
Под капотом у языкового корпуса: как нейросети и NLP-библиотеки используются в НКРЯ
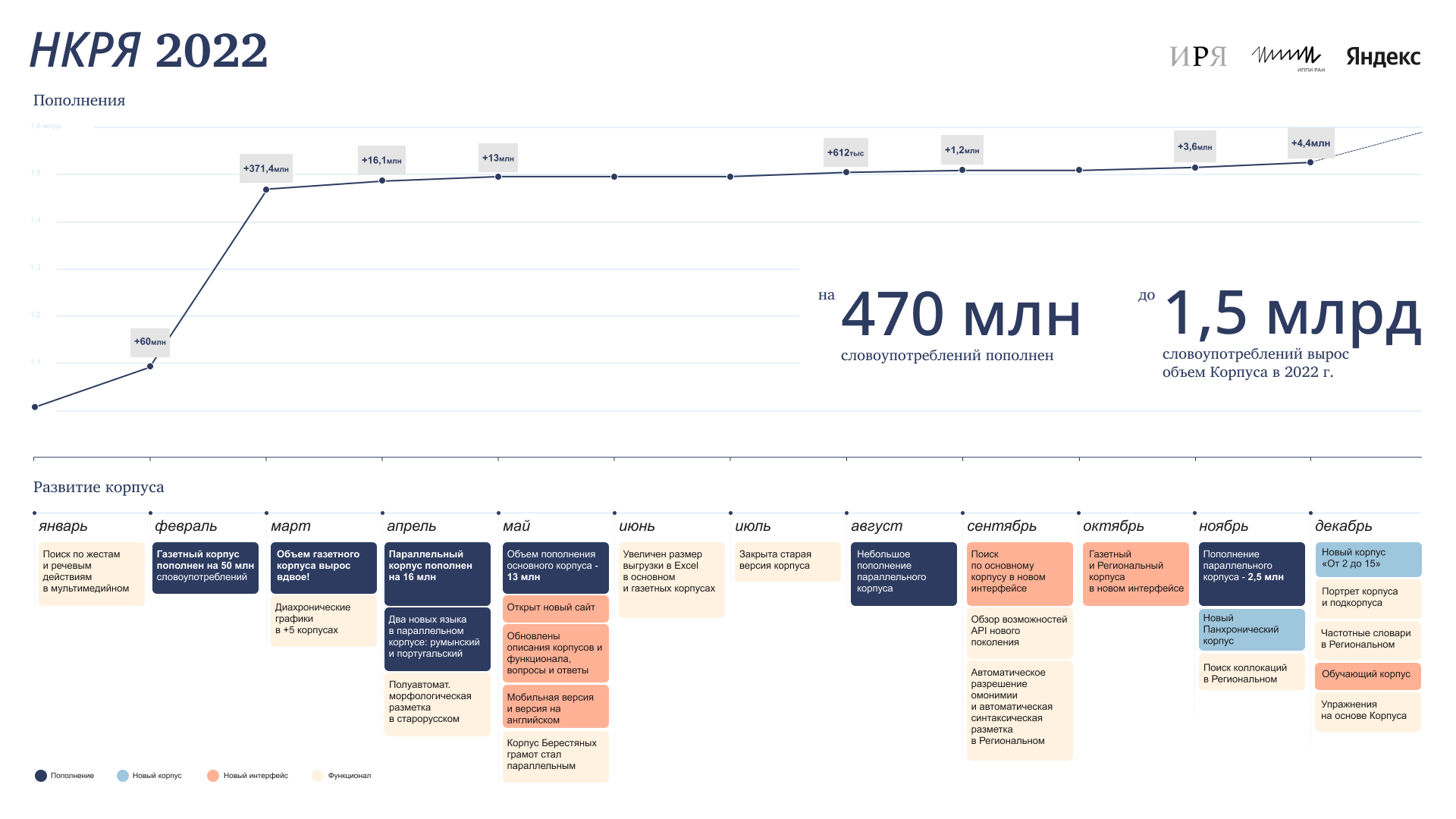
В Национальном корпусе русского языка за последние годы появилось много новых инструментов. Один из них — это «Портрет слова», который не только содержит информацию о морфологических признаках и морфемах каждого слова, но и дает представление, например, о его семантических соседях. В статье мы покажем, как пользоваться этим и другими заметными нововведениями, и расскажем, какие технологии за ними стоят.













{kind=link}