
Что такое OCR?
OCR (англ. optical character recognition, оптическое распознавание символов) — это технология автоматического анализа текста и превращения его в данные, которые может обрабатывать компьютер.
Когда человек читает текст, он распознает символы с помощью глаз и мозга. У компьютера в роли глаз выступает камера сканера, которая создает графическое изображение текстовой страницы (например, в формате JPG). Для компьютера нет разницы между фотографией текста и фотографией дома: и то, и другое — набор пикселей.

Именно OCR превращает изображение текста в текст. А с текстом уже можно делать что угодно.
Как это устроено?
Представьте, что в алфавите есть только одна буква «А». Сделает ли это задачу преобразования картинки в текст проще? Нет. Дело в том, что у каждой буквы (и любой другой графемы) есть аллографы — различные варианты начертания.
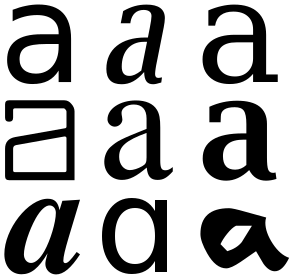
Человек легко поймет, что все это буква «А». Для компьютера же есть два способа решения проблемы: распознавать символы целостно (распознавание паттерна) или выделять отдельные черты, из которых состоит символ (выявление признаков).
Распознавание паттерна
В 1960-х годах был создан специальный шрифт OCR-A, который использовался в документах типа банковских чеков. Каждая буква в нем была одинаковой ширины (т.н. шрифт фиксированной ширины или моноширинный шрифт).

Принтеры для чеков работали с этим шрифтом, и для его распознавания было разработано программное обеспечение. Поскольку шрифт был стандартизирован, его распознавание стало относительно простой задачей. Следующим шагом стало обучение программ OCR распознавать символы еще в нескольких самых распространенных шрифтах (Times, Helvetica, Courier и т.д.).
Выявление признаков
Этот способ еще называют интеллектуальным распознаванием символов (англ. intelligent character recognition, ICR). Представьте, что вы — OCR-программа, которой дали множество разных букв, написанных разными шрифтами. Как вам отобрать из этого множества все буквы «А», если каждая из них немного отличается от другой?

Можно использовать такое правило: если видишь две линии, сходящиеся наверху в центре под углом, а посередине между ними горизонтальная линия, то это буква «А». Это правило поможет распознать все буквы «А» независимо от шрифта. Вместо распознавания паттерна выделяются характерные индивидуальные черты, из которых состоит символ. Большинство современных омнишрифтовых (умеющих распознавать любой шрифт) OCR-программ работают по этому принципу. Чаще всего в них используются классификаторы на основе машинного обучения (т.к. фактически перед нами стоит задача классификации картинок по классам-буквам) в последнее время некоторые OCR-движки перешли на нейронные сети.
Что делать с рукописным вводом?
Человек способен догадаться о смысле предложения, даже если оно написано самым неразборчивым почерком (если речь не идет о рецепте на лекарства, конечно).
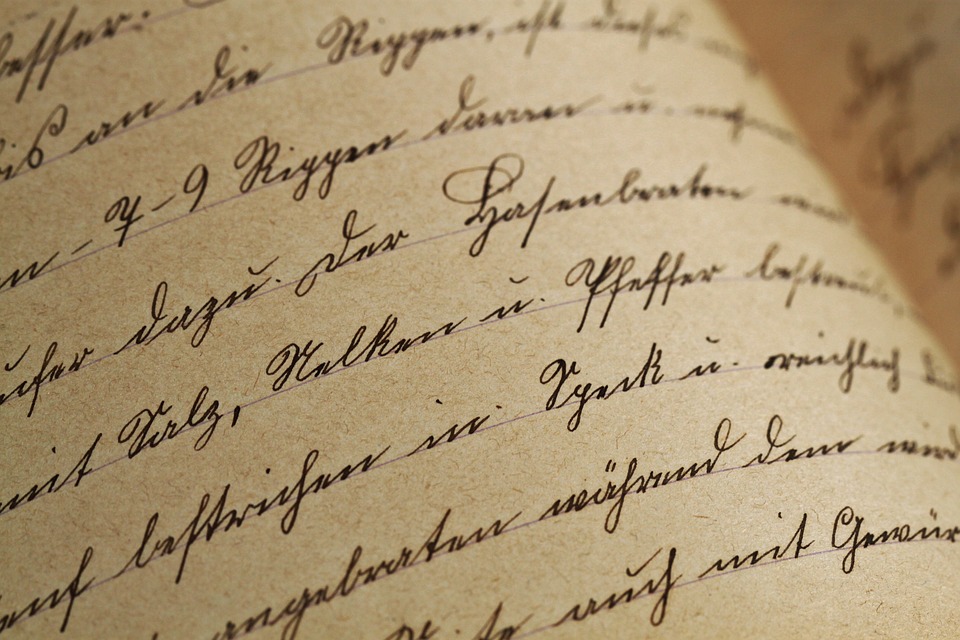
Задачу для компьютера иногда упрощают. Например, людей просят писать почтовый индекс в специальном месте на конверте специальным шрифтом. Формы, созданные для дальнейшей обработки компьютером, обычно имеют отдельные поля, которые просят заполнять печатными буквами.
Планшеты и смартфоны, которые поддерживают рукописный ввод, часто используют принцип выявления признаков. При написании буквы «А» экран «чувствует», что сначала пользователь написал одну линию под углом, затем вторую, и, наконец, провел горизонтальную черту между ними. Компьютеру помогает то, что все признаки появляются последовательно, один за другим, в отличие от варианта, когда весь текст уже записан от руки на бумаге.
OCR по шагам
Предобработка
Чем лучше качество исходного текста на бумажном носителе, тем лучше будет качество распознавания. А вот старый шрифт, пятна от кофе или чернил, заломы бумаги понижают шансы.
Большинство современных OCR-программ сканируют страницу, распознают текст, а затем сканируют следующую страницу. Первый этап распознавания заключается в создании копии черно-белого цвета или в оттенках серого. Если исходное отсканированное изображение идеально, то все черное — это символы, а все белое — фон.
Распознавание
Хорошие OCR-программы автоматически отмечают трудные элементы структуры страницы — колонки, таблицы и картинки. Все OCR-программы распознают текст последовательно, символ за символом, словом за словом и строчка за строчкой.
Сначала OCR-программа объединяет пиксели в возможные буквы, а буквы — в возможные слова. Затем система сопоставляет варианты слов со словарем. Если слово найдено, оно отмечается как распознанное. Если слово не найдено, программа предоставляет наиболее вероятный вариант и, соответственно, качество распознавания будет не таким высоким.
Постобработка
Некоторые программы дают возможность просмотреть и исправить ошибки на каждой странице. Для этого они используют встроенную проверку орфографии и выделяют неверно написанные слова, что может указывать на неправильное распознавание. Продвинутые OCR-программы используют так называемый метод поиска соседа, чтобы найти слова, которые часто встречаются рядом. Этот метод позволяет исправить неверно распознанное словосочетание «тающая собака» на «лающая собака».
Кроме того, некоторые проекты, которые занимаются оцифровкой и распознаванием текстов, прибегают к помощи волонтеров: распознанные тексты выкладываются в открытый доступ для вычитки и проверки ошибок распознавания.
Особые случаи
Для высокой точности распознавания исторического текста с необычными графическими символами, отличающимися от современных шрифтов, необходимо извлечь соответствующие изображения из документов. Для языков с небольшим набором символов это можно сделать вручную, но для языков со сложными системами письменности (например, иероглифических) ручной сбор этих данных нецелесообразен.
Для распознавания исторических китайских текстов требуется внести в OCR-программу как минимум 3000 символов, которые имеют разную частотность. Если для распознавания исторических английских текстов достаточно ручной разметки нескольких десятков страниц, то аналогичный процесс для китайского языка потребует анализа десятков тысяч страниц.
В то же время многие исторические варианты китайской письменности имеют высокую степень сходства с современным письмом, поэтому модели распознавания символов, обученные на современных данных, часто могут давать приемлемые результаты на исторических данных, хоть и со сниженной точностью. Этот факт вместе с использованием корпусов позволяет создать систему для распознавания исторических китайских текстов. Для этого исследователь Д. Стеджен (Donald Sturgeon) из Гарварда обработал два корпуса: корпус транскрибированных исторических документов и корпус отсканированных документов желаемого стиля.
После предварительной обработки изображений и этапов сегментации символов процедура извлечения обучающих данных состояла из:
1) применения модели распознавания символов, обученной исключительно на современных документах, к историческим документам для получения промежуточного результата оптического распознавания с низкой точностью;
2) использование этого промежуточного результата для соотнесения изображения с его вероятной транскрипцией;
3) извлечение изображений размеченных символов на основе этого соотнесения;
4) выбор из размеченных символов подходящих обучающих примеров.
Полученные данные могут использоваться без проверки для обучения новой модели распознавания символов, позволяющей достичь более высокой точности на аналогичном материале.
Источники:
- Optical character recognition (OCR)
- Unsupervised Extraction of Training Data for Pre-Modern Chinese OCR

