
Современный интернет – это огромное поле битвы за ваше внимание. Все хотят, чтобы посмотрели их видео, зашли на их сайт, прочитали их статью (кстати, спасибо!), и всем для этого нужен именно ваш просмотр. Само поле выглядит очень увлекательно: здесь есть отряды блогеров – покрупнее и поменьше, растущая с каждым днём армия алгоритмов – поумнее (лента рекомендаций) и не очень (лента рекомендаций), а ещё тут есть тактическая группа по применению оружия массового поражения – баннеров с шокирующим текстом и интригующей картинкой, призывающих кликнуть по ссылке. Этот текст иногда настолько странный (улучшить зрение в 105 раз? смотреть драку топ-менеджеров телеканала? сбросить 40 кг за 5 дней?), что я задумываюсь, не начали ли нейросети писать эти заголовки – иными словами, продолжая мою метафору, не внедрились ли цифровые агенты армии нейроботов в отряды создателей жёлтого кликбейта. Насколько я знаю, пока нет – но я решил исправить эту ситуацию. К тому же, судя по имеющемуся контенту, затеряться среди существующего человеческого творчества будет не так уж и сложно.

Сбор и оценка данных: выходим в поле
Конечно, чтобы научить компьютер чему-то, сначала нужно показать ему примеры — а их нужно сначала собрать. Понимая, что мне предстоит искать клюкву на самых радиоактивных болотах рунета, я вздохнул и отправился в цифровой поход.
Первым делом я прошёлся по старым адресам, на которых раньше встречал жёлтые заголовки, и понял, что материалы вырождаются: да, меня всё ещё встречали заголовки на резонансные и провокационные темы, но они были оформлены в современном неприметно-корпоративном стиле, были довольно ровно написаны, без привычного «Жесть! Не поверите!» или «Читать по ссылке…», и, главное, вели к реальным новостям, которые в целом соответствовали заголовку. Нет, это было не то — мне нужны были страшные вести из мира эстрады, забытые всеми рецепты бешеного здоровья и странные картинки: словом, та самая, настоящая клюква из конца нулевых-начала десятых.
Отчаявшись найти её в привычных местах, я решил вбить «кликбейт» в поиск и посмотреть, не выходил ли кто-то недавно на скрытые поляны с правильными баннерами до меня. Нашлось не так много, но ключом к нужной информации стала статья The Village Беларусь с анализом кликбейта: во-первых, в ней была довольно интересная классификация жёлтых заголовков, к которой я ещё вернусь, а, во-вторых, по цепочке ссылок из этой статьи я не сразу, но, наконец, вышел на нужный сайт (если вы захотите тоже — это на ваш страх и риск!).
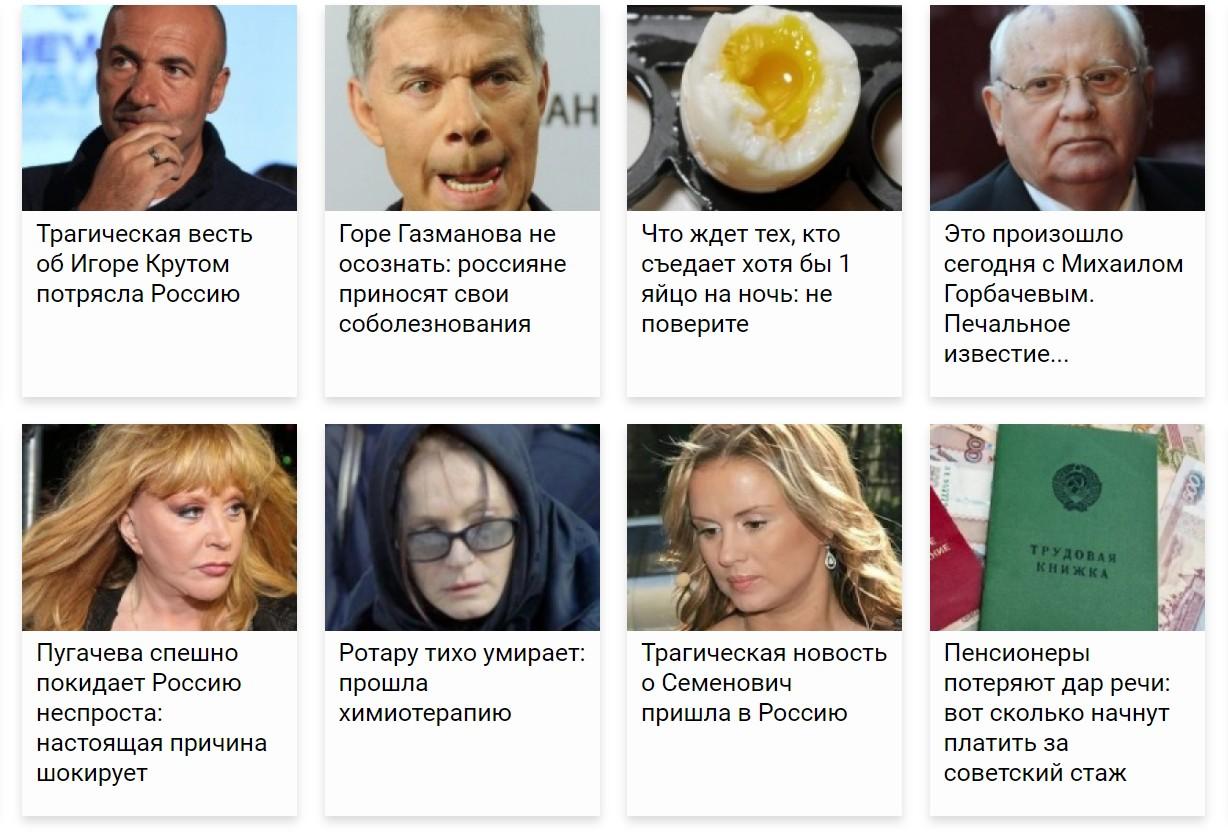
С сайтом было всё замечательно, кроме одного: с него удалось собрать всего 472 уникальных заголовка — этого маловато для модели. Обычно для качественного обучения нужно где-то несколько тысяч примеров, поэтому пришлось искать, чем бы пополнить датасет. К счастью, во время блуждания по цифровым болотам я наткнулся на другой сайт (опять же, на ваш страх и риск!) — с десятками тысяч новостей по тому самому шаблону, а также я с самого начала присмотрел ещё один замечательный источник заголовков нужной степени кликбейтности — Яндекс.Дзен. На этих сайтах, правда, только часть заголовков оказалась по-настоящему жёлтой, а где-то половина были обычными и пресными, и модель, обученная на этой смеси, получилась бы недостаточно сочной. Поэтому, чтобы отобрать самую клюквенную клюкву из множества ягод, я решил сначала научить компьютер оценивать кликбейтность заголовка на самой первой выборке — небольшой, но качественной.
Обработка данных
Как определить, насколько произвольный текст похож на кликбейтный заголовок? Это не так просто, как может показаться: у настоящих трешовых баннеров, конечно, есть некоторые общие формулы (ШОК! вы могли это заметить, если нет — жмите по ссылке, пока не удалили, упадёте…), но встречаются они далеко не всегда. Кроме того, что важнее, жёлтым заголовок делает не пунктуация, а смысловое наполнение — и в этом компьютерам разобраться сложнее, чем человеку. Для решения этой задачи существуют разные способы, но конкретно для этой статьи я выбрал векторы предложений. Идея такова — оценивать кликбейтность двумя способами: на близость к стандартным темам жёлтых баннеров и на сходство с векторным представлением собственно кликбейта.
Как это работает?
Подобно тому, как компьютерам представляют тексты в понятном для них виде двоичного кода, я проиллюстрирую принцип работы моего плана на примере, очень близком человеку — на щенках.
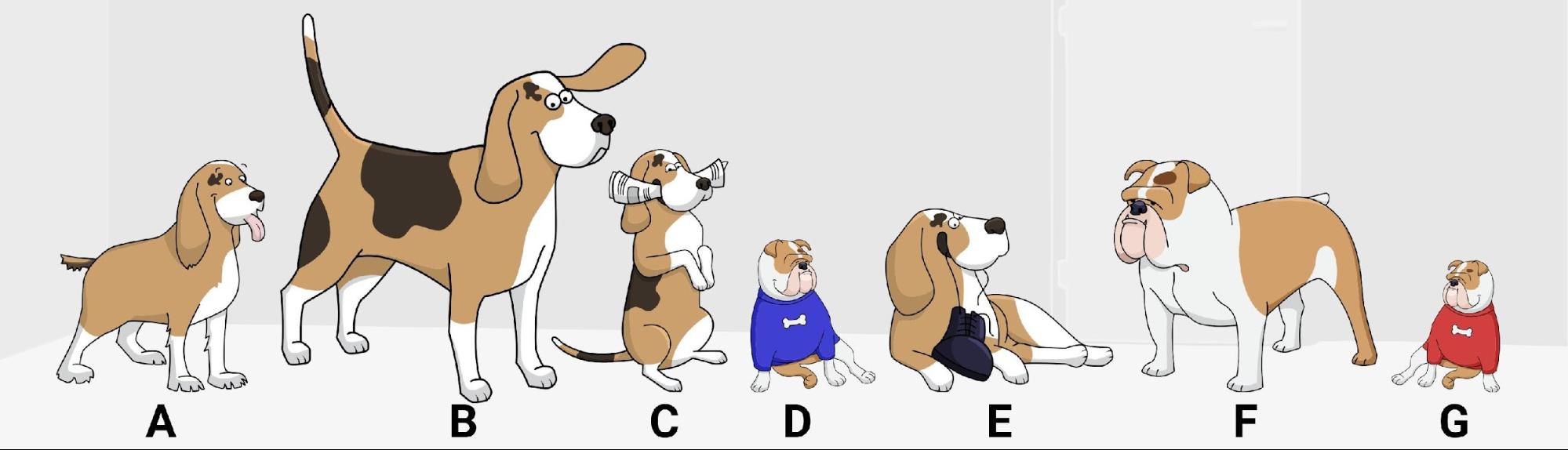
Использованы рисунки GraphicMama-team с Pixabay
Допустим, у нас есть две группы собак. Взглянув на картинку выше, довольно легко понять, где взрослые собаки и где чьи щенки. Но представим, что тем же вопросом (кто чей щенок) задался инопланетянин, который воспринимает окружающий мир не глазами, а в разных числовых измерениях. Это нам, людям, заметно, что одни щенята покрупнее и с пятном на лбу справа, а другие — поменьше и с пятном слева, а пришелец не может всё уловить с одного взгляда, ведь он лишён навыка визуального восприятия.
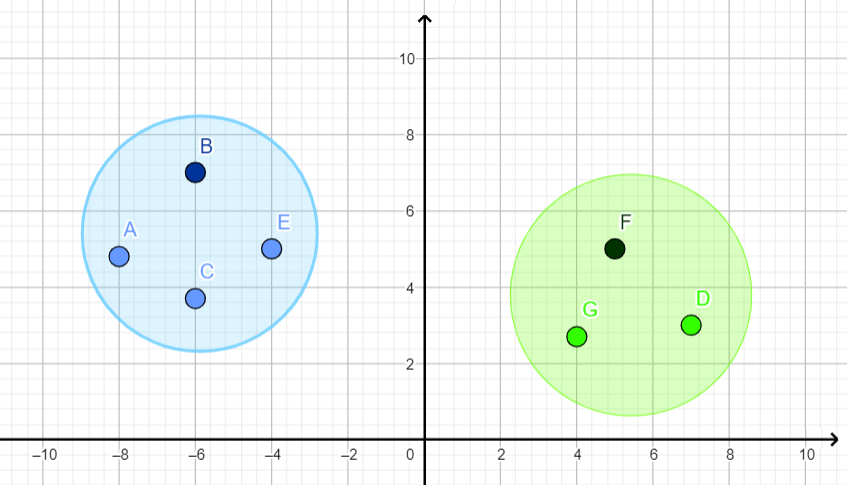
Чтобы узнать, где чей щенок, наш инопланетянин сначала оценит высоту каждой собаки и расстояние пятна от середины мордочки. Затем он мысленно нанесёт измерения на график и заметит, что сложилось две явных группы точек — значит, перед ним и правда две собачьи семьи. А кроме того, как он догадается, те точки, которые повыше на графике — это собаки покрупнее, то есть, логичным образом, родители. И тогда, если в комнату забежит потерявшийся щенок, люди поймут, чей он, посмотрев на него, а инопланетянин — определив для него рост и положение пятна и сравнив с уже имеющимися данными.
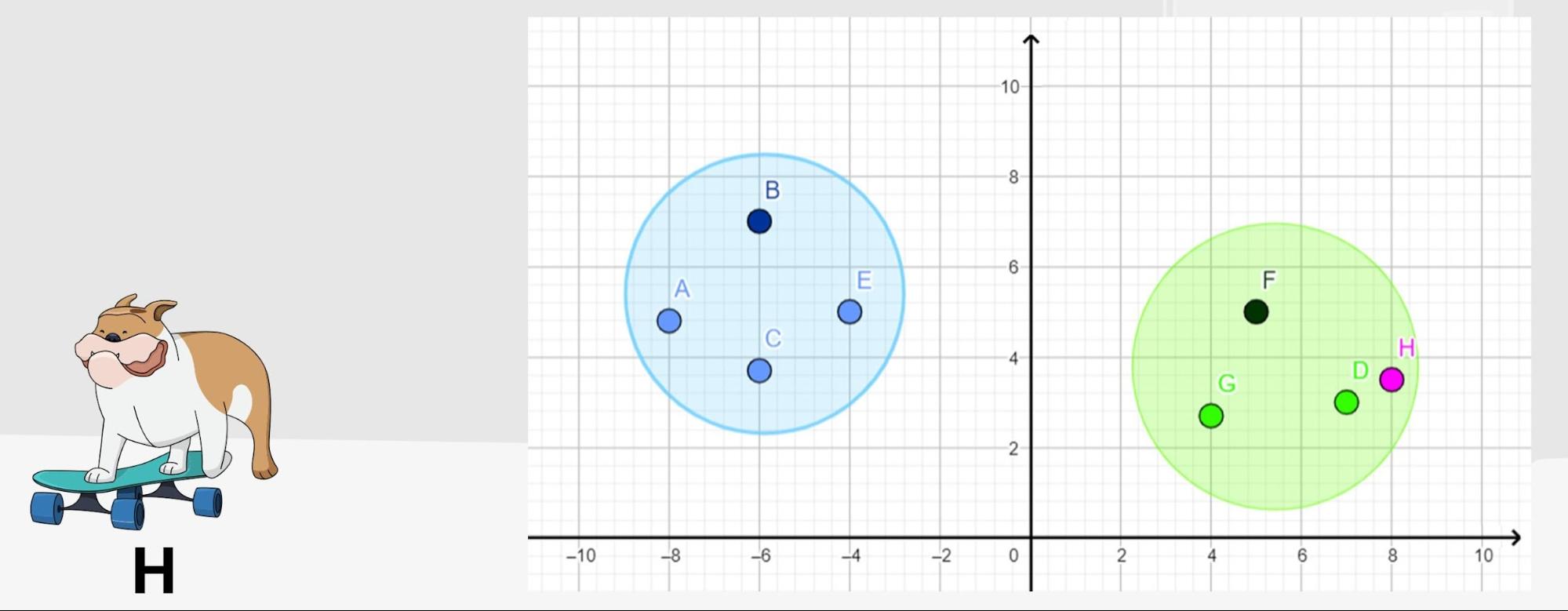
Использованы рисунки GraphicMama-team с Pixabay
Конечно, пришелец в моём примере играл роль компьютера: человечество всё ещё не умеет снабжать вычислительные машины зрением и пониманием речи в привычном нам смысле, зато мы довольно успешно учим их воспринимать мир в цифровом виде. Описанная мной идея с щенками (за вычетом небольших упрощений) стоит и за задачей векторного преобразования текста — мы обучаем нейросети представлять похожие по смыслу строки как максимально близкие точки на сетке координат, чтобы сначала определять закономерности среди известных текстов (щенки в комнате), а потом оценивать новые (забежавший щенок). Для этого, конечно, требуется значительно больше измерений (собаку ведь не оценишь только в росте и пятнах — нужны ещё вес, длина хвоста, милота), поэтому говорят, что тексты отображают в многомерном векторном пространстве. Это последний сложный термин на сегодня — здесь важно то, что со временем преобразовывать тексты для компьютера (и, может, в будущем для инопланетян) получается всё лучше и лучше.
Тематическая близость
Итак, чтобы научиться определять кликбейтность строки, я провёл анализ исходных 472 заголовков и научился разбираться в сортах самого ядерного кликбейта. В итоге у меня получилось 3 основных кластера (схожие по тематике группы):
- Всё про здоровье. Чудодейственные капли, мази и советские средства, от которых немеют врачи (но иногда для пущей убедительности «рассказывают» про них тоже известные телеврачи или актёры). Этот волшебный арсенал лечит различные неприятные и возрастные болезни, причём неестественно успешно: давление нормализуется за несколько суток, тромбы выходят литрами, а вес сбрасывается десятками килограммов в неделю. Сюда же, кстати, попали и некоторые заголовки про дачное хозяйство (потому что «избавьтесь от паразитов за два дня» очень похоже на «избавьтесь от сорняков за два дня», как и «рецепт домашнего средства» на «рецепт домашнего сыра»).
- Всё про знаменитостей и предсказания. Если первая группа заголовков рассчитана на то, чтобы вас неестественно обрадовать, то эта — на то, чтобы шокировать и напугать. Здесь заголовки обещают вам прискорбные вести про разных звёзд эстрады, часто без подробностей (максимум — напишут, что они при смерти), и сюда же присоединились зловещие предсказания — Ванга или схимонахиня Нина сообщают, что в определённом году (иногда уже прошедшем) удача и деньги ждут только три знака зодиака, а неудача — всю страну, в которой, кстати, грядёт замена денег или другая реформа (это, правда, без участия гадалок и схимонахинь). В общем, бояться уже можно и нужно.
- Всё остальное. Сюда попали все оставшиеся, но от этого не менее жёлтые заголовки: они оказались меньше похожи между собой и ближе к «эталонному кликбейту», что можно видеть на графике. Здесь — уже привычные нам новости про звёзд (якобы при смерти) и будущее (астролог предупредил: в Госдуму внесён законопроект…), про выращивание дома клубники (42 килограмма) и апельсинов (9 вёдер), а ещё просто громкие заголовки без конкретики (Опозорились на весь мир!).
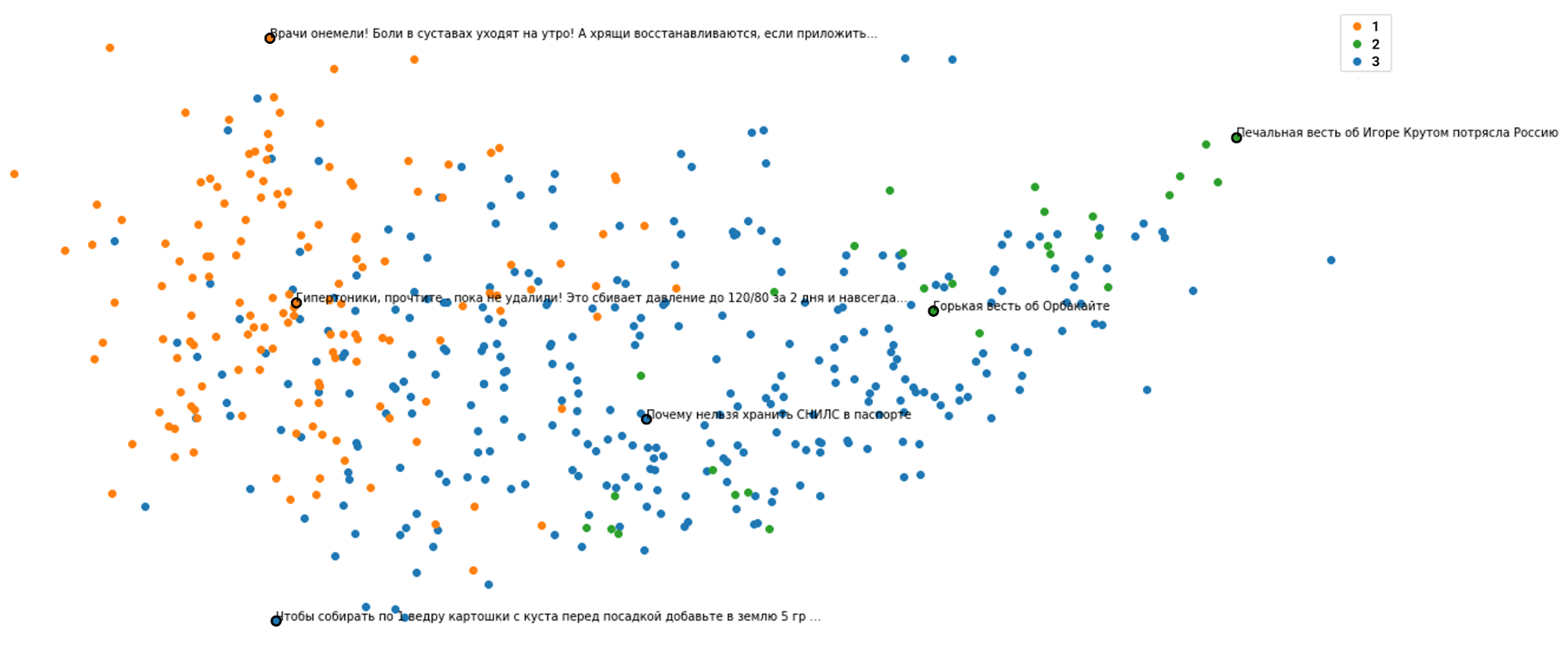
В целом, распределение получилось довольно похожим на то, которое описано в упомянутой мной выше статье коллег из Беларуси: медицина (плюс рецепты для дома и огорода), новости про знаменитостей (плюс шок-контент от гадалок и советы про обогащение) и всё остальное — при этом обязательно утрированное для абсурда. Но, в отличие от коллег, я выделил эти группы аналитическим методом и не собирался на этом останавливаться: классификация получилась лишь побочным продуктом, поскольку основным интересом определения кластеров для меня было получение их центральных точек. Они были нужны мне для того, чтобы считать желтизну произвольных строк: для каждого вновь введённого заголовка я теперь могу получить вектор и определить его расстояние от центра каждой из трёх основных групп кликбейта. Логика такова: чем больше минимальное из этих расстояний — тем меньше кликбейта в той строке, которую я проверяю.
Сходство с кликбейтом
А ещё на одном из попавшихся мне сайтов я заметил замечательную вещь: тексты заголовков на баннере иногда отличались от заголовков самой новости, причём вторые были менее жёлтыми (вы ведь уже кликнули). Например, на баннере могло быть написано «Трагическая новость о Семенович пришла в Россию…», а заголовок у текста был такой: «Анна Семенович сильно отравилась и попала под капельницу»: тема та же, кому-то всё ещё интересно, но гораздо менее кликбейтно. «Очень напоминает известный пример с векторами слов», подумал я: только если в нём из вектора для слова «king» вычли вектор «man», прибавили «woman» и получили вектор «queen», то в моей задаче, поскольку всё принципиально похоже, можно так же вычесть из пресных заголовков текстов жёлтые подписи к баннерам — и должен остаться собственно вектор кликбейта! Именно это я и сделал, определив средний вектор для разности всех пар заголовков. Так у меня появился эталон «желтизны», с которым можно сравнивать вектора строк всё тем же методом близости.
Выбор жёлтых заголовков
Итак, я научился считать кликбейтность сразу двумя способами. Осталась последняя сложность: каждый из этих способов выдавал мне векторное расстояние — условно, число от 0 до 8 (где 0 — максимально близкий к кликбейту, а 8 — наоборот, самый далёкий и пресный). Но мне нужно было преобразовать эти расстояния в оценку кликбейтности в условных процентах — от 0 до 100. Как это сделать?
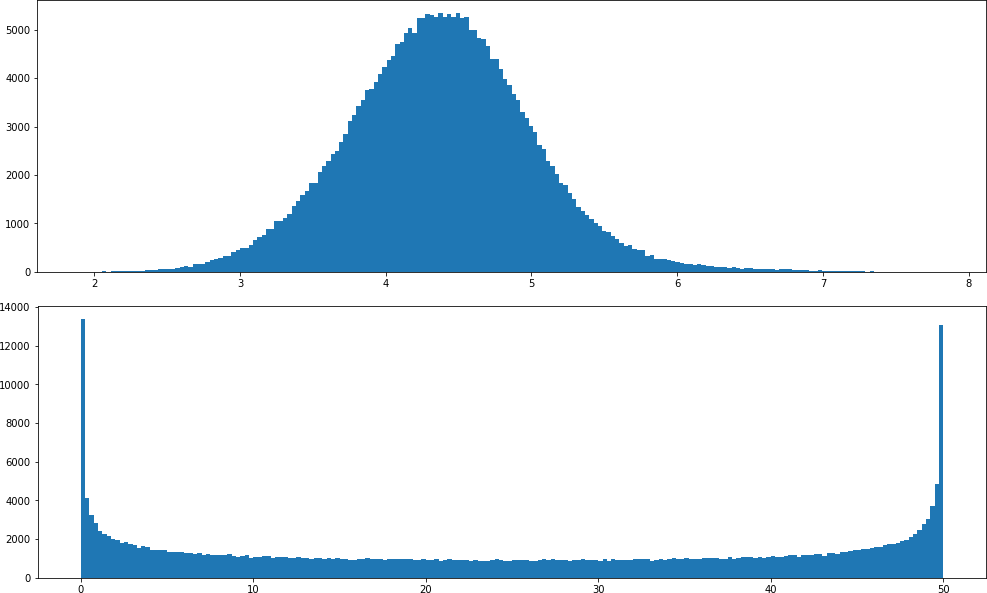
Первая мысль — сопоставить минимальное значение каждого способа 50%, максимальное — 0% (получив, условно, формулу (8 — xрасст) * 6,25) и сложить результаты. Вариант неплохой, но не вполне меня устраивающий: всё дело в том, что наши векторные расстояния распределены нормально — близкие к средним значения встречаются значительно чаще, чем те, которые стремятся к минимуму или максимуму. Поэтому огромное множество заголовков просто получали бы «среднюю» оценку по такой метрике, а с учётом того, что я применяю два различных способа, этот эффект ещё и удваивался бы: почти каждая введённая строка получила бы «среднюю» оценку. Всё же хотелось получить более равномерно распределённую метрику: чтобы оценку от 20 до 30 получало примерно столько же вариантов строк, сколько и оценку от 40 до 50, и от 80 до 90: такой результат более интересен и информативен.
Поэтому я сделал второй шаг: преобразовал по формуле нормальное распределение для каждой из метрик в равномерное. Получилось не очень ровно (на графике видны пики около минимума и максимума), но все равно результат меня устраивал больше, чем до преобразования. В конце концов, это моя метрика кликбейтности!
И теперь, когда я научился определять кликбейт, я рад поделиться этой возможностью с вами, дорогие читатели: по этой ссылке вы сможете испытать свой талант автора жёлтых заголовков. Всё, что для этого нужно — иметь аккаунт Google и нажать пару соответствующих кнопок.
Обучение модели
Тем временем я отобрал самые жёлтые заголовки из своей большой выборки, выбрав из них те, для которых кликбейтность составила 50% и более (их получилось около 130.000), после чего приступил к обучению компьютера подражать удивительному жанру трешовых заголовков рунета.
За последние лет семь компьютеры намного лучше научились не только «читать», но и «писать»: индустрия прошла путь от цепей Маркова через RNN и LSTM к большим нейросетям, основанных на архитектуре трансформеров. Как это происходило, что всё это значит и имеет ли это отношение к серии фильмов (нет) — это отдельная большая тема, которую просто не уместить в мою статью. Нам же с вами сейчас важно, что самый популярный нейросетевой контент на сегодняшний день основан именно на этой архитектуре (если чуть точнее, то на GPT-2 и GPT-3). В очень упрощённом виде эти модели работают так: берут некоторую начальную строку, разбивают её на слова или их части, получает для них векторное представление, подобное тому, которое я описывал выше, и начинает генерировать текст — дополнять исходную строку новыми векторами, которые потом преобразуются обратно в слова.
К слову, у нейросетей-трансформеров свой особый способ кодировать слова, которому они долго обучаются — именно благодаря этому их результаты так впечатляют. Это значит, что при обучении GPT дополнять тексты в особом жанре, мы начинаем работу с уже имеющей много «знаний» о языке моделью и переучиваем её — поэтому в нашем случае корректнее говорить не об обучении (training), а о дообучении (fine-tuning). Разница в том, что в первом случае у модели нет начальных знаний: мы как бы берём набор деталей и шестерёнок, говорим им научиться ездить — и они начинают сами складываться и проверять, насколько далеко получается уехать, постепенно перестраиваясь в самую удачную конфигурацию. А при дообучении мы получаем готовый механизм, уже научившийся ездить, и говорим ему «отлично, но я буду путешествовать исключительно по болотам — забудь всё, чему тебя учили раньше, и научись ездить в моём лесу». В моей задаче дообучение выглядело так: я взял модель, обученную на огромном массиве текстов на русском, и поставил ей одну конкретную задачу — генерировать только кликбейт.

Я подготовил две разные модели: одна создаёт заголовки, другая придумывает под них текст. Принципиальных отличий между ними не так много, но давайте всё-таки разберёмся.
Генерация заголовков
За заголовки у меня отвечает модель поменьше: она, кстати, исходно та же, что и внутри Порфирьевича, но переученная для генерации кликбейта на моей выборке из 130.000 примеров. Каждый раз она генерирует около 10 нейрозаголовков, все из которых я затем оцениваю на кликбейтность своим алгоритмом и выбираю 3 самых жёлтых по мнению компьютера варианта.
Внимательный читатель может заметить: раньше я писал, что для начала генерации модели необходима исходная строка — ладно создание новости по заголовку, но как же тогда я создавал полностью сгенерированные нейрозаголовки, если тут нельзя придумать никакой начальной строки? Это известная проблема, и для того, чтобы её обойти, применяются разные хитрости: чаще всего (так сделал и я) выбирается специальное слово, обозначающее «начало текста», которое затем передаётся модели — и она начинает творить.

Генерация текста новости
Для создания текстов я дообучил модель потяжелее — она лучше пишет более подробные и связные тексты. В этом случае в качестве стартовой строки я давал модели как раз нейрозаголовок, по которому ей необходимо было сгенерировать новость, подобную сотне тысяч новостей с заголовками, которые модель видела на этапе дообучения.

К слову, вы можете попробовать создать свои нейрозаголовки и нейроновости по той же ссылке, что и для оценки кликбейтности! Просто нажмите соответствующие кнопки и получите 3 своих личных нейроновости. Или 6. Или 9. Или больше…
И что теперь?
Теперь мы умеем оценивать, насколько разные предложения похожи на кликбейтные заголовки, а ещё создавать неограниченное количество таких заголовков и несуществующих новостей к ним впридачу. Но — самое главное — надеюсь, читая эту статью, вы, дорогие читатели, поближе познакомились с миром современной компьютерной лингвистики и глубокого обучения.
В любом случае, с этого момента можно создавать популярный контент одной кнопкой мыши! Переходите по ссылке и жмите нужные кнопки, достаточно одной нейронной…
Репозиторий с кодом и данными этого исследования: github.com/sysblok/neuroclickbait



