Всем привет!
Лаборатория “Искусство и искусственный интеллект” продолжает повествование. Чтобы разобраться, как методы машинного обучения могут решать культурологические задачи, ближайшую серию статей мы посвятим основным понятиям в области искусственного интеллекта.
Разберем работу машины на Сонях. Предположим, Соня хочет купить автомобиль и считает, сколько денег ей нужно для этого накопить. Она пересмотрела несколько объявлений в интернете и увидела, что новые автомобили стоят около $20 000, годовалые — примерно $19 000, двухлетние — $18 000 и так далее. В уме Соня-аналитик выводит формулу: адекватная цена автомобиля начинается от $20 000 и падает на $1000 каждый год, пока не достигнет $10 000.
Только что Соня сделала то, что в машинном обучении называют регрессией — предсказала цену по известным данным. Люди делают это постоянно, когда считают, почём продать старый макбук или сколько шашлыка взять на дачу (моя формула — 600 грамм на человека в сутки). Было бы очень удобно иметь формулу под каждую проблему на свете. Но взять те же цены на автомобили: кроме пробега, есть десятки комплектаций, разное техническое состояние, сезонность спроса и еще столько неочевидных факторов, которые Соня, даже при всём желании, не удержала бы в голове. Люди тупы и ленивы — надо заставить вкалывать роботов. Давайте заставим машину посмотреть на наши данные (все параметры и стоимости автомобилей), найти в них закономерности и предсказывать для нас ответ. Внезапно оказывается, что в итоге машина стала находить даже такие закономерности, о которых люди не догадывались.
Так родилось машинное обучение.
Три составляющие обучения
Цель машинного обучения — предсказать результат по входным данным. Чем разнообразнее входные данные, тем проще машине найти закономерности и тем точнее результат. Когда создавали автопилотируемые автомобили, все производители боролись за сбор датасета в миллион миль. Однако, быстро оказалось, что проехать миллион миль по солнечной Калифорнии недостаточно, чтобы уверенно ехать в заснеженной Сибири. Именно поэтому мы говорим о вариативности.
Итак, если мы хотим обучить машину, нам нужны три вещи:
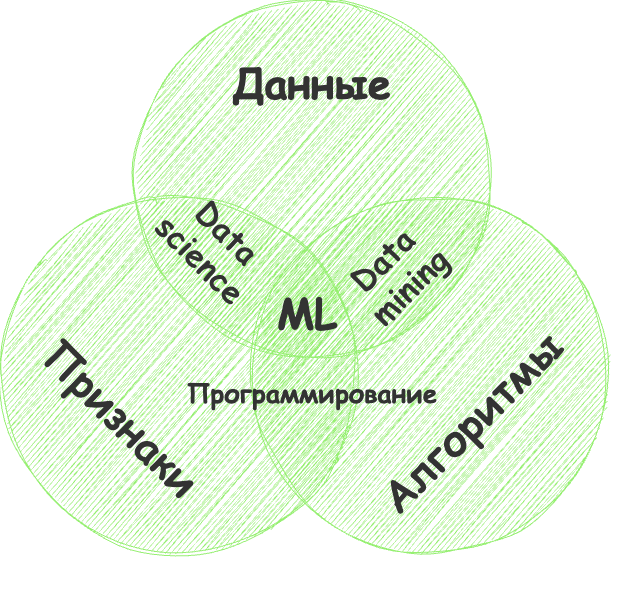
Данные
Хотим определять спам — нужны примеры спам-писем; предсказывать курс акций — нужна история цен; узнать интересы пользователя — нужны его лайки или посты. Данных нужно как можно больше (но важна еще и вариативность). Десятки тысяч примеров — это самый злой минимум для отчаянных.
Данные собирают как могут. Кто-то вручную, при помощи анататоров — получается дольше, меньше, зато без ошибок. Кто-то полностью автоматически — просто сливает машине всё, что нашлось, и верит в лучшее. Самые хитрые, типа Гугла, используют своих же пользователей для бесплатной разметки. Вспомните ReCaptcha, которая иногда требует «найти на фотографии все дорожные знаки» — это оно и есть.

За хорошими наборами данных (датасетами) идёт большая охота. Крупные компании, бывает, раскрывают свои алгоритмы, но дата-сеты — крайне редко. Если никто не знает, на каких данных вы учились, то и правообладателям сложнее предъявить к вам претензии (привет, openAI).
Признаки в данных
Мы называем их фичами (features), так что ненавистникам англицизмов придётся страдать. Фичи, свойства, характеристики, признаки — ими могут быть пробег автомобиля, отдельные пиксели изображения, направления мазков на холсте, пол пользователя, цена акций, даже счетчик частоты появления слова в тексте может быть фичей. Машина должна знать, на что ей конкретно смотреть. Хорошо, когда данные просто лежат в табличках — названия их колонок и есть фичи. А если у нас сто гигабайт картинок с котами или яблоками? Когда признаков много, модель работает медленно и неэффективно. Зачастую отбор правильных фич занимает больше времени, чем всё остальное обучение. Но бывают и обратные ситуации, когда кожаный мешок сам решает отобрать только «правильные», на его взгляд, признаки и вносит в модель субъективность — она начинает дико врать.
Алгоритм
Одну задачу можно решить разными методами примерно всегда. От выбора метода зависит точность, скорость работы и размер готовой модели (что такое размер мы поговорим в следующий раз). Но есть один нюанс: если данные плохи, даже самый лучший алгоритм не поможет. Не зацикливайтесь на процентах – лучше соберите побольше данных. Одна из основополагающих книг по машинному обучению “Machine Learning Yearning”, Andrew NG, в кратце сводится именно к этому: если у вас проблемы с обучением, скорее всего проблема в данных.
Обучение VS Интеллект
Однажды в одном хипстерском издании я видел статью под заголовком «Заменят ли нейросети машинное обучение». Пиарщики в своих пресс-релизах обзывают «искусственным интеллектом» любую линейную регрессию, с которой уже дети во дворе играют. Давайте решим этот вопрос раз и навсегда: искусственный интеллект — название области человеческого знания. Да, не очень хорошо названный, но все же.
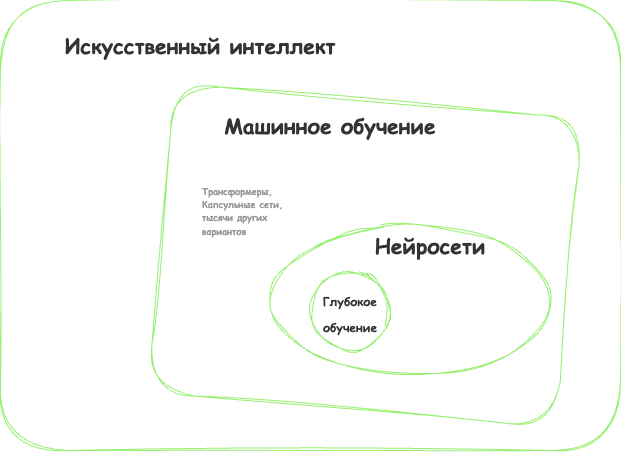
Искусственный интеллект — название всей области, как биология или химия.
Машинное обучение — это раздел искусственного интеллекта. Важный, но не единственный.
Нейросети — один из видов машинного обучения. Популярный, но есть и другие, не хуже.
Глубокое обучение — архитектура нейросетей, один из подходов к их построению и обучению. На практике сегодня мало кто отличает, где глубокие нейросети, а где не очень. Говорят название конкретной сети, и всё.
Вот что машины сегодня умеют, а что не под силу даже самым обученным:
Машина может:
- предсказывать;
- запоминать;
- воспроизводить;
- искать похожее;
- выбирать лучшее.
Машина не может:
- создавать новое (с оговорками);
- резко поумнеть;
- выйти за рамки задачи;
- убить всех людей (с оговорками 🙂 ).
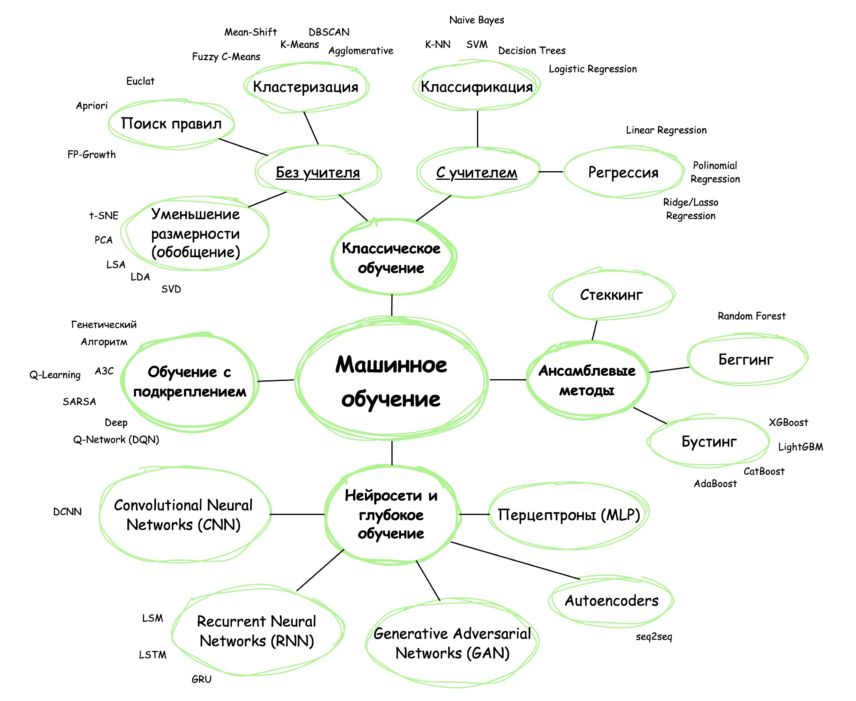
Мир машинного обучения велик и разнообразен. В следующем выпуске мы разберем основные направления машинного обучения и популярные алгоритмы в соответствии с типами задач.
В этом году Школа искусств и культурного наследия Европейского университета запустила магистерскую программу “Музейные исследования и кураторские стратегии”. Это первая в России программа, которая объединяет фундаментальные подходы университетского обучения и новейшие достижения в области высоких технологий на базе музея. Для желающих глубже изучить применение технологических инструментов в искусствоведческой практике рекомендуем трек «Музейные исследования и компьютерные науки», где упор делается на инструментах обработки изображений и естественного языка, визуализации и разметки данных. Подробнее о программе.



