
В последние годы речевые и языковые технологии коренным образом меняют наше повседневное взаимодействие с девайсами: мы можем одним голосом включить любимую музыку на умных колонках, узнать погоду на завтра или просто поболтать с голосовым помощником, всегда готовым тебя выслушать. Но несмотря на заметный прогресс в этой сфере, компьютеры до сих пор плохо справляются с задачей понимания естественной речи в случаях разговоров нескольких человек: интервью, конференции, телефонные звонки или записи медицинского приёма пациентов. Для понимания естественной речи необходимо не только распознавать слова, но и определять говорящего их человека.
На первый взгляд может показаться, что нет ничего страшного в том, что машина может ошибиться при определении говорящего. Установить личность задающего вопрос на конференции не так важно, как понять содержание вопроса и ответа на него. Однако в таких случаях, как опрос пациента на медицинском осмотре в больнице или разговор клиента с банковским сотрудником, даже одно неправильно отнесенное слово может значительно исказить смысл высказывания. Сравните риторическое «да» врача в конце вопроса «Вы регулярно принимали эти таблетки, да?» и утвердительный ответ пациента.
Традиционно для решения этой проблемы используются системы диаризации (Speech Diarization, SD), т.е. различения речи говорящих, основанные на акустических данных. Сначала определяются моменты смены говорящего в разговоре, а затем система относит тот или иной фрагмент речи к конкретному говорящему. Параллельно с диаризацией запускается процесс автоматического распознавания речи (Automatic Speech Recognition, ASR); результаты двух процессов объединяются, и система выдает фрагмент распознанного разговора с тегами-ролями в разговоре:
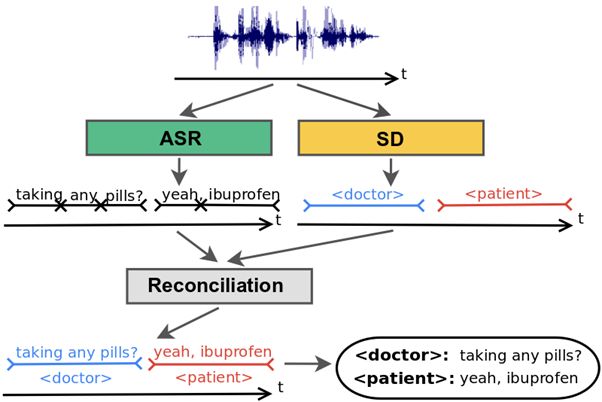
Несмотря на то, что этому базовому подходу уже почти два десятка лет, в нем заложен ряд ограничений. Во-первых, разговор должен быть разбит на фрагменты, содержащие речь только одного диктора. Но на практике алгоритм, распознающий момент смены говорящих на основе одних акустических данных, иногда ошибается и выделяет фрагменты речи, содержащие реплики сразу нескольких человек. Во-вторых, такая система вынуждена «балансировать» между точностью атрибуции высказываний и их длиной, что часто оборачивается неправильным определением диктора, если реплика короткая. И, наконец, значительным ограничением является отсутствие простого механизма учёта лингвистических данных, к которым мы как носители языка прибегаем очень часто. Нам кажется очевидным, что вопрос «Как часто вы принимаете таблетки?» в контексте медицинского осмотра с большей вероятностью будет задан врачом, а «Когда мы должны сдать домашнее задание?» — студентом, а не преподавателем. Для этого нам совсем не обязательно анализировать акустические различия в голосах двух участников разговора; лингвистические данные почти однозначно помогают нам определить роль говорящего. Однако системы диаризации до сих пор таким механизмом не обладали.
Недавняя разработка инженеров Google AI позволяет обойти обозначенные выше ограничения. Разработчики выбрали архитектуру рекуррентной нейронной сети на основе трансдьюсера (recurrent neural network transducer, RNN-T) для объединения акустических и лингвистических данных, а также систем распознавания и диаризации речи в одну систему.
RNN-T состоит их трех сетей: 1) сеть транскрипции, которая устанавливает соответствие между последовательностями звуков и фонемами; 2) сеть прогнозирования, которая предсказывает следующий тег говорящего с учетом уже определенных ранее тегов; 3) объединенная сеть, которая соединяет выводы двух предыдущих сетей и задает распределение вероятностей в наборе тегов на каждом отрезке времени. Также в архитектуре модели предусмотрен цикл обратной связи (см. рис.2), где слова, распознанные ранее, снова отправляются на ввод, что позволяет RNN-T модели учитывать такие данные как, например, конец вопроса.
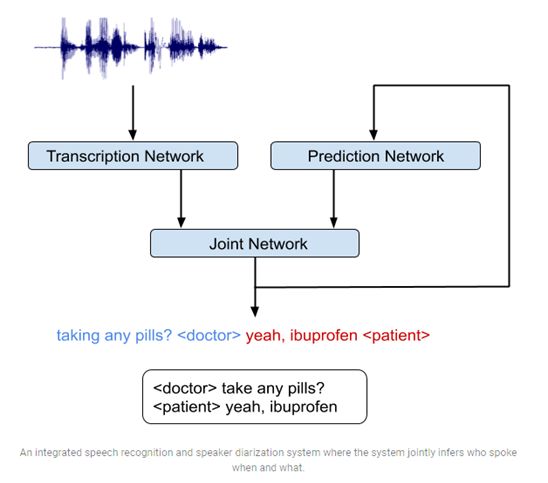
Разработчики отмечают, что гибридная модель может быть обучена так же, как система распознавания речи. Транскрипции для обучения представляют собой слова говорящего, сопровождаемые тегом роли в разговоре. Например: «Когда нужно сдать домашнее задание?» <студент>, «Их нужно сдать завтра до начала занятия» <учитель>. После того как модель обучена на примерах аудио и соответствующих транскрипциях, пользователь может загрузить запись разговора и получить размеченный текст.
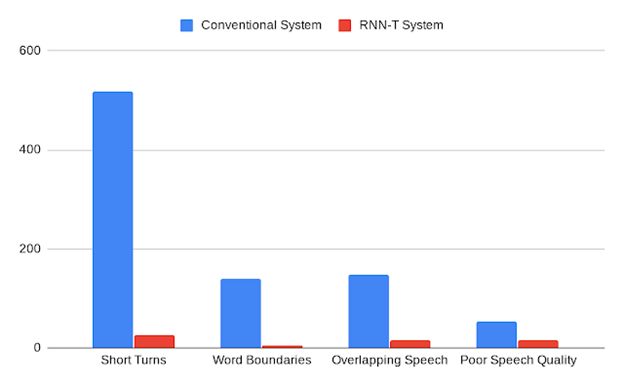
Инженеры Google AI заявляют, что разработанная ими гибридная модель позволяет рекордно снизить общий показатель ошибок диаризации с 20% до 2% и демонстрирует значительное снижение во всех категориях ошибок, включая неправильное отнесение к говорящим в случае коротких реплик, неправильное определение границ слов, ошибки при одновременной речи нескольких человек и плохом качестве аудио (см. рис.3).
Область применения разработанной модели пока сводится к ситуациям с ограниченным числом говорящих, имеющих достаточно четкие, хорошо определяемые роли. Задача установления только роли диктора, а не конкретной личности, с одной стороны, позволяет значительно улучшить результаты, привлекая лингвистический материал, но, с другой стороны, требует формирования особого корпуса текстов с размеченными ролями. Отсутствие такого корпуса для расширения сфер использования (пока модель применяется преимущественно в рамках проекта «Understanding Medical Conversations» [1]), а также невозможность оценить вклад привлечения лингвистических данных в улучшение результатов диаризации речи — эти проблемы еще предстоит решить разработчикам Google AI.
Источники
- Joint Speech Recognition and Speaker Diarization via Sequence Transduction INTERSPEECH 2019 September 15–19, 2019, Graz, Austria.
- Understanding Medical Conversations



