
N-грамма — это просто последовательность из n элементов (звуков, слогов, слов или символов), идущих в каком-то тексте подряд. На практике чаще имеют в виду ряд слов (реже — символов). Последовательность из двух элементов называют биграмма, из трёх элементов — триграмма.
Например, вот N-граммы слов:
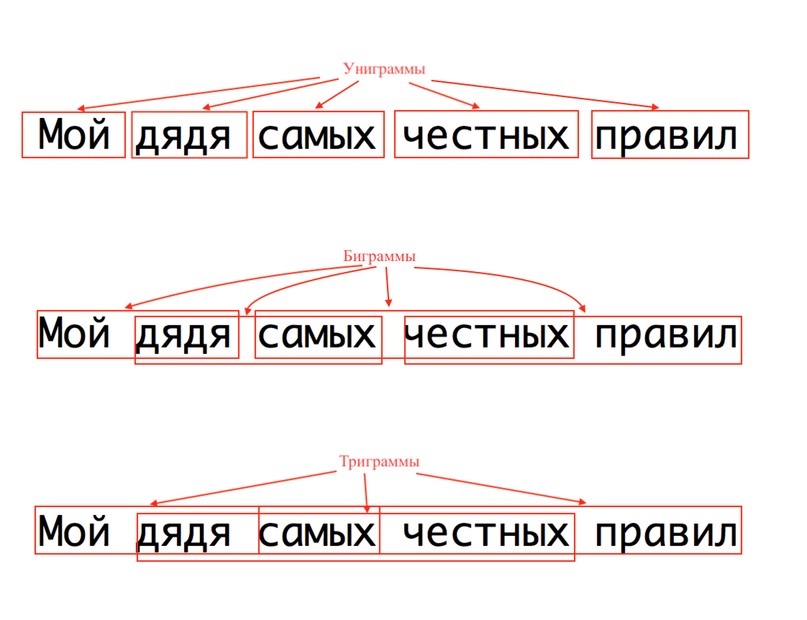
Вычислив частоту вхождения N-грамм в текстах корпуса, можно узнать кое-что о корпусе или отдельных текстах. Например, если сравнить тексты одного автора с текстами множества других, то можно выявить некоторые авторские “фишки”, обороты и идиомы, которые автор использует чаще всего. Причем он даже может делать это неосознанно.
Если исследовать большие языковые корпуса (например, Google Books или Википедию), то можно выявить закономерности более широкого плана. Например, устойчивые выражения в языке или даже некоторые общественные тренды, отражающиеся в частотностях N-грамм.
N-граммы часто используются в следующих задачах:
- Выдачи подсказок следующего слова (например, в поисковой строке). N-граммная модель позволяют вычислить вероятность следующего слова N-граммы, если известны предыдущие.
- Выявления авторства или плагиата. Можно вычислить N-граммы для разных текстов и сравнить степень сходства.
- Поиска и коррекции ошибок
Интересное применение N-грамм демонстрирует Google в своем инструменте Google Ngram Viewer. Оцифровав коллекцию книг (Google Books), Google выдал нам инструмент для визуализации изменений в текстах с учетом времени. Здесь можно увидеть, как в книгах отражались важные мировые события, пики популярности исторических личностей (см. наше исследование про Ленина и Сталина) и художественных персонажей.

