
Сегодня необычный пост. Этот пост — результат работы двух лабораторий I3 и ПАНДАН. Сама работа полностью вписывается в тематику лаборатории Искусство и искусственный интеллект, но ребятам с ПАНДАНа было очень интересно поработать с гравюрами, так родился этот проект. Далее будет текст ребят, которым мне бы очень хотелось поделиться с вами.
Шел пятый час просматривания проспектов, дворцов, каналов и видов городов. С каждым новым изображением на мониторе, гравюры становились все более похожими друг на друга. Казалось, что человеческий глаз просто не приспособлен для этого. Но ведь атрибуцией и анализом старинной графики XVlll века десятилетиями занимаются музейные сотрудники, а распознаванием и обработкой большого количества изображений и текстов – компьютеры. Рассказываем, как мы оказались погружены в цифровое наследие мастера рисунка и гравюры Михаила Махаева, и что из этого получилось.
Кто мы и зачем нам этот проект?
Мы – студенты и наставники программы ПАНДАН в Европейском университете в Санкт-Петербурге. Эта программа дает возможность исследователям гуманитарных и социальных наук изучить подходы и инструменты анализа данных, которые могут быть полезны для академической работы и в создании исследовательских проектов.
В рамках проекта мы работали с открытыми данными Государственного каталога Музейного фонда Российской Федерации, представленными на портале Министерства культуры, в котором содержатся сведения о более чем 30 миллионах музейных предметов из разных уголков России. При поиске какого-либо предмета в Госкаталоге мы часто сталкивались с большим количеством результатов поисковой выдачи – с репродукциями, повторениями, с предметами которые изданы большим тиражом, например, с марками, открытками, афишами.
Цель нашего проекта – научиться разделять предметы по степени опосредованности оригинала и по сюжету произведения. Разделение объектов по сюжетам и по степени опосредованности может облегчить поиск в Госкаталоге – плоской базе данных на настоящий момент.
Так как проверять гипотезы на сведениях о более чем 30 миллионах предметов крайне затруднительно, в рамках проекта мы решили ограничиться творчеством одного художника XVlll века, мастера рисунка и гравюры Михаила Ивановича Махаева.
Сбор данных
Для того чтобы познакомиться с творчеством Михаила Махаева мы изучили каталог “Петербург Михаила Махаева. Графика и живопись второй половины XVIII века”, изданный к одноименной выставке в Русском музее.
Чтобы получить выборку мы решили сформировать выгрузку всех объектов, которые содержат “Махаев” в названии, описании или в поле “автор”, а затем разметить и “почистить” вручную полученные данные.
Так у нас появилась выгрузка из 1724 предметов музейного фонда. Для того, чтобы использовать ее дальше, нам было необходимо разметить “степень опосредованности оригинала” для каждого предмета – сделать пометку о том, какое отношение к оригинальным работам, сделанным рукой Михаила Махаева, имеет каждый найденный нами предмет.
Иерархия или идея дерева
Техника изготовления гравюры хорошо укладывается в идею древовидной иерархии, потому что подразумевает разные степени опосредованности предметов по отношению к оригиналу – в одной связке существует оригинальный рисунок художника, доска, на которой вырезается непосредственно гравюра, разные тиражи отпечатков на бумаге с этой доски, открытки, книжные иллюстрации, фотонегативы гравюр. В первом приближении мы постарались выделить все возможные типы предметов, а затем поделить их на пять групп. Так мы создали “дерево”, на основании которого поделили все предметы по степени опосредованности к оригиналу и обозначили каждую степень числом от 0 до 5.
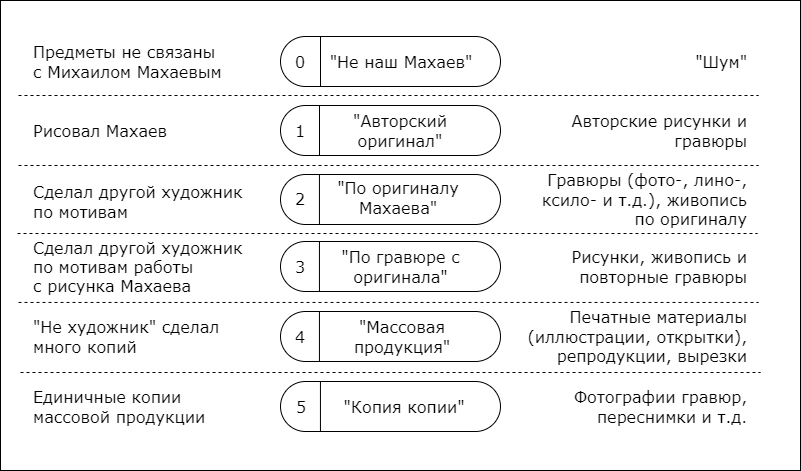
Ниже вы можете наблюдать распределение степени опосредованности среди всех объектов.

Здесь следует сделать несколько оговорок. Предложенное нами разбиение на категории не может быть однозначным, и мы и не стремились добиться строгого разделения, так как это не мешает общей идее, все равно позволяя достаточно эффективно ранжировать предметы, пусть и с некоторой допустимой неточностью.
Валидация разметки по дереву
После разметки степени опосредованности оригинала мы решили проверить, отражают ли обнаруженные нами степени скрытую в данных структуру. Эту задачу мы рассмотрели, как задачу классификации текстовых данных.
Корпус для обучения и тестирования классификатора был составлен из полей “Название”, “Автор” и “Материал, техника” всех 1724 предметов, которые мы извлекли из Госкаталога.
После формирования корпуса мы избавились от объектов, не имеющих отношение к произведениям Махаева (осталось 1383 объекта), три объединенных поля привели к нижнему регистру, лемматизировали слова, избавились от арабских и римских цифр, знаков пунктуации и стоп-слов, взятых из модуля Python Natural Language Toolkit. Векторизация была произведена без взвешивания слов с помощью метрики TF-IDF.
В качестве baseline-модели была использована мультиномиальная логистическая регрессия, которая дала средний ROC AUC на тестовой выборке, равный 97.1%, и средний ROC AUC на обучающей выборке, равный 100%.
Исходя из таких оценок можно утверждать, что предложенная нами иерархия хорошо описывает данные, что мы анализируем.
Разметка сюжетов
Возможность группировать предметы по принципу максимальной визуальной похожести, то есть по сюжетам, должна улучшить ранжирование выдачи при более детальных поисковых запросах. Для разметки нам было важно, чтобы для группы предметов, которые мы объединяли сюжетом, совпадала перспектива и ключевые объекты и таким образом было очевидно, что они созданы с одного оригинала.

Номер в Госкаталоге: 25575007

Номер в Госкаталоге: 21156566

Номер в Госкаталоге: 12531123

Номер в Госкаталоге: 26623781

Номер в Госкаталоге: 35308988
Для того чтобы составить список всех сюжетов, которые встречаются в творчестве Махаева мы просмотрели всю нашу выборку и выписали название каждого предмета, который встречали впервые. Затем полученный список мы проверили на рандомной выборке из ~250 предметов. В конце концов мы выделили 95 уникальных сюжетов, для каждого из которых есть хотя бы один предмет в нашей выборке.
В валидационную выборке, на которой мы проверяли результаты работы алгоритмов, оказались представлены только 70 из 95 сюжетов, которые вдобавок к этому представлены очень неравномерно. Поэтому оценки качества кластеризации на этой выборке не могут быть полностью перенесены на всю совокупность предметов.
Кластеризация предметов по сюжету на основе изображений
Для того чтобы составить список всех сюжетов, которые встречаются в творчестве Махаева мы просмотрели всю нашу выборку и выписали название каждого предмета, который встречали впервые. Затем полученный список мы проверили на рандомной выборке из ~250 предметов. В конце концов мы выделили 95 уникальных сюжетов, для каждого из которых есть хотя бы один предмет в нашей выборке.
В валидационную выборке, на которой мы проверяли результаты работы алгоритмов, оказались представлены только 70 из 95 сюжетов, которые вдобавок к этому представлены очень неравномерно. Поэтому оценки качества кластеризации на этой выборке не могут быть полностью перенесены на всю совокупность предметов.
Кластеризация предметов по сюжету на основе изображений
Уже первое беглое знакомство с визуальными данными выявило несколько проблем. Во-первых, один и тот же сюжет может иметь несколько вариаций — это может быть часть целого изображения, например правая или левая половина гравюры, полная версия которой занимает разворот альбома. Во-вторых, низкое качество и сложный для обработки фон изображений, представленных в Госкаталоге. В-третьих, гравюры могут быть очень похожи друг на друга, хотя для нашей классификации они представлены разными сюжетам. (Это субъективное наблюдение подтвердилось цифрами — на составленных вручную микро-выборках из двух сюжетов (около 20 объектов в каждой) среднее косинусное расстояние внутри сюжетов составило 0.8815, и 0.8826, а между сюжетами — 0.8229.)
И наконец, часть наследия Махаева составляют альбомы гравюр, в которых несколько сюжетов представлены на одном листе. Относительно таких объектов было сразу понятно, что удовлетворительно кластеризовать их на данном этапе проекта не получится, так как в наши планы не входила разработка инструмента для кадрирования изображений.
В нашей работе использовались следующие модели и алгоритмы:
- Для векторизации изображений связка пакет Torch + модель CLIP (Contrastive Language-Image Pre-Training), версия модели clip-vit-base-patch32.
- Валидационную выборку для сравнения работы алгоритмов кластеризации. Полную и очищенную выборку (без предметов, не относящихся к Махаеву)
- Алгоритм кластеризации DBSCAN, Kmeans (в том числе с установленными первоначальными центрами кластеров — эталонными изображениями сюжетов)
Оценка результатов работы алгоритмов основывалась на сочетании нескольких параметров:
- Оценки метрик на валидационной выборке (скорректированный коэффициент Рэндала (ARI), скорректированная взаимная информация (AMI), Однородность, Полнота и V-мера).
- Соотношения шум/количество кластеров.
- Субъективно “лучший” результате при визуализации кластеров. Для сравнения качества кластеризации на валидационной выборке было выбрано 6 сюжетов — два наиболее частых в валидационной выборке сюжет, два похожих друг на друга сюжета, но достаточно отличающиеся от других гравюр в выборке, один похожий на другие гравюры в выборке сюжет и один напротив очень отличающийся от всех прочих.
| Алгоритм | ARI | AMI | Однородность | Полнота | V-мера |
| DBSCAN | 0,224 | 0,437 | 0,545 | 0,811 | 0,652 |
| Kmeans C центройдами | 0,166 | 0,373 | 0,640 | 0,756 | 0,694 |
| Kmeans то же количество кластеров, без центройдов | 0,269 | 0,435 | 0,816 | 0,759 | 0,786 |
| Kmeans С лучшими показателями метрики без центройдов | 0,274 | 0,438 | 0,866 | 0,759 | 0,809 |
| Сюжет | Тип сюжета | DBSCAN | Kmeans |
| “План Петербурга 1753” | Карта . Частый в валидационной выборке | Выделил | Разбил на несколько |
| ”Проспект вниз по Неве реке между Зимним домом и Академией Наук” | Частый в валидационной выборке | Не вычленил как отдельный сюжет | Не вычленил как отдельный сюжет |
| «Эрмитаж. Екатерининский парк» | Похожи друг на друга | Объеденил в один | Выделил |
| «Охотничий павильон Монбижу в Зверинце. Екатерининский парк. Царское село.» | Выделил | ||
| «Ораниенбаум. Вид дворца на берегу Финского залива напротив Кронштадта» | Похожий на остальные | Выделил | Разбил на несколько |
| «Вид Троице-Сергиевой пустыни с тезисом в честь Екатерины II» | Отличающийся от остальных | Выделил | Выделил |
Можно сделать выводы, что DBSCAN дает лучший результат в случае планов и карт (объединяет в один сюжет различные части таких изображений). Kmeans лучше ”видит” небольшие вариации изображений.
Для классификации используем результаты работы обоих алгоритмов:
- Результаты работы DBSCAN на очищенной выборке
- Результаты работы Kmeans с количеством классов 93 на очищенной выборке

Кластеризация предметов по сюжету на основе текстовых данных
Само составление корпуса для обработки алгоритмом кластеризации уже было нетипичной задачей. Было решено исключить из поля “Название” все те слова, что содержатся в полях “Материал, техника”, “Автор”, “Период создания” (там нередко указывается именно год создания) и “Типология” (сюжет никак не связан с типом предмета). Также из поля были удалены арабские и римские цифры, знаки пунктуации. Размер корпуса составил 1383 документа (без тех объектов, которые не имеют отношения к произведениям Михаила Махаева). Из них для 258 документов сюжет был известен заранее.
Вдобавок к рассмотрению вариантов с включением/исключением стоп-слов из названия, мы также решили рассмотреть разные варианты отбора переменных и уплотнения векторного пространства. В качестве способов уплотнения векторного пространства использовались RUBERT и Latent Semantic Analysis, а в качестве способов отбора переменных использовали фильтрацию по документной частотности первоначальной матрицы и отбор по косинусному расстоянию уплотненных векторов переменных, полученных благодаря алгоритму K-means bag-of-words (BOW). В качестве алгоритмов кластеризации на текстовых данных мы также рассмотрели Kmeans и DBSCAN.
Ниже представлены лучшие результаты для двух алгоритмов кластеризации:
1) K-means с отбором переменных во взвешенной матрице через K-means BOW (уплотнение векторов до их длины в 130) и последующим уплотнением отфильтрованной взвешенной матрицы с помощью LSA до 30 векторов;
2) DBSCAN с максимальным радиусом соседства 0.646 и минимальным количеством соседей 3, которому на вход была дана уплотненная LSA до 100 компонентов невзвешенная матрица, из которой были удалены леммы, которые встречаются в более, чем 27% документов. Лучший результат DBSCAN обнаружил 95 кластеров, определив как шум 195 точек.
| Алгоритм | ARI | AMI | Однородность | Полнота | V-мера | Оценка Фаулкса-Маллоуза |
| k-means | 0,465 | 0,599 | 0,889 | 0,816 | 0,851 | 0,493 |
| DBSCAN | 0,336 | 0,517 | 0,779 | 0,802 | 0,79 | 0,36 |
Ниже представлены лучшие результаты для уплотнения векторного пространства с помощью RUBERT, кластеризации с удалением из документов стоп-слов (использовался тот же список стоп-слов, что и при подготовке корпуса для классификации) и варианты обработки и кластеризации Kmeans и DBSCAN для которых переменные не отбирались, а пространства не были уплотнены.
| Алгоритм | Векторизация | Обработка | Верхний потолок документной частоты | ARI | AMI | Однородность | Полнота | V-мера | Оценка Фаулкса-Маллоуза |
| k-means | без взвешивания | удаление стоп-слов, LSA | 0.19 | 0.456 | 0.576 | 0.891 | 0.806 | 0.846 | 0.492 |
| k-means | RUBERT | 0.273 | 0.405 | 0.82 | 0.747 | 0.782 | 0.302 | ||
| k-means | без взвешивания | 0.41 | 0.571 | 0.877 | 0.808 | 0.841 | 0.430 | ||
| DBSCAN | без взвешивания | удаление стоп-слов | 0.192 | 0.417 | 0.629 | 0.782 | 0.697 | 0.265 |
Так как вариация K-means была наилучшей по оценкам, то мы решили продемонстрировать работу классификатора на кластерах, выделенных этой вариацией K-means. Классификатор был кросс-валидирован, фолдами в данном случае были кластера сюжетов.
Как итог, в качестве алгоритма кластеризации объектов по сюжетам на текстовых данных предлагается K-means с отбором переменных во взвешенной матрице через K-means BOW (уплотнение векторов до их длины в 130) и последующим уплотнением отфильтрованной взвешенной матрицы с помощью LSA до 30 векторов.
Результаты
Кластеризация изображений методами компьютерного зрения показывает оценки метрики несколько хуже, чем кластеризация по текстам, но при этом позволяет выявить схожесть предметов, которые невозможно выделить при анализе текстовых данных. Например, так мы смогли объединить в один сюжет гравюру и медные доски, с которых она была напечатана или вычленить разные части одной карты или плана. Поэтому для дальнейших исследований нам кажется важным использовать одновременно оба подхода – анализ как текстовых данных, так и изображений. Обучение модели CLIP именно на гравюрах в будущем может улучшить результаты и собранный нами корпус можно использовать в качестве данных для обучения. Стоит также сделать важное замечание, о том, что результаты нашей работы лишь потенциально масштабируемы. В Госкаталоге много данных, эти данные очень разные. Очевидно, что при масштабируемости подходов на всё множество музейных объектов потребует более изощренных методов обработки и анализа данных. К тому же, иерархия и количество степеней опосредованности оригинала и список сюжетов может претерпеть изменения, так как мы выделили степени только на одном очень маленьком подмножестве. Тем не менее мы убеждены, что предложенный нами подход может быть полезен тем командам, которые также работают над поисковыми системами для музейных предметов. А самое главное – он может принести пользу исследователям, сделав их кропотливый труд чуточку удобнее.
Мы хотели бы выразить особую благодарность:
– Юлии Ходько за ее невероятно полезные экспертные комментарии, которые не давали нам сбиться с пути;
– Наставникам проекта Ольге Тушкановой и Олегу Лашманову, которые научили нас решать любые задачи даже в самые сжатые сроки;
– Всем, кто создает программу ПАНДАН, потому что без них ничего бы этого не было.
Команда студентов:
- Роман Лисюков
- Кристина Резникова-Левитт
- Анна Козлова
Руководители проекта:
- Ольга Тушканова
- Олег Лашманов



