде чем её можно будет открыть в публичном доступе.
Частная память. Чувствительность данных
Важнейшим эффектом перехода современных коммуникаций в цифровой формат стало стирание границ между общественной и частной информацией: поисковые системы не делают различий между государственным постановлением или частным высказыванием в блоге. И проходное сообщение в вотсаппе, и исторически значимый документ в цифровом виде представляют собой последовательность нулей и единиц. Частные коллекции время от времени становятся частью публичных цифровых архивов, однако нет ни понимания, ни решения о том, как их сохранять глобально.
Один из важнейших принципов цифровой архивации, который мы обозначили выше, — сохраняй своевременно, не дожидаясь, пока файлы повредятся или их форматы устареют, входит в прямой конфликт с другим фундаментальным принципом — защиты личной информации и частной жизни.
Поразительно, но имеющиеся в цифровых архивах библиотек частные born digital коллекции нельзя прочесть онлайн. Несмотря на то, что эти документы «рождены цифровыми», исследователь должен физически приехать в здание библиотеки, чтобы прочесть, например, архив электронной переписки. Такой архив нельзя скопировать и выложить в интернет на всеобщее обозрение, а только использовать для своих научных исследований. В Стэнфордском университете даже разработали специальную программу ePADD — она подготавливает архивы имейлов, стирая оттуда имена собственные и другую частную информацию. Обработанные с помощью ePADD архивы можно посмотреть онлайн, чтобы примерно понять их содержание. И если потребуется, уже можно пойти туда, где тебе (возможно!) дадут прочесть их в более полном виде.
Насколько важны коллекции электронной переписки, можно судить по чуть ли не единственному открытому подобному архиву. База данных скандальной энергетической компании Энрон, фальсифицировавшей свою прибыль и обанкротившейся в 2001 году, содержит около полумиллиона писем. Андрю МакКаллум, специалист в области компьютерных наук, купил эту базу за 10 000 долларов и выложил в открытый доступ: он посчитал, что такой архив может быть интересен программистам и учёным. С тех пор эта база стала ключевым ресурсом для исследований в области общественных наук — социологии, психологии и менеджмента корпораций. Google Scholar даёт ссылки на почти десять тысяч статей, написанных на материалах архива писем Энрона. Примеров таких открытых коллекций единицы, и это неудивительно.
Связанность частных born digital коллекций с физическим местом их размещения возвращает нас к идее «аналогового» артефакта памяти — предмета или архива, который существует в единственном экземпляре. Такой артефакт защищает данные от подделки и от нарушения частной жизни. Его сохранение является миссией музея, архива или библиотеки.
Чем концептуально отличается сохранение цифровых документов от хранения музейных экспонатов? Что следует из того, что в первом случае мы имеем дело с набором битов (нулей и единиц), а во втором случае с материальным объектом? Что представляет собой цифровой объект?
Цифровой объект: эмуляция или миграция
Мэтью Киршенбаум, автор книги Track Changes: A Literary History of Word Processing, исследует, как меняется процесс литературного творчества в цифровой реальности, какие трансформации претерпевает текст, если он создаётся не пером на бумаге, а с помощью клавиатуры на лэптопе. Идея Киршенбаума состоит в том, что цифровой объект отличается от нецифрового тем, что он функционально распределён.
Например, презентация как цифровой объект состоит из трёх элементов: содержания (текстов, рисунков, анимации), кода, с помощью которого мы можем прочесть этот цифровой объект, и носителя (например, флешки или диска), на который мы можем записать код.
В отличие от материальных объектов, про цифровые объекты мы чаще всего знаем, кто является его создателем, когда и даже где этот объект был создан, эта информация является частью кода. Но при этом мы совсем не всегда можем доверять этой информации: открытие, копирование, сохранение файла влечёт за собой перезапись метаданных. Ключевым принципом цифровой архивации (и презервации) является аутентификация: мы должны быть уверены, что имеем дело именно с тем цифровым объектом, который мы сохраняем. Главный инструмент здесь — создание полной дисковой копии и подсчёт контрольной суммы. Эта операция показывает, различаются ли два файла, даже если они выглядят одинаково. В мире цифровых объектов «клонирование» легализовано, аутентифицированная дисковая копия признаётся в качестве доказательства в суде.
Что делать с цифровым объектом, после того как была создана его копия и контрольная сумма подтвердила идентичность копии? Существуют два решения в области цифровой презервации: «миграция» — перенос данных в безопасный формат, знакомый современному пользователю, и «эмуляция» — технологическое воссоздание современными средствами той среды, в которой цифровой объект создавался, если эта среда сейчас является технологически устаревшей.
Наиболее известный пример работы с цифровой коллекцией именно как с цифровым объектом — архив известного британского писателя Салмана Рушди в университете Эмори. В 1988 году иранский аятолла проклял Рушди за его роман «Сатанинские стихи» и вынес фетву, приговаривающую писателя к смертной казни. После объявления фетвы Рушди, прятавшийся от преследования, начал активно использовать компьютер и новые на тот момент технологии — они помогали ему общаться с миром, получать факсы и имейлы и при этом в случае опасности позволяли быстро менять место жительства.
В 2006 году Рушди передал в университетскую библиотеку четыре компьютера, жёсткий диск и несколько внешних дисков, содержащих его переписку и файлы с его произведениями. Архивисты библиотеки приняли решение использовать оба подхода: и миграцию, и эмуляцию. Большую часть документов перевели в формат pdf и загрузили в университетскую базу.
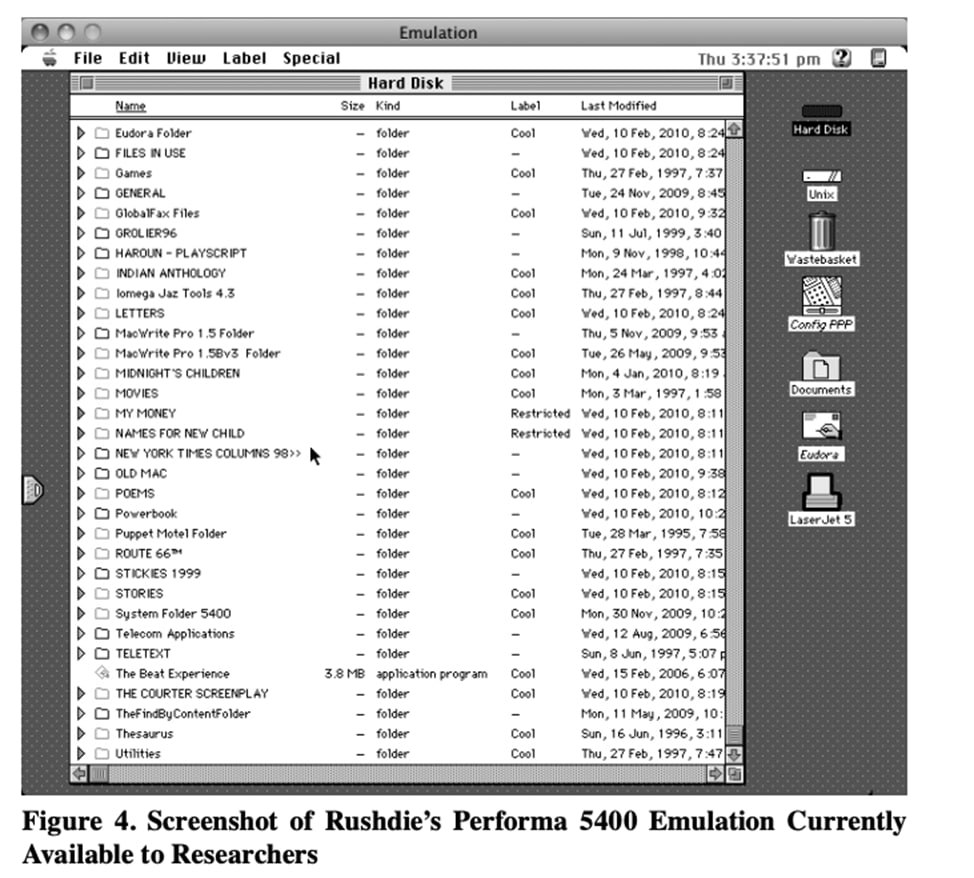
Скриншот из Carroll, L., Farr, E., Hornsby, P., & Ranker, B. (2011). A comprehensive approach to born-digital archives. Archivaria, 61–92
Эмуляция полностью воспроизводит среду, оригинальный софт, в которой существовал файл, — мы видим ровно то, что видел создатель файлов. Цифровые объекты в этом случае рассматриваются как артефакт, а не просто как контент. Эмуляция сохраняет медиум, который может иметь принципиальное влияние на наше понимание функционирования цифрового объекта, и создаёт эффект максимальной интерактивности. Пользователь может открывать, сохранять или удалять файлы, он может даже играть в компьютерные игры. Пользовательская версия не сохраняется, но она даёт ощущение присутствия и погружения в контекст.
Чёрный архив. Искусственный интеллект.
Мы не можем увидеть содержание любого цифрового документа без использования специальных программных средств: они преобразуют последовательность нулей и единиц в то, что может прочесть человек. А это значит, что в цифровом архиве документы не существуют вне поискового запроса, заданного напрямую читателем или — заранее — архивистом. Мы не можем обнаружить документ случайно, если предварительно не была создана система организации данных, интерфейс, позволяющий найти необходимое или связать его с другими документами.
«Чёрный архив» (по аналогии с чёрным ящиком) — это страшный сон цифрового архивиста: гигабайты, терабайты файлов, которые непонятно как упорядочить, которые невозможно прочесть и описать.
Фундаментальный принцип классического архивного дела respects de fonds состоит в том, что архивист не должен упорядочивать коллекции самостоятельно, а должен сохранять ту организацию архива, которая была заложена в него изначально. Нельзя навязывать своё индивидуальное видение в условиях постоянно растущих фондов — миссия архивиста состоит в сохранении и передаче объектов памяти, а не в их интерпретации. Сохранение документов born digital требует ровно обратного: без категоризации, разметки документов и создания тематических подборок по множеству разнообразных параметров цифровой архив вообще нельзя считать сохранённым. Такой архив невозможно использовать, потому что документы в нём не будут найдены. Продолжая следовать посылу Джеральда Хэма из далёкого 1975 года, современные цифровые архивисты являются активными акторами процесса создания коллекций, кураторами, а не хранителями цифровых архивов. Соответственно, их роль значительно возрастает — можно сказать, что они обладают определённой властью над конечной формой архива, их субъективное представление и профессиональная оптика приобретают особенное значение. Это ставит дополнительные этические вопросы о работе архивистов-кураторов.
Цифровые архивы, посвящённые террористическим актам 11 сентября 2001 года, первой большой трагедии цифрового мира, стали создаваться практически сразу. Было очевидно, что, если не прикладывать специальные усилия, свидетельства о том, как люди переживали эту катастрофу: смски людей, находившихся в Башнях-близнецах или в самолётах, электронные письма, которыми обменивались люди в те дни, — будут безвозвратно утрачены.
Цифровые архивисты не просто собрали коллекции: цифровой архив 11 сентября, коллекцию рассказов людей о том, где они находились в момент трагедии, написанных на сайт или загруженных в видеоформате, но определили и структурировали коллективную память: как и что будут помнить, как и о чём будут говорить. Эти архивы создавались краудсорсингом: так коллективная память выстраивается из тысяч индивидуальных частных документов, которые люди отдали в архивы или создали специально для архивов.
Цифровые архивы организованы тематически, предлагая читателю внятные маршруты навигации. Они ориентированы на читателя, который привык к интерактивному взаимодействию с сайтом, поскольку пользовательское поведение в интернете сильно отличается от линейного чтения книги или переключения кнопок телевизора. Пользователь следует определённым сценариям, которые должен предугадать создатель сайта. В случае цифровых архивов именно такие сценарии взаимодействия с коллекцией архива конфигурируют коллективную память о событии.
Недавний пример активного конструирования памяти — цифровые коллекции, посвящённые ковиду как периоду времени, объединённому коллективным общим опытом глобального масштаба. Тем более, локдаун способствовал ещё большей цифровизации повседневной жизни. Представленность этого коллективного опыта в больших цифровых коллекциях очень разнообразна: есть глобальные тематические коллекции публичных документов, как, например, в библиотеке Конгресса, а есть локальные: например, университет Буффало сохранил в своём архиве документы, которые отражают, как университет существовал во время локдауна.
Коллекция университета Буффало состоит из трёх частей: веб-страницы департаментов университета с информацией, связанной с ковидом или локдауном, официальная внутренняя переписка, посвящённая организационным вопросам во время ковида, и электронные документы любых форматов, от имейлов до тиктока, отражающую жизнь студентов и преподавателей во время пандемии. Кураторы проекта отдельно отмечают, что третий раздел в основном посвящён жизни студентов, которая обычно в университетских архивах представлена очень слабо. Весь архив, таким образом, представляет собой не просто сохранение источников, но их концептуальную организацию, направленную на то, чтобы воспроизвести с помощью документов архива структуру событий места и времени, как её видят кураторы архива.
Приведённые примеры связаны с архивами, которые собирались «по горячим следам». То есть кураторы сначала сами формулировали дизайн архива, ту виртуальную конфигурацию коллективной памяти, которую они хотят построить, а потом наполняли его документами. Но если цифровой архив уже существует, задача архивиста-куратора состоит в том, чтобы вытащить из него подборки, истории, тематические кластеры, не только облегчающие навигацию, но и задающие сценарии взаимодействия с ним. Сделать это без помощи искусственного интеллекта в тех огромных масштабах данных, с которыми цифровым архивистам приходится иметь дело, практически невозможно.
Замечательный пример здесь — газетный цифровой архив библиотеки Конгресса, Chronicling America, содержащий около шестнадцати миллионов оцифрованных и распознанных газет. Пользователь сайта может искать по текстам газет напрямую, а может обратиться к тематическим подборкам, подготовленными кураторами архива и освящающими самые значимые события XX века. Примечательно, что у пользователя есть возможность обратиться напрямую к кураторам коллекции и предложить свою тему для подборки. У этого архива есть и экспериментальный проект Newspaper navigator, в котором 1,5 млн фотографий из оцифрованных газет размечены с помощью технологий машинного обучения. Теперь эти фотографии можно искать по ключевым словам, описывающим то, что на них изображено.
С помощью «компьютерного зрения» можно генерировать описания фотографий и видео, с помощью лингвистических технологий создавать краткие резюме документов и тематические теги, аудио можно снабдить расшифровкой, с помощью ИИ можно установить связи между разными документами и зашифровать чувствительную информацию. Проблема здесь в том, что чаще всего работники библиотек и музеев, отвечающие за сбор и курирование цифрового архива, не обладают нужными компетенциями для управления архивом с помощью искусственного интеллекта, и им непросто найти общий язык с инженерами. Образовательные программы быстро меняются, но всё равно не поспевают за запросами индустрии цифровых архивов. Это проблема сегодняшнего дня.
Проблемы завтрашнего дня — нужно ли нам сохранять гигабайты информации, сгенерированные искусственным интеллектом, имеет ли это какое-то отношение к миссии институтов памяти и как отличить документ, представляющий историческую ценность, от документа, порождённого моделью GPT следующих поколений.
Изначально материал вышел в проекте Гёте-Института «Как читать медиа».
Фото на обложке: Su San Lee / Unsplash



