
Ручная расшифровка древних надписей — процесс долгий и трудоёмкий. Например, знаменитое линейное письмо Б, при помощи которого писали на острове Крит в XV-XIII вв. до н.э., известно западным исследователям с конца XIX века. Однако на расшифровку и прочтение текстов ушло 67 лет — и это несмотря на то, что язык критских текстов был одной из архаичных форм древнегреческого языка, хорошо известного ученым.

В эпоху Big Data можно попытаться ускорить процесс расшифровки, поручив его искусственному интеллекту. Именно этому посвятила своё исследование команда из Массачусетского технологического института и исследовательского подразделения Google — Google Brain.
В 2010 году одна из соавторок исследования, Регина Барзилай, работала над программой для расшифровки древних надписей. Материалом исследования тогда послужил угаритский — мёртвый язык семитской группы, распространённый в Сирии примерно в то же время, что и линейное письмо Б на Крите. Угаритский известен среди специалистов по древним языкам тем, как он быстро был расшифрован: первые надписи открыли в 1929 году, а в 1931 ученые уже объявили о полной расшифровке.
Программа, созданная Региной Барзилай в 2010 году, была основана на порождающей Байесовской модели и повторяла процессы, характерные для ручной расшифровки: сначала сопоставлялись родственные буквы в иврите и угаритском, затем — морфемы, в конце — когнаты, т.е. похожие друг на друга слова общего происхождения. Программа показала неплохие результаты: она верно сопоставляла 29 из 30 букв и 60% когнатов.
В новой программе Барзилай и ее новые коллеги попытались решить более сложную задачу и сопоставить разные виды письма: линейное письмо Б было силлабическим, а греческое письмо — консонантно-вокалическое. При этом ученые намеревались повысить точность работы алгоритма.
В основе новой программы — нейросеть типа sequence-to-sequence, т.е. и на входе, и на выходе есть некоторая последовательность. Архитектура стандартная: сначала нейросеть-энкодер обрабатывает входные данные, преобразуя их в числа, а затем нейросеть-декодер генерирует ответ. Алгоритм, который исследователи назвали NeuroCipher, сопоставляет когнаты по знакам, причем его работа обусловлена набором закономерностей: к примеру, родственные знаки в когнатах должны идти в одинаковом порядке и иметь одинаковые контексты.
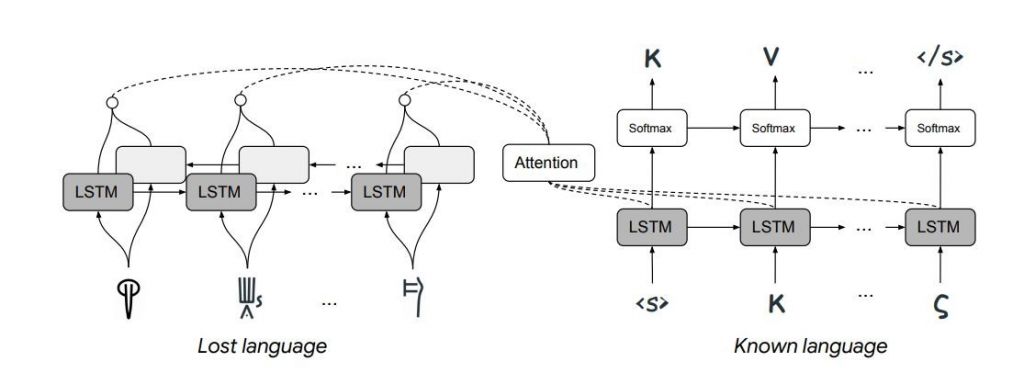
Алгоритм протестировали на трёх наборах когнатов: наборах для угаритского и иврита, взятых из исследования 2010 года, наборах для линейного письма Б и греческого алфавита и контрольном наборе для поиска когнатов в родственных романских языках. Авторы исследования проводили отдельные эксперименты для наборов, состоящих только из когнатов (они назвали эти условия «бесшумными») и наборов, где с одной стороны присутствовали также слова, не имеющие когнатов: к примеру, в эксперименте с линейным письмом Б к набору когнатов, записанных греческим письмом, было добавлено 455 имен собственных.
Результаты получились значительно лучше по сравнению с исследованием 2010 года: NeuroCipher правильно сопоставил 65.9% угаритских слов их когнатами в иврите, 67.3% слов на линейном Б с когнатами, записанными греческим письмом, и 91.6% когнатов в романских языках (проценты приведены для более сложных «шумных» экспериментов, в которых присутствовали слова, не имеющие когнатов).
Сейчас авторы исследования продолжают улучшать показатели NeuroCipher и учат алгоритм сопоставлять не только когнаты. А несколько научных изданий уже задумались, не станет ли эта нейросеть ключом к расшифровке языков, на которых пока не удалось прочитать ни одной надписи, главным образом, линейного письма А. Вряд ли расшифровать линейное письмо А удастся в ближайшее время, но исследование MIT и Google Brain — впечатляющий шаг в эту сторону.
Источники
- Исследование 2019 года
- Исследование 2010 года
- Наш материал о машинном переводе древнеегипетских надписей

