Введение
С незапамятных времён теоретики литературы и искусства пытались найти то общее, что объединяло бы между собой сюжеты художественных произведений. Начиная с идеи о мономифе и формализма Владимира Проппа, заканчивая четырьмя типовыми сюжетами по Хорхе Борхесу и 36 драматическими ситуациями Жоржа Польти.
Современные исследователи не отстают от классиков. Так, например, Бен Шмидт (Ben Schmidt) воспользовался методами цифровой гуманитаристики, чтобы выявить шаблон типичного сюжета, опираясь на распределение реплик и тем в фильмах и сериалах [1]. Позже его идеи легли в основу исследования Дэвида Макклюра (David McClure) из Литературной лаборатории Стэнфорда (Stanford Literary Lab). Исследователь изучал тенденции, которые проявляются в частотности слов внутри литературных текстов [2]. Например, Макклюр выяснил, что в начале текстов часто описывается внешность героев и их образование, а в конце — брак. Незадолго до конца текстов приходится пик на слова, связанные со стрельбой, насилием и оружием.
Какие слова наиболее типичны для начала, а какие — для финала художественных книг на русском языке? Давайте разбираться!
Как найти распределение слов в текстах?
Представим, что мы хотим найти закономерности в расположении некоторого слова Х в большом количестве художественных произведений. Для простоты сначала возьмём один произвольный текст. «Растянем» его в длинную строку и «подсветим» синими точками те её места, где встретилось слово Х.

Точками показано, в какой части текста встречается слово X
По рисунку можно видеть, что в рассматриваемом тексте слово Х с большей вероятностью тяготеет к первой половине текста. Теперь нужно понять: это свойство слова Х возникать в начале произведений или же свойство только лишь рассмотренного текста содержать слово Х в своём начале? Для этого возьмём больше текстов и также «подсветим» слово Х в каждом из них.
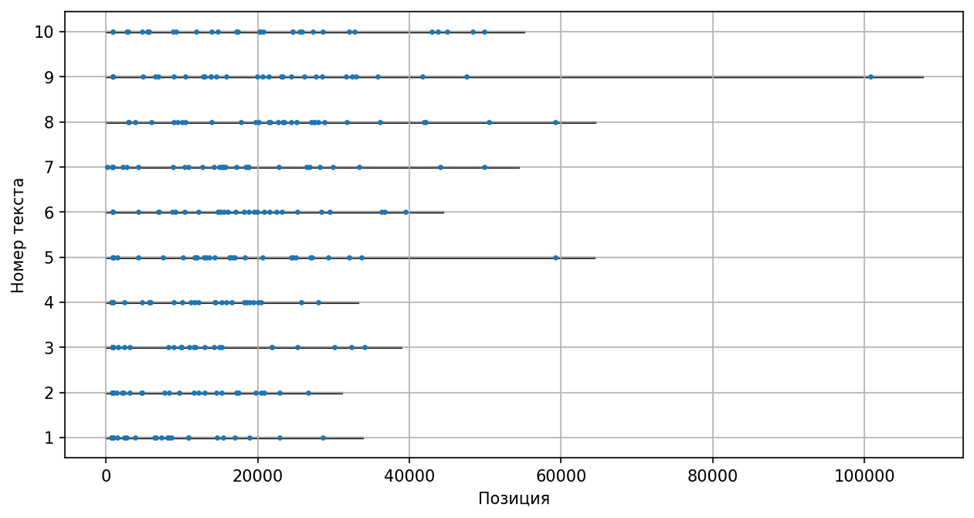
Точками показано, в какой части десяти текстов разной длины в встречается слово X
На первый взгляд, всё хорошо, однако из-за того, что рассматриваемые тексты имеют разную длину, обобщить полученную информацию об ожидаемом положении слова Х крайне сложно. Позиция, являющаяся для одного текста финалом, вполне может оказаться серединой или даже началом для другого текста. Например, позиция 20 000 для текста 1 относится ко второй половине, а для текста 9 — скорее к завязке. В таких условиях рассуждать о «склонности» слов к появлению в начале или конце произведений не получится.
Чтобы исключить влияние длины произведения на позицию слова в нём, нужно нормировать длины текстов и, вместе с этим, позиции слова Х в них. Для этого «растянем» или «сожмём» все графики на рисунке так, чтобы уравнять их длины, привести к единичной длине. Теперь горизонтальная ось обозначает не абсолютную позицию слова, а долю текста, которое оно «отсекает» относительно его начала.
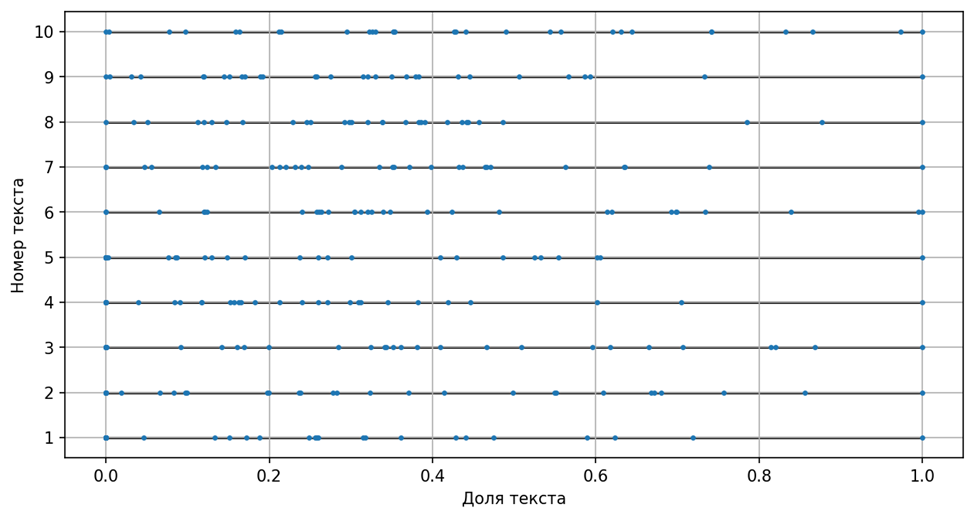
Распределение слова X в нормированных по длине текстах
Для оценки того, с какой долей вероятности слово Х окажется в определённом месте текста, построим гистограмму, где по горизонтали показана нормированная длина текстов, а по вертикали — количество появления в них слова X.
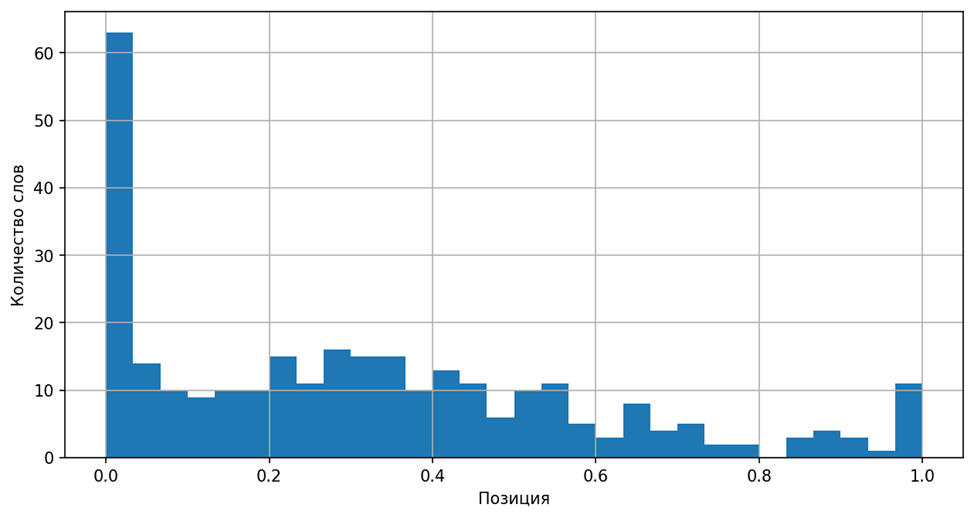
Количество раз, сколько слово X встретилось в разных частях текстов
Теперь можно с уверенностью утверждать, что в рассмотренных текстах слово Х имеет тенденцию к появлению в начале текста.
А что, если текстов тысячи?
Итак, мы посчитали количество появлений слова Х в разных местах текста, но как проделать такую же операцию с сотней или даже тысячей слов одновременно? Конечно, можно написать цикл в программе и получить множество графиков, как это сделал Макклюр, но как упорядочить их и найти слова, имеющие выраженную тенденцию к смещению в начало или конец текста?
Нужно найти какое-то решение, которое позволит нам упрощённо визуализировать множество графиков и избежать долгого рассматривания сотен гистограмм.
Для начала в целях наглядности превратим гистограммы в линейный график, проведя прямые между вершинами полученных колонок.
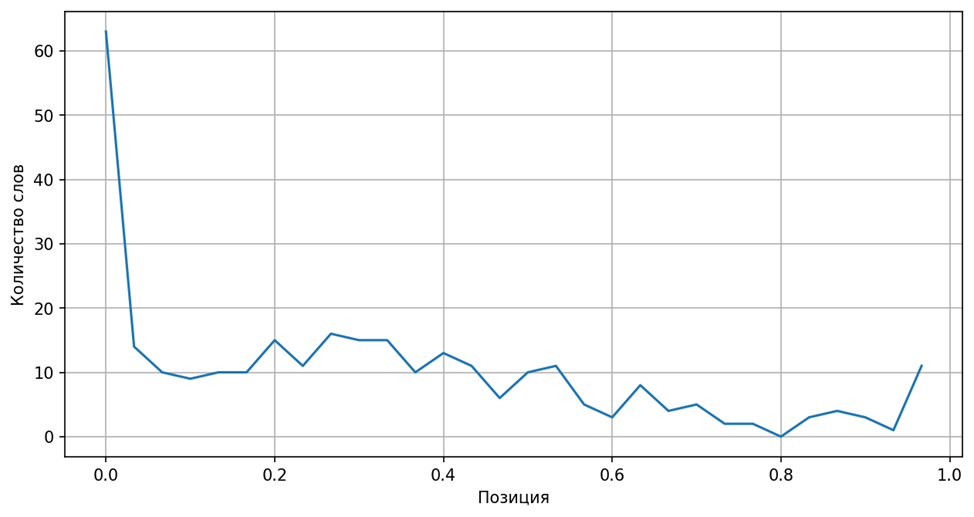
График распределения слова X на основе гистограммы выше
Рассмотрим результат подробнее. Если говорить на языке науки о данных, мы имеем дело с временными рядами, другими словами, с сериями «измерений» какой-либо величины, последовательных во времени. В нашем случае измеряемой величиной является количество появлений конкретного слова, изменяющееся относительно процесса повествования.
Временной ряд состоит из множества точек, однако если вдуматься, то для восприятия этого ряда такое количество точек избыточно. В первом приближении для обнаружения тенденции слова к появлению в завязке или в финале произведения достаточно простой линии тренда, которая не только покажет, растёт или падает количество употреблений выбранного слова по ходу развития сюжета, но и позволит проигнорировать избыточные колебания графика и шумы.
Она обозначена пунктирной линией на рисунке ниже.Линия тренда является обычной математической прямой, которую можно задать уравнением y = ax + b с двумя параметрами (коэффициентом наклона a и свободным членом b). Поэтому её можно однозначным образом отобразить как точку в двумерном пространстве, используя значения этих параметров a и b.
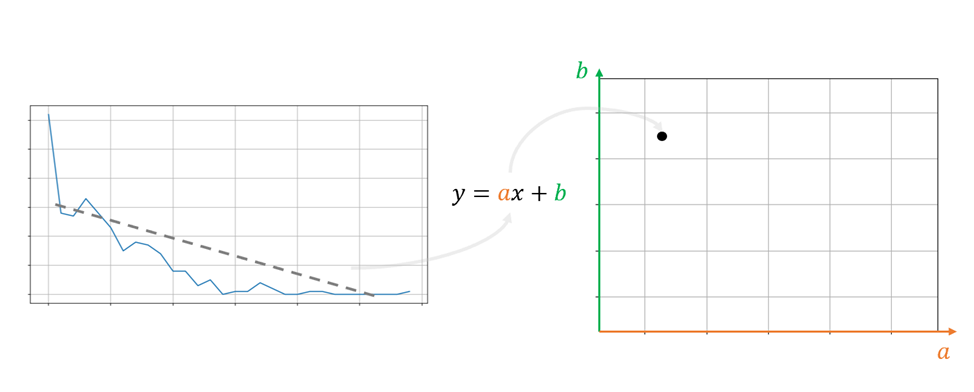
Схема построения графика
Таким образом у нас получилось «сжать» целый временной ряд до единственной точки, «выразив» в её положении важную для нас информацию.
Подумаем, как изменение коэффициентов a, b будет влиять на положение точки на получаемом графике.
Если прямая захватывает восходящий тренд временного ряда, её коэффициент наклона a будет положительным числом, а значит, точка сместится правее по горизонтальной оси. Если прямая захватывает нисходящий тренд, то её коэффициент наклона a будет отрицательным, следовательно, она сместится влево по этой оси. Стоит отметить, что при вычислении а каждый из графиков нормируется относительно вертикальной оси, так как значение имеет только форма кривой временного ряда, а не «высота» её положения.
Напротив, коэффициент b, или же свободный член, отвечает за то, насколько «высоко» лежит прямая, а значит, он реагирует на частотность слова, параллельно сдвигая все точки линии тренда вверх при увеличении своего значения. Исходя из этого, точки, обозначающие высокочастотные слова, будут расположены вверху, а точки, обозначающие низкочастотные слова, — внизу.
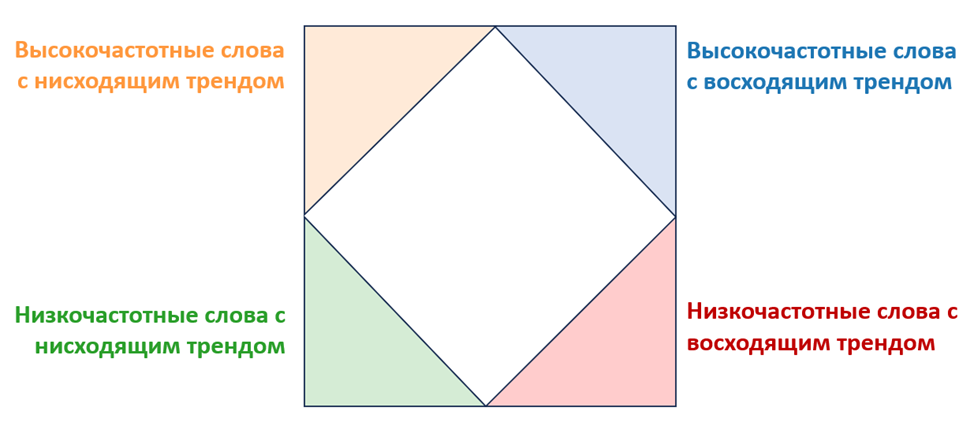
Схема расположения слов разной частотности
От теории к практике: распределение слов в произведениях русской литературы
Для исследования рассмотрим корпус русскоязычной художественной литературы, собранный в рамках проекта СОЦИОЛИТ [3]. Этот корпус включает в себя около 1000 произведений XVIII–XXI веков, начиная с «Бедной Лизы» Николая Карамзина и рассказов Николая Гоголя, заканчивая «Войной и миром» Льва Толстого и «Красным колесом» Александра Солженицына.
Сначала разобьём каждое из произведений на отдельные слова и проведём лемматизацию, приведя эти слова к начальной форме при помощи Python-библиотеки pymorphy2 [4].
Теперь можно построить описанный выше график и отобрать слова с тенденцией появляться в начале произведения или в его конце.
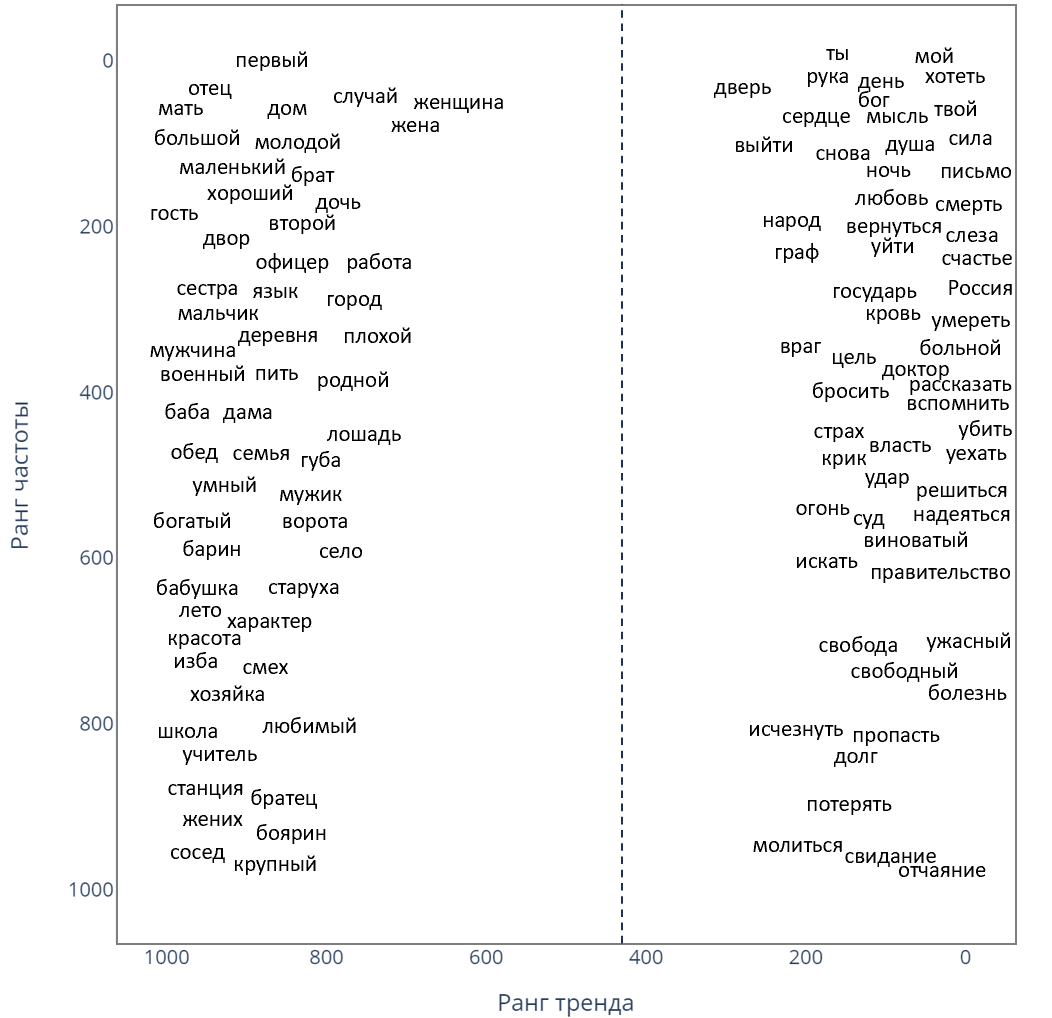
График частотности и местоположения слов в корпусе СОЦИОЛИТ
По левой половине графика можно заметить, что произведения чаще всего начинаются с описания «характеристик» героев, семейных обстоятельств и места жительства.
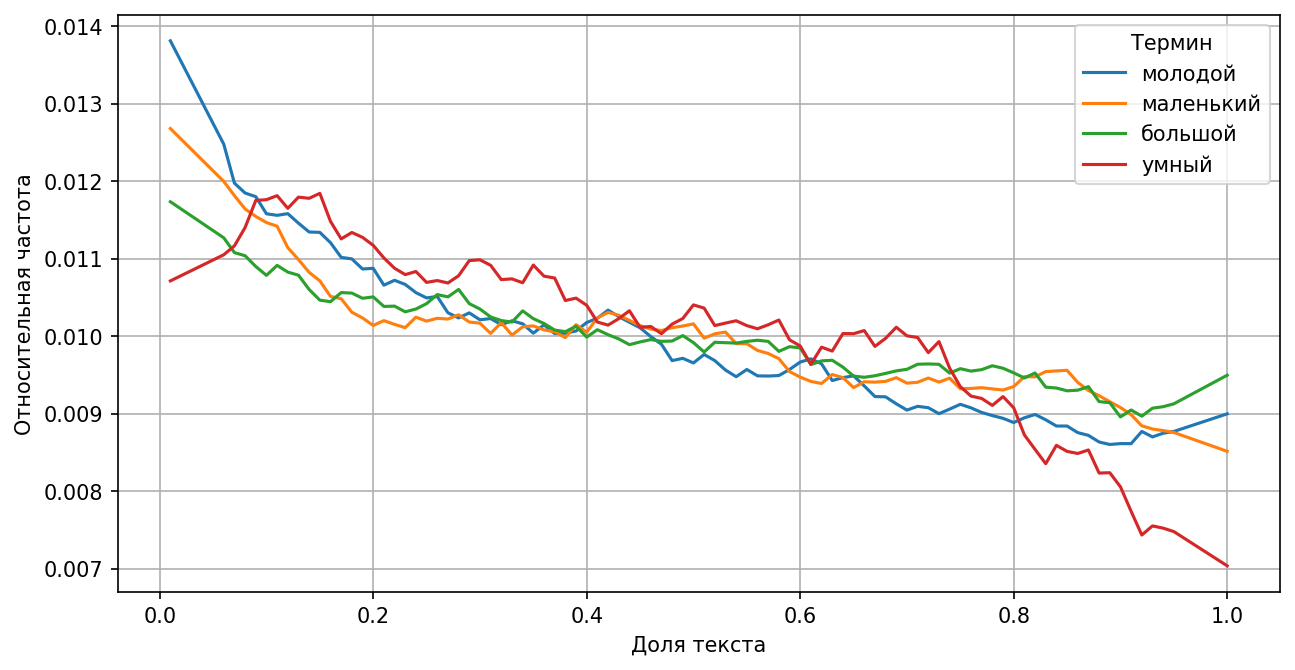
«Характеристики» героев наиболее типичны для начала историй
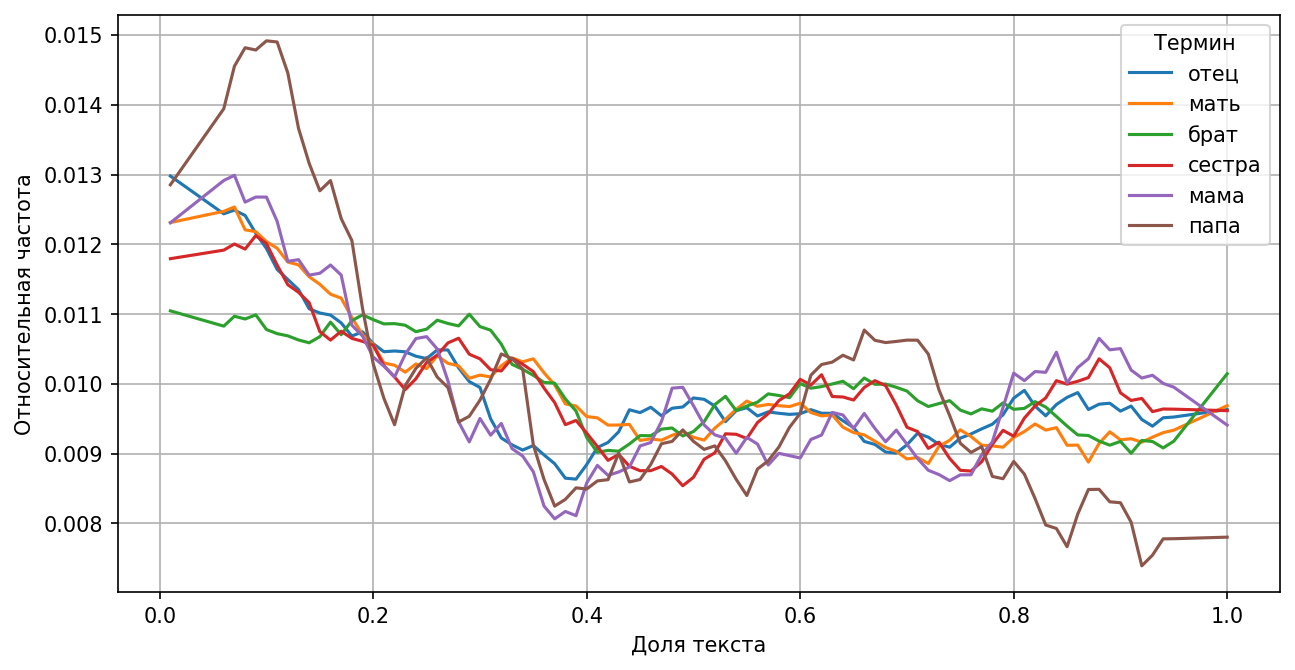
«Семейные» слова с большей долей вероятности встречаются в начале текста
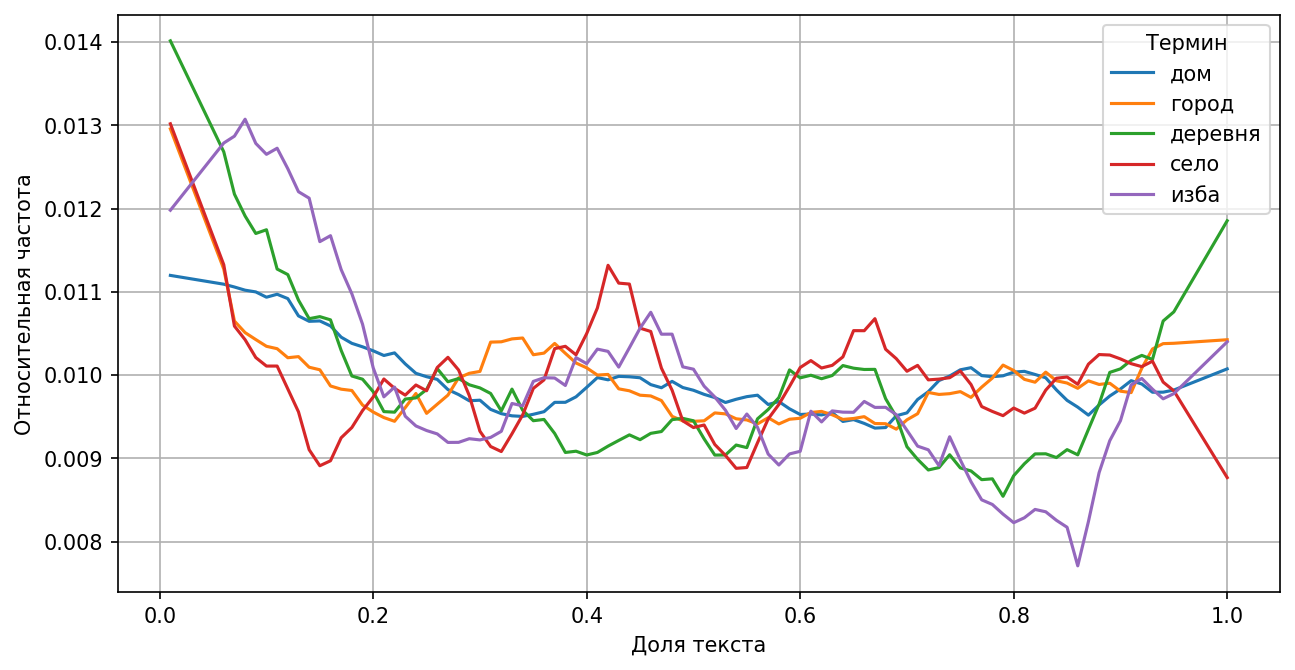
Слова, описывающие место жительства, тоже встречаются чаще в начале текстов
При этом весьма часто появляется слово «гость», с которым, вероятно, связаны известия, являющиеся фундаментом для завязки сюжета.
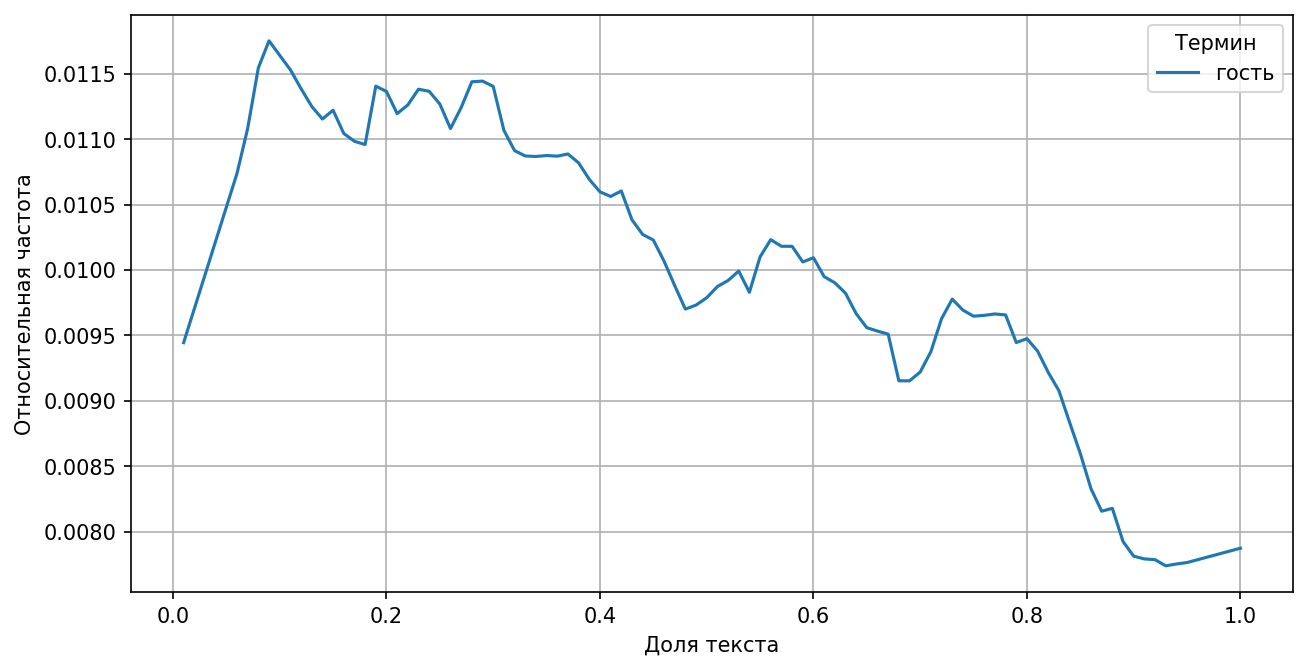
Относительная частота «гостя» в произведениях: слово встречается в начале текстов
В дополнение — достаточно часто в начале произведения можно встретить сцены употребления пищи.
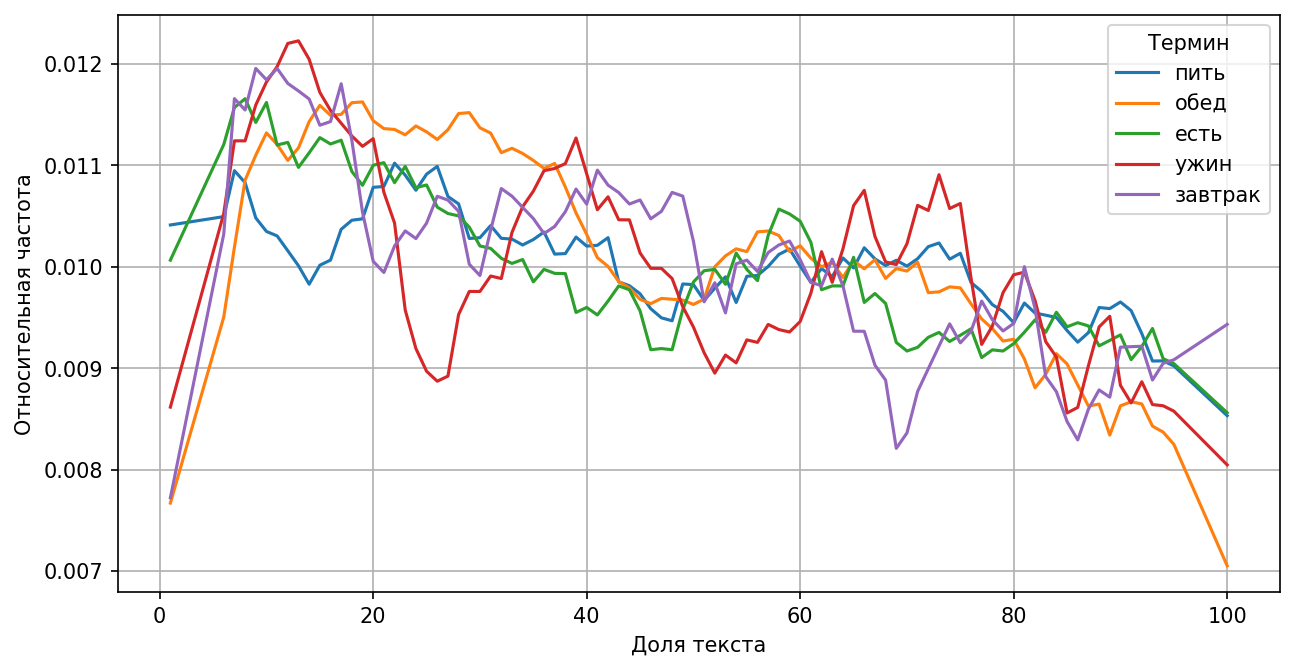
Относительные частоты слов, связанных с едой: герои чаще едят в завязке произведения
Развязка сюжета чаще всего ассоциируется с описанием нежных чувств либо, наоборот, с гибелью героя, болезнью или рассуждением о боге.
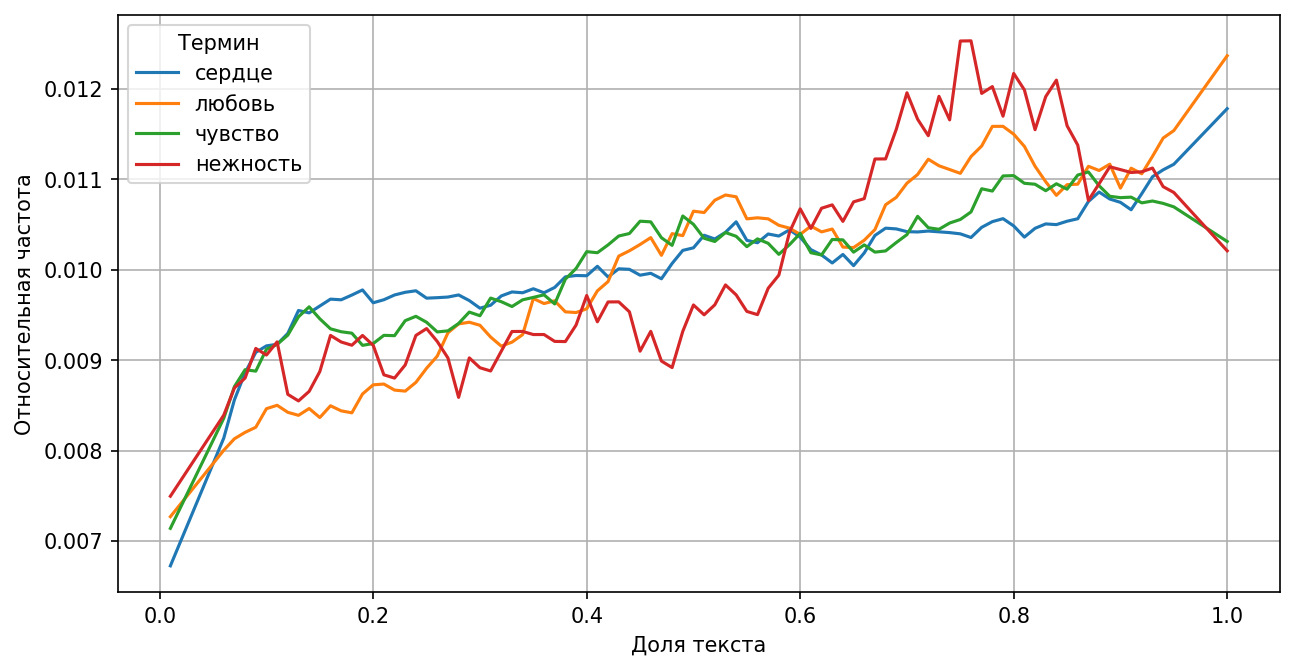
Любовь с большей долей вероятности случается в конце текста
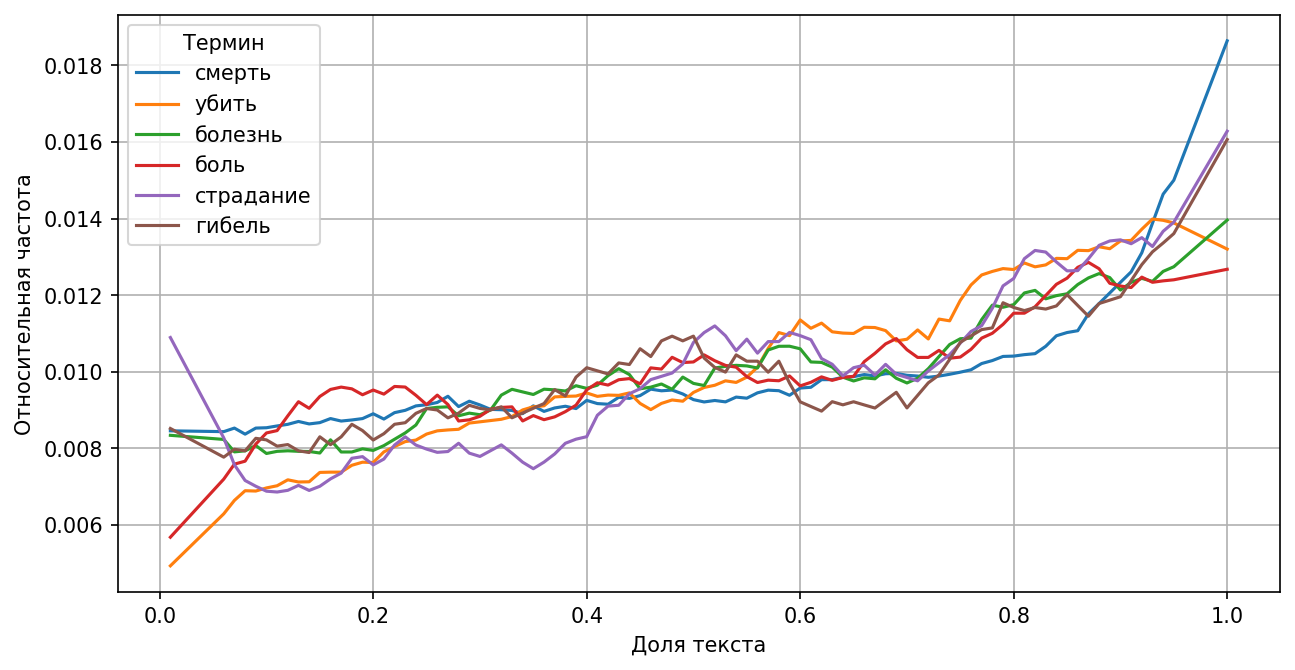
В конце историй часто кто-то умирает или страдает
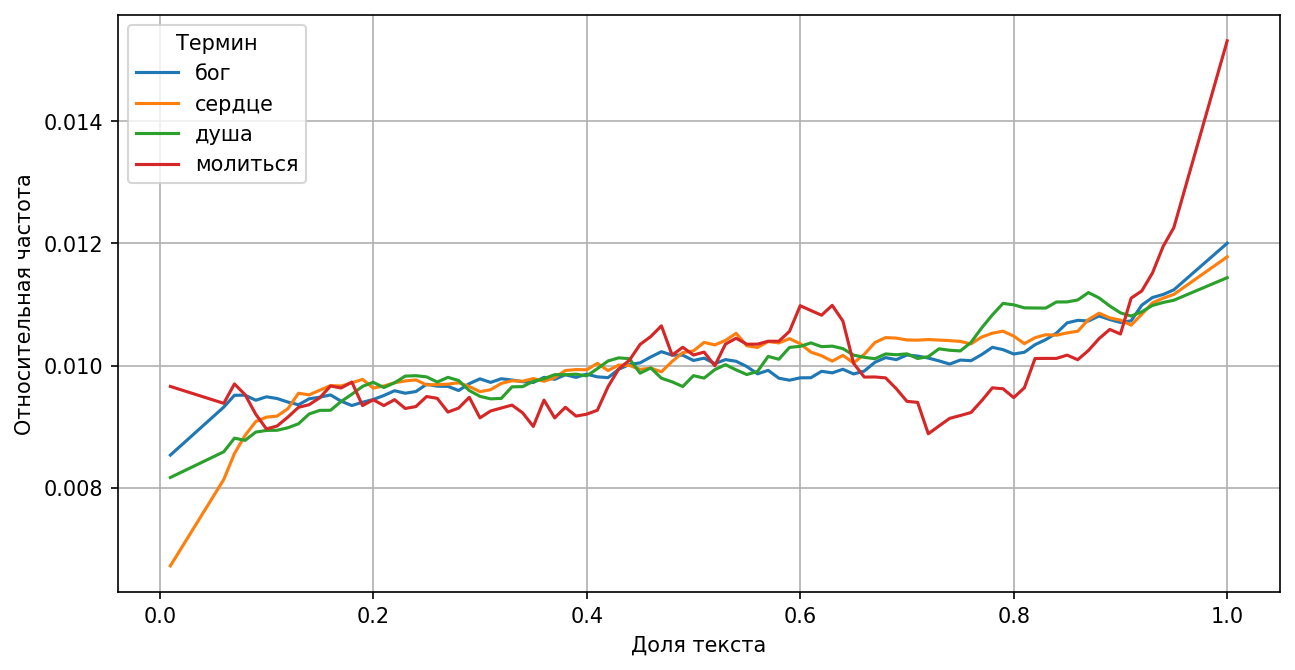
Слова, связанные с духовной жизнью, наиболее типичны для финала произведений
Также стоит отметить то, что персонажи ближе к финалу с большой вероятностью перейдут на ты [5].
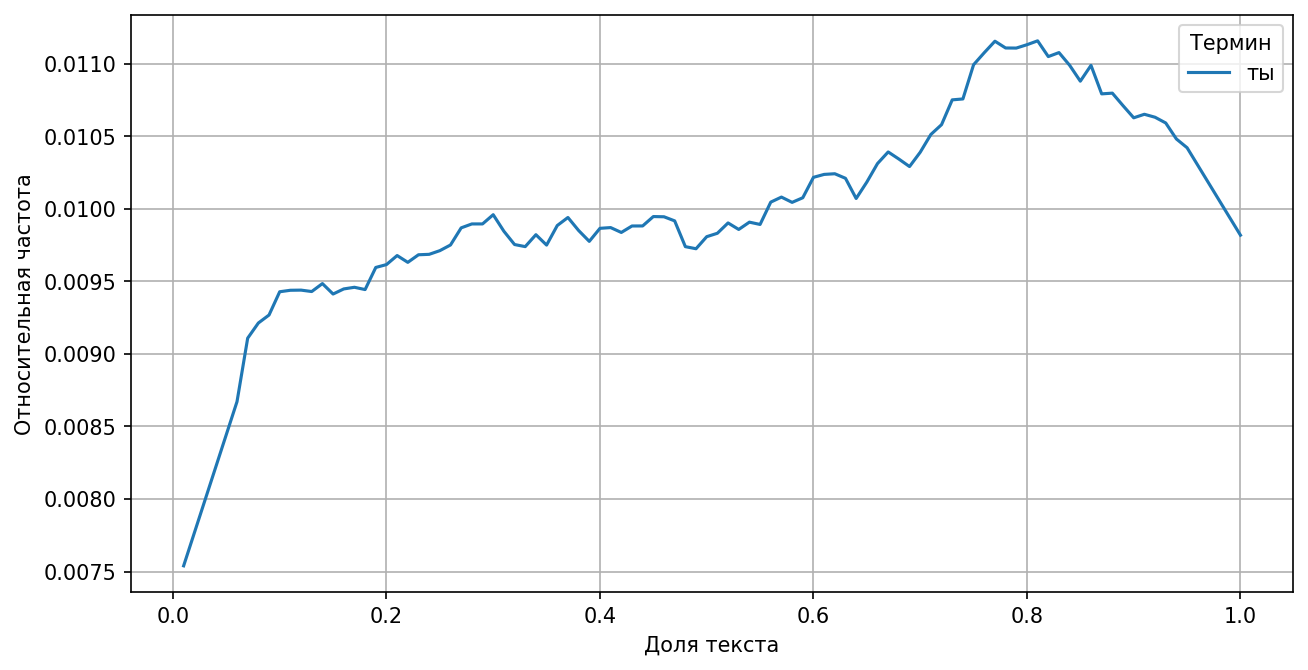
К концу истории герои часто переходят на ты
Заключение
В целом, если сравнивать наши результаты с результатами Макклюра, можно заметить, что полученные слова для русскоязычных текстов весьма схожи с результатами исследования для англоязычных текстов. Например, англоязычные произведения тоже часто начинаются с описания внешности героев, их семьи и места жительства (father, mother, son, farm, village), а вероятность погибнуть (death, kill, shot, grave) или найти свою любовь (heart, love, marriage) в конце произведения у героев гораздо выше. Удивительно, но даже на месте русскоязычного «гостя» выступает англоязычный stranger. Это выглядит так, что в европейском лингвокультурном коде есть единое понимание того, что может являться завязкой сюжета и наиболее интересно читателю, а что тяготеет к драматичному финалу или развязке произведения.
Источники
- Schmidt B. Fundamental plot arcs, seen through multidimensional analysis of thousands of TV and movie scripts [Электронный ресурс] // Sapping Attention. 2014. 16 декабря. URL: https://sappingattention.blogspot.com/2014/12/fundamental-plot-arcs-seen-through.html (дата обращения 03.09.2024).
- McClure D. Distributions of words across narrative time in 27,266 novels [Электронный ресурс] // LitLab Stanford. 2017. 10 июля. URL: https://litlab.stanford.edu/distributions-of-words-27k-novels/ (дата обращения 03.09.2024).
- Аналитическая онлайн-платформа СОЦИОЛИТ [Электронный ресурс] // СОЦИОЛИТ. URL: https://sociolit.ru/ (дата обращения 03.09.2024).
- pymorphy2 [Электронный ресурс] // PyPi. 2020. 26 сентября. URL: https://pypi.org/project/pymorphy2/.
- Лотман Ю. М. Формы обрацения на «Ты» и «Вы» в истории этикетной культуры [Электронный ресурс] // YouTube. URL: https://www.youtube.com/watch?v=IDijxP10RgM (дата обращения 03.09.2024).