
Как алгоритмы и люди по-разному измеряют «похожесть» артефактов и почему это важно
Материал подготовлен в соавторстве: Олег Лашманов (ЕУСПб) и Егор Блохин (ИИМК РАН)

В поисках похожего
Зайдем издалека. Когда мы что-то ищем — будь то в квартире или в своей памяти — мы невольно опираемся на образы, схожие с нашим внутренним представлением о предмете. Фактически у нас в голове есть обобщённая модель искомого, с которой мы бессознательно сравниваем всё, что попадает в поле зрения.
Пока мы ищем, скажем, забытые ключи в квартире — всё относительно просто. Квартира одна, ключи единственные, с узнаваемым брелоком в виде динозаврика. Мы быстро находим нужное, потому что ориентируемся по знакомым признакам. Но задача усложняется, если в одной руке у нас есть пример ключа, а перед нами — коробка, полная других ключей. Нужно найти точно такой же или хотя бы максимально похожий. Тут начинаются проблемы с перебором.
А теперь представим ещё более сложную ситуацию: мы помним, что где-то уже видели похожий ключ, но не можем точно вспомнить, где именно и при каких обстоятельствах. Это самая интересная и в то же время сложная задача — и именно она ближе всего к той, с которой сталкивается археолог.
Чтобы лучше понять, в чём суть этой проблемы, попробуем сначала разложить человеческий подход на составляющие и взглянуть на него с позиции машины.
Память — это граф
У нас есть память, в которой в том или ином виде хранятся образы предметов. Эти образы не изолированы — каждый связан с другими через ассоциации. А те, в свою очередь, ведут к следующим. В итоге возникает целая сеть связей — граф, где узлы представляют образы, а рёбра — ассоциации между ними. Проще говоря, это нечто вроде базы данных. Если попробовать мысленно представить предмет и начать раскручивать цепочку ассоциаций, вы заметите, как граф начинает разрастаться. Вы вспоминаете детали, о которых ещё секунду назад не думали. Однако такие графы сложно обрабатывать — как человеку, так и машине. Поэтому технически выбирают иной подход.
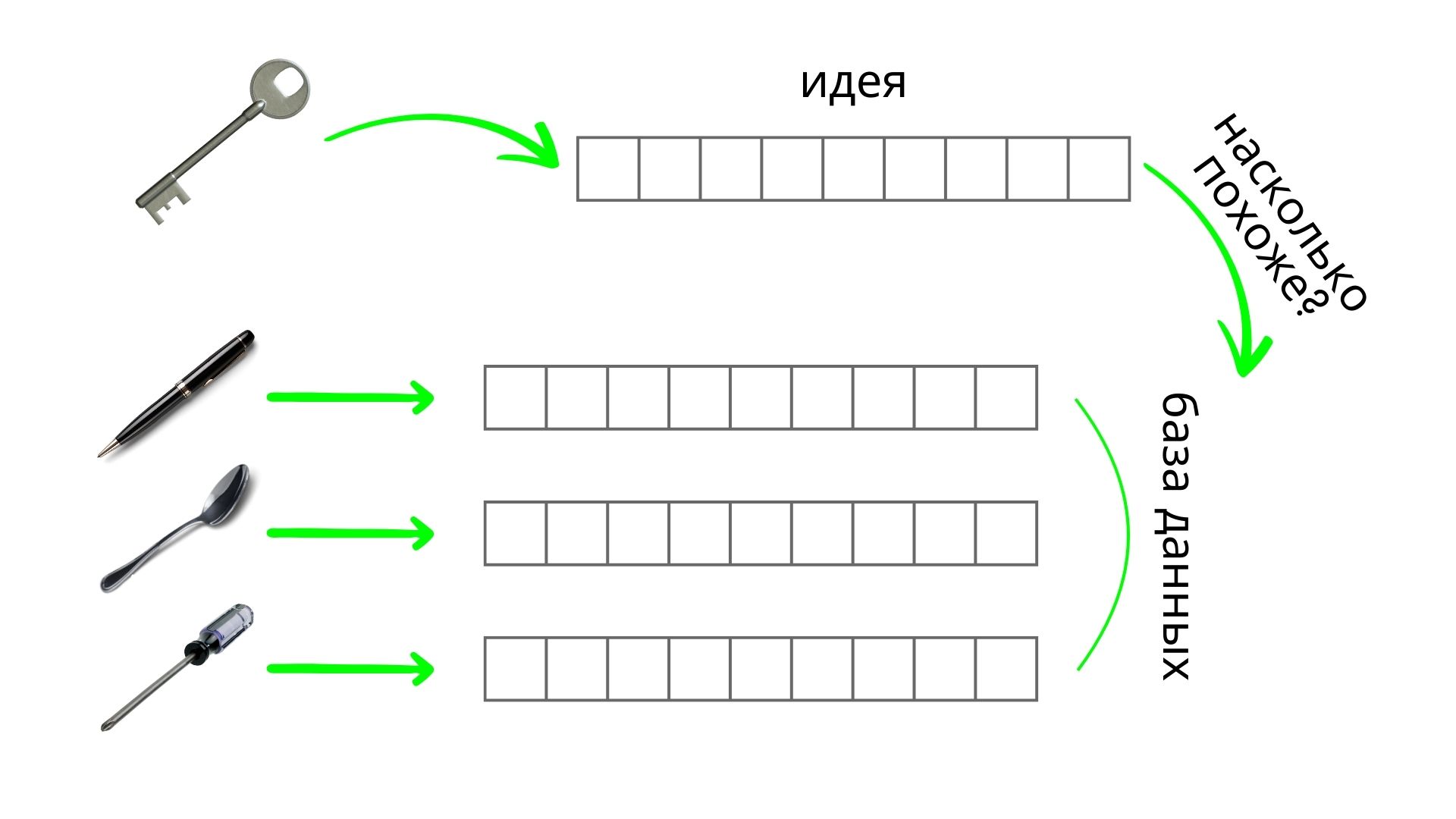
Что же на самом деле хранится в нашей «внутренней базе данных»? Это идеи, представления о предметах, явлениях, людях, питомцах и множестве других фактов. Как именно они представлены в мозге — вопрос всё ещё открытый. Но в технике этим абстрактным понятиям принято сопоставлять вектора — то есть просто наборы чисел. Один объект — один вектор. Эти вектора могут быть разной длины, но внутри конкретной системы длина фиксирована для всех. Важно, что каждый вектор в каком-то смысле «сжимает» смысл объекта в числовую форму.
Дальше всё выглядит просто: мы перебираем вектора в памяти и ищем похожие. Вроде бы на этом можно было бы и остановиться. Но главный вопрос — как мы определяем, что два объекта похожи? Что делает один вектор ближе к другому? Именно здесь начинается самое интересное. Эволюция устроила нас так, что мы воспринимаем вещь не только визуально. Мы связываем её с целым набором ощущений: тяжестью, фактурой, мягкостью, запахом, звуками окружающей среды. Всё это — часть образа, и всё это влияет на то, насколько предмет кажется нам «похожим» на другой.
Дисклеймер: я сознательно опускаю интуитивные и неосознанные способы поиска похожего в глубинах разума. Да, они быстрые, но слишком неточные, чтобы на них можно было опереться.
Контекст важнее формы
Археологи идут ещё дальше: у них есть не только физические признаки находки, но и контекст — слой земли, соседние объекты, культурная эпоха. Это добавляет новые уровни к понятию схожести.
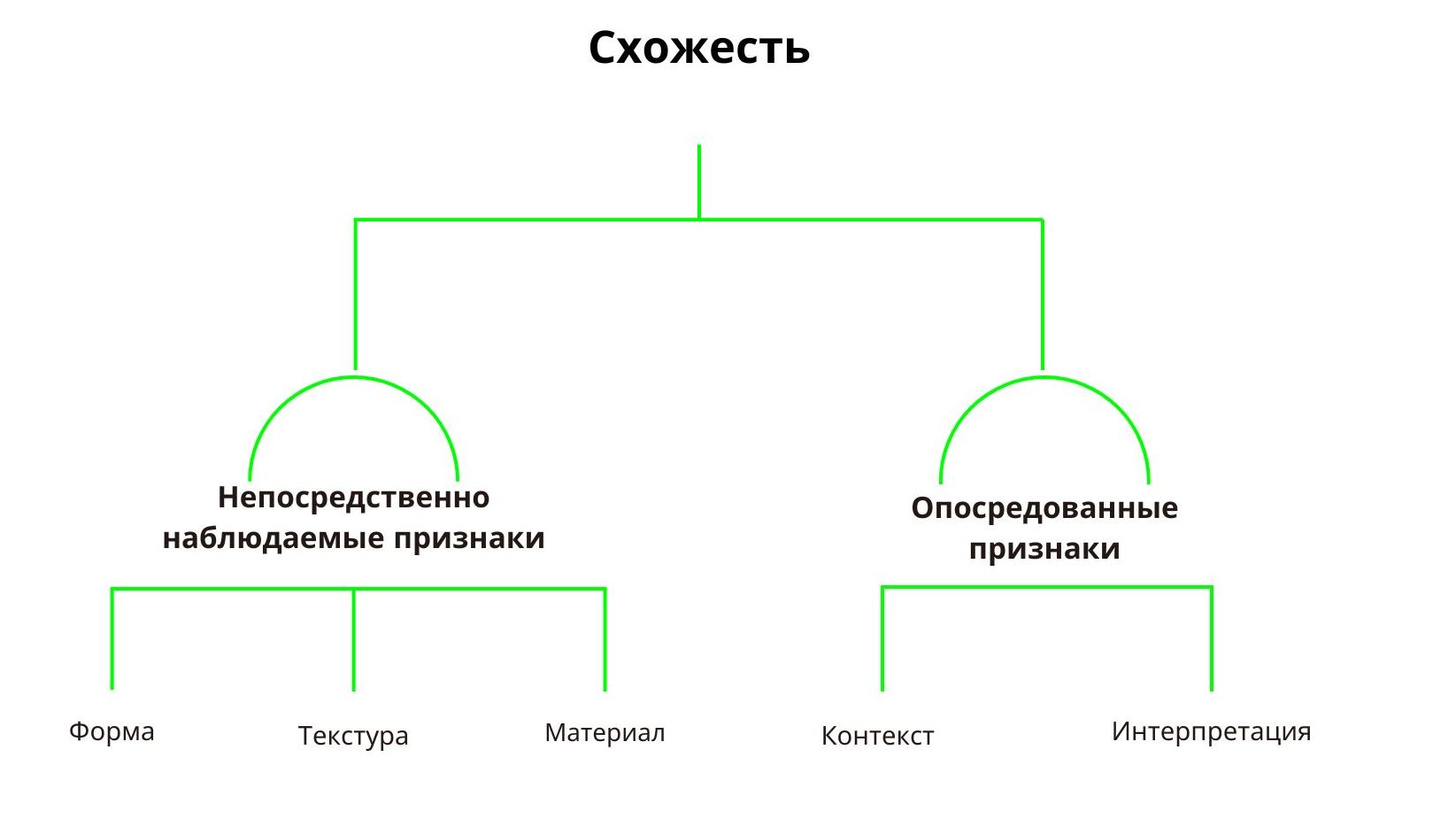
Если попытаться обобщить, можно выделить несколько основных критериев, по которым мы определяем, похожи ли объекты между собой. Это два типа признаков.
Непосредственно наблюдаемые признаки:




И опосредованные:


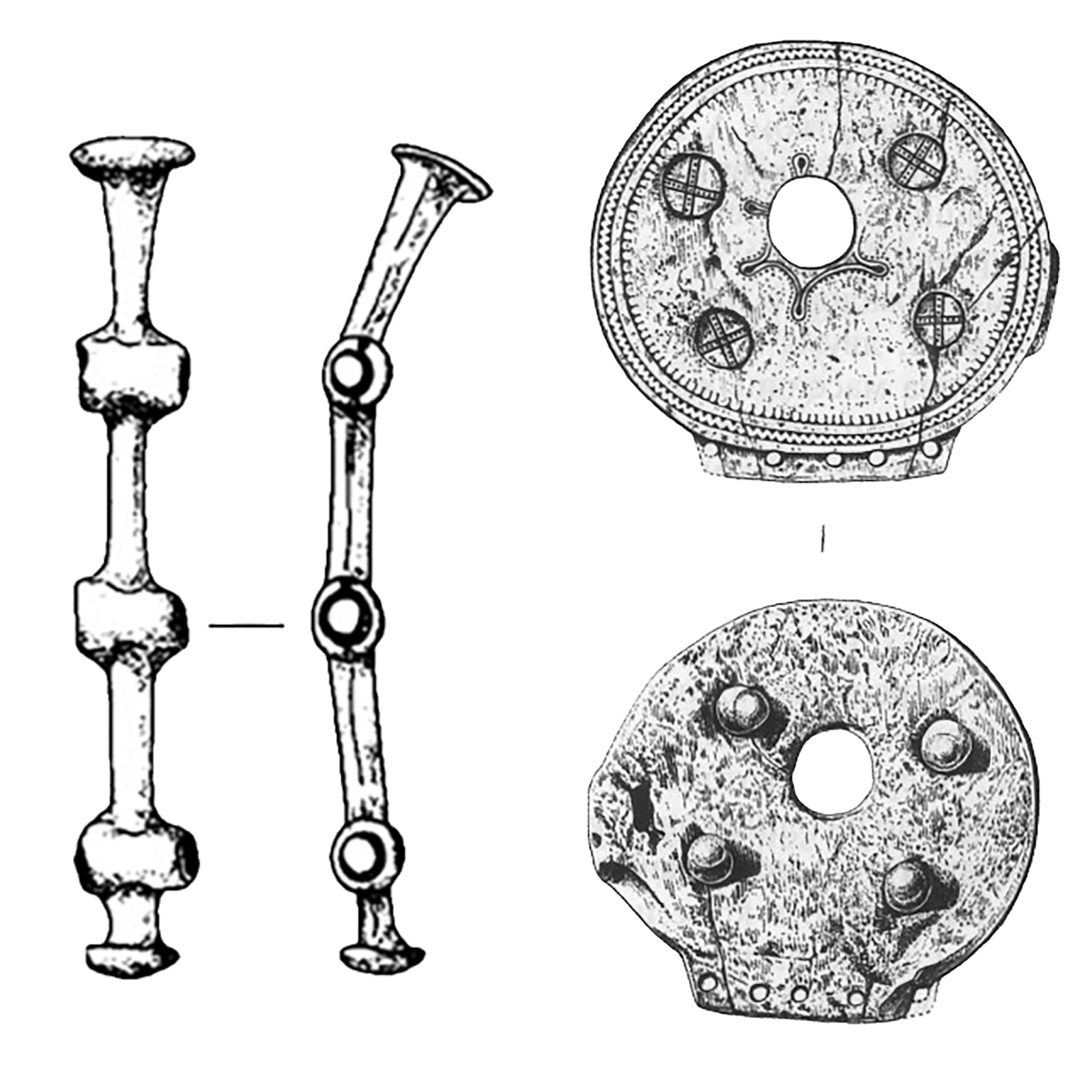
Рис. 2. Типичный бронзовый псалий раннего железного века и щитковый костяной псалий эпохи поздней бронзы.
Самое сложное заключается в том, что ни один из этих параметров нельзя заранее назвать решающим. Каждый раз, когда исследователь сталкивается с вопросом интерпретации находки, ему приходится вооружаться всеми этим критериями и принимать решение только по совокупности признаков. Какие из них окажутся наиболее значимыми — зависит от конкретной ситуации, контекста, опыта, уровня экспертизы и даже интуиции археолога.
Почему для машины два кувшина — это просто векторы
Компьютер, в отличие от человека, располагает лишь изображением объекта (или несколькими) и, возможно, текстовым описанием. На этом всё. Поэтому алгоритмы либо учатся на примерах, получая оценку схожести от людей, либо ограничиваются анализом визуального сходства. В случае визуального подхода каждое изображение представляется вектором, и самым простым способом сравнения становится расчёт косинусной дистанции между векторами. Очевидно, что ключевым становится вопрос: как именно извлекаются эти векторы?
Первый подход — использовать предобученные сверточные нейросети, например ResNet. Эти сети хорошо улавливают геометрические особенности: углы, точки, общие очертания. Однако, как видно из требований археологии, этого часто недостаточно — форма предмета далеко не всегда определяет его культурную принадлежность.
Второй подход — использовать мультимодальные модели, такие как CLIP, которые обучаются на парах «изображение — текст». Такой метод позволяет выучить семантическое представление об объекте, что гораздо ближе к задачам археолога. Преимущество здесь — в обобщённом восприятии мира, основанном на огромном объёме интернет-данных. Но это и слабое место: археологические описания сильно отличаются от повседневного языка. Эту проблему частично можно решить дообучением модели на специализированных парах «описание — изображение». Однако стоит учитывать, что у моделей семейства CLIP есть ограничения по длине текста.
Тем не менее, даже этот подход не способен заменить человека, который может взять предмет в руки, оценить его вес, фактуру, запах — или, как шутят археологи, даже попробовать на вкус. В разработанном в лаборатории «Искусство и искусственный интеллект» совместно с ИИМК РАН инструменте SIMILIS мы компенсируем недостаток сенсорной информации с помощью фильтров: по материалу, месту раскопок и текстовому описанию. Это позволяет значительно сократить количество ложных срабатываний и повысить точность поиска.
Загадочный колесничий
Существует и более серьёзный вызов. Археолог может распознать целое по фрагменту только учитывая сложную иерархию признаков и культурный контекст предмета. В археологии степей Евразии эпохи бронзы бытует термин «предметы неизвестного назначения» или ПНН. Обычно так археологи называют любой предмет, функция которого не ясна из его морфологии или контекста, но в этом случае привычное обобщающее словосочетание стало именем нарицательным.
Китайские и европейские археологи время от времени находили в памятниках конца эпохи бронзы и начала раннего железного века на территории Китая, Центральной Азии и Южной Сибири своеобразные крупные, характерно изогнутые предметы, изготовленные из бронзы. Долгое время назначение этих вещей оставалось дискуссионным, предполагались варианты от некоего атрибута шамана или ритуальной модели ярма до накладки на центральную часть лука и поясной пряжки. И только находка в 1953 году погребения колесничего, в оснащении боевой колесницы которого были зафиксированы два подобных предмета, однозначно связала эти странные артефакты с колесничным комплексом, а последующие открытия подтвердили это открытие.
Мы по-прежнему можем спорить об эволюции их точного назначения (в археологии это норма), но теперь однозначно связываем ПНН с колесницами поздней бронзы. Так, что даже если не находим в погребении следов самой колесницы, но только эту изогнутую пластину, то достаточно уверенно говорим о том, что она принадлежала колесничему и даже, возможно, символизировала колесницу.
Как же сможет интерпретировать ПНН нейросеть, не знакомая с историей их изучения и контекстами? Эксперимент с поиском в Google Картинках показывает: алгоритм чаще всего распознаёт бронзовые ПНН как… коромысла или крючки-вешалки.
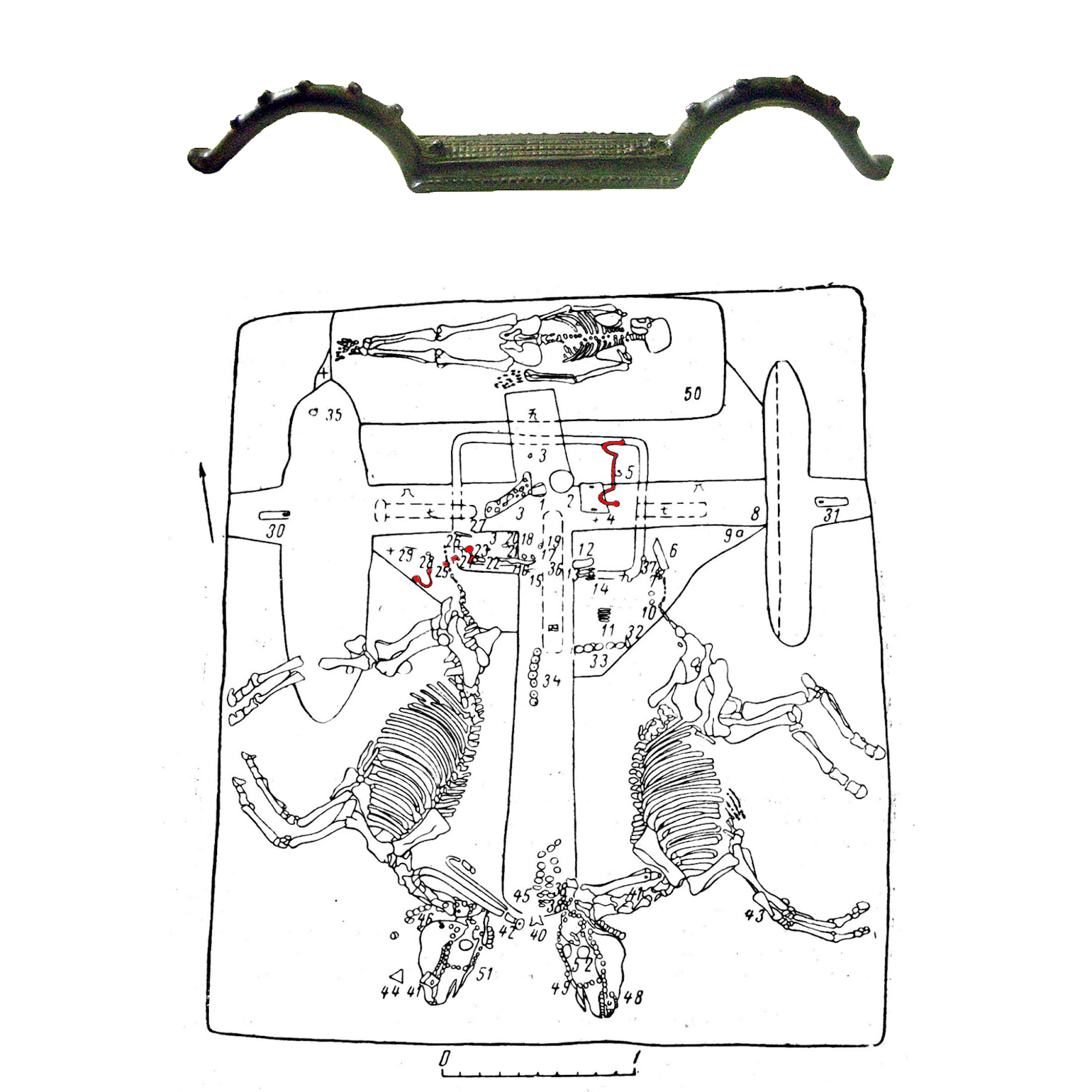
Рис. 3. Бронзовый предмет неизвестного назначения и его локализация в погребении колесничего.
Слепой интеллект
Как решать эту задачу? Сейчас к изображениям фрагментов добавляют метаданные — такие, как место находки или материал — и дообучают модели на текстовых описаниях вроде «колесничный комплекс», уточняя и дополняя формулировки. Но даже этого недостаточно. Такие меры не передают глубокие семантические связи, которые выстраивает археолог: технологии производства, миграции ремесленников, ритуальные функции. Без этих связей ИИ остаётся «слепым картографом», рисующим карты без понимания легенды.
Чтобы нейросети стали настоящими помощниками, им нужно научиться не только анализировать пиксели, но и читать контекст. Мы активно движемся в этом направлении, но для успеха нам необходима помощь пользователей. Идея простая: когда человек ищет предмет и отмечает его как схожий с другим, мы логируем запрос и выбранные объекты. Если пользователи начнут отмечать и отношения часть-целое как «похожие», мы сможем собрать датасет и приблизиться к решению задачи.
Традиционно такие связи пытаются устанавливать с помощью сопоставления ключевых точек на изображениях — характерных углов, пятен, контуров. Но в случае археологических артефактов этот метод может оказаться малоэффективным. Возможно, нам придётся разрабатывать совершенно новый подход. Один из вариантов — векторное представление. Как и ранее, мы будем стремиться к тому, чтобы векторы фрагмента и целого объекта находились рядом в векторном пространстве, если между ними существует связь.
Незаменимы
Так что пока никакой магии — только археологи способны справляться с задачей атрибуции артефактов. Но мы стараемся создать инструменты, которые облегчат этот процесс. Если вам интересно поучаствовать в решении настоящих археологических задач — присоединяйтесь к нам на SIMILIS.IO.



