
Один из любимейших методов психоаналитиков — интерпретация сновидений. Которые, как известно, забываются или видоизменяются при вспоминании. Как был бы счастлив Фрейд, если бы ему сказали, что сновидение его клиента можно «увидеть», считав его прямо с активности мозга спящего! А теперь представьте, что люди получают возможность передавать воображаемое ими изображение другим. Фотороботы больше не нужны, люди с полным параличом теперь могут общаться с миром, врачи могут видеть галлюцинации больных, а художники — писать любые картины за секунду.
Спойлер: мы так делать еще не умеем и, возможно, никогда не научимся, но научное сообщество подкралось удивительно близко к этой фантастической идее. Мы уже умеем определять по активности мозга, что видит человек в данный момент (и в некоторых случаях точность поразительная).
Как это возможно?
1.Берем мозг
Хотя это кажется невероятно сложной задачей, на самом деле, эволюция подарила нам удобный мозг для этого. Дело в том, что видимое глазом изображение отпечатывается на сетчатке глаза и передается на зрительную кору мозга (область мозга, отвечающую за обработку зрительной информации), практически не искажаясь в координатах. Если вы видите круг, то на зрительной коре отпечатывается такой же круг. Потому что зрительная кора состоит из множества нейронов (клеток мозга), каждый из которых отвечает за свою область зрительного поля. Вот как активируется зрительная кора левого полушария мозга в ответ на увиденную паутинку (Tootell et al., 1982).
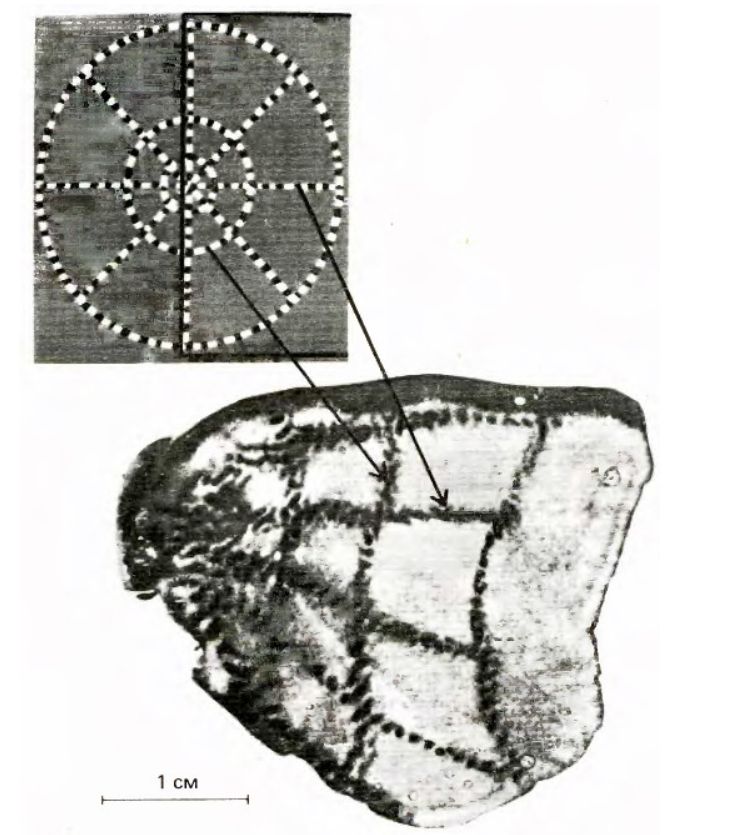
Можно видеть, что вся информация с половины зрительного поля практически не исковерканной переместилась в это полушарие (разумеется, другая половина зрительного поля перемещается в другое полушарие). Но чтобы получить такое изображение, пришлось накачать обезьянку специальным веществом, а потом убить, вытащить мозг и растянуть зрительную кору, ведь обычно она извилистая. Как же сделать это более гуманно?
2.Берем фМРТ
К счастью, для этого у нас есть функциональная магнитно-резонансная томография (фМРТ), которая позволяет увидеть активацию мозга, даже не вскрывая испытуемому череп. фМРТ делает трехмерный снимок мозга человека, подсвечивая на этом снимке области мозга, которые в данный момент активированы: если человек смотрит на картинку, фМРТ подсветит области в зрительной коре, которые отреагировали на эту картинку. Для получения такого снимка мозга испытуемый помещается в специальную машину-трубу, которая, упрощенно говоря, является большим магнитом. Она создает магнитное поле и как бы намагничивает мозг, что позволяет ей его увидеть. Но когда нейроны, реагирующие на увиденную картинку, активируются, к ним по сосудам поступает больше крови, наполненной кислородом, а такая кровь магнитится хуже. Это позволяет машине определить, к какому месту в мозге поступило больше крови, а значит, какое место в мозге в данный момент больше активировано. Как ни странно, такой метод регистрации мозговой активности очень точный.
3.Берем машинное обучение!
Все это значит, что мы можем положить человека в фМРТ-машину, показывать ему, пока он там лежит, картинки (или видео) и регистрировать активность его зрительной коры в это время. Покажем ему много картинок — получим много данных. Очень много данных. Зачем? Чтоб скормить их алгоритму машинного обучения. Стандартный алгоритм машинного обучения учится давать правильный ответ Y на вопрос (в широком смысле — любой набор входящих данных) X. Шаг за шагом он получает разные X и пытается угадать Y. Его предсказание сравнивается с реальным правильным ответом Y, то есть считается разница между ними. И шаг за шагом алгоритм подкручивает внутренние механизмы принятия решения, стремясь минимизировать эту разницу. В итоге, он обучается отвечать на X довольно точно.
Что получаем в итоге?
1.Первые попытки
Ниже вы можете видеть первые вполне уверенные шаги исследователей по направлению к нашей цели. Это исследование 2011 года (Nishimoto et al., 2011). Авторы создали модель (программу, обучающуюся методом машинного обучения), генерирующую фМРТ-сигнал в ответ на короткое видео, то есть предсказывающую, как бы мозг человека отреагировал на это видео. Следовательно, в их исследовании, видео — это Х, а фМРТ-сигнал — это Y. После того как модель уже обучилась хорошо предсказывать, ей подавался на вход реальный фМРТ-сигнал испытуемого, посмотревшего на некоторое видео. Получив его, модель подбирала 100 видео (из имеющегося у нее огромного набора данных), которые, по ее предсказаниям, вызывают наиболее похожий фМРТ-сигнал. Эти 100 видео усреднялись и вот, посмотрите, что получилось: слева реальное видео, которое видит испытуемый, справа — усредненное видео. И хотя результаты далеки от идеала, такая модель почти всегда угадывает, что изображено (человек, текст, форма и т.д.) и как оно движется.
2.Буквы
Надо признать, что идея получать изображение, усредняя уже имеющиеся, — так себе идея, понятно, что идеального результата так не добьешься. Поэтому позже ученые стали использовать всеми нами любимые нейросети (тоже метод машинного обучения), которые умеют самостоятельно генерировать предполагаемые картинки (или видео). Для такой модели фМРТ-сигнал — это X, а картинка — Y, и она пытается научиться генерировать картинки, максимально похожие на реальные. И вот результаты подобной сравнительно недавней нейросети (Du et al., 2017): первая строка — буквы, которые видел испытуемый, последняя — предсказания нейросети авторов статьи, посередине — менее удачные результаты менее продвинутых нейросетей. С цифрами это тоже работает. Впечатляет!

3.Структуры и формы
После этого ученые пошли еще дальше и стали устраивать соревнования нейросетей: одна нейросеть в ответ на фМРТ-активность мозга генерирует предполагаемую картинку, другая пытается отличить эти сгенерированные картинки от реальных. Первая учится обманывать вторую: пытается создавать настолько реалистичные картинки, чтоб вторая принимала их за чистую монету. И вот что получилось (2019 год): слева реальные изображения, справа сгенерированные. Фантастика!
ЭЭГ
И закончим мы совсем недавним исследованием российских ученых (октябрь 2019 года), которые решили использовать вместо фМРТ-сигнала электроэнцефалографию (Rashkov et al., 2019). При таком методе регистрации мозговой активности испытуемому на голову крепятся электроды, улавливающие электрическую активность мозга (ведь когда нейроны активируются, они меняют вокруг себя электрическое поле).
фМРТ — это огромная дорогостоящая машина, их довольно ограниченное количество, к тому же, лежать в ней несколько часов — не самое приятное занятие. Записывать ЭЭГ-сигнал проще, быстрее и дешевле. Почему его раньше не использовали? Потому что в отличие от фМРТ, ЭЭГ обладает плохой пространственной точностью: электроды находятся далеко от мозга и не могут точно определить, откуда конкретно пришел электрический сигнал. Поэтому ЭЭГ-сигнал не говорит нам о том, какие скопления нейронов зрительной коры активировались в ответ на картинку.
Зато ЭЭГ позволяет определить другой важный показатель активности нейронов — частоту, с которой они меняют электрическое поле. Этот показатель многое говорит о том, какая работа сейчас производится мозгом. И вот этой информации — примерного участка активации и частоты, в которой происходит эта активация, — оказалось достаточно, чтоб обучить нейросеть определять тип просматриваемого испытуемым видео. Определив категорию видео, созданная исследователями нейросеть генерировала новое видео, основанное на имеющимся у нее наборе видео выбранной категории. Вот что получилось: попарно показаны кадры реального и сгенерированного видео.

Хочется отметить удивительные совпадения некоторых реальных и предсказанных кадров. Это может объясняться использованием одинаковых наборов видео и для обучения, и для тестирования нейросети. В таком случае, если мы возьмем видео не из обучающего набора, результаты могут быть хуже (это неэкспертное мнение автора). Но тем не менее, хочется назвать это исследование прорывом, ведь теперь мы знаем, что не только по фМРТ, но и по ЭЭГ-сигналу можно определить, что примерно человек видит.
Источники
- Tootell, R. B., Silverman, M. S., Switkes, E., & De Valois, R. L. (1982). Deoxyglucose analysis of retinotopic organization in primate striate cortex. Science, 218(4575), 902-904.
- Nishimoto, S., Vu, A. T., Naselaris, T., Benjamini, Y., Yu, B., & Gallant, J. L. (2011). Reconstructing visual experiences from brain activity evoked by natural movies. Current Biology, 21(19), 1641-1646.
- Du, C., Du, C., & He, H. (2017, May). Sharing deep generative representation for perceived image reconstruction from human brain activity. In 2017 International Joint Conference on Neural Networks (IJCNN) (pp. 1049-1056). IEEE.
- Shen, G., Dwivedi, K., Majima, K., Horikawa, T., & Kamitani, Y. (2019). End-to-end deep image reconstruction from human brain activity. Frontiers in Computational Neuroscience, 13.
- Rashkov, G. V., Bobe, A. S., Fastovets, D. V., & Komarova, M. V. (2019). Natural image reconstruction from brain waves: a novel visual BCI system with native feedback. bioRxiv, 787101.



