
Уверенность без оснований
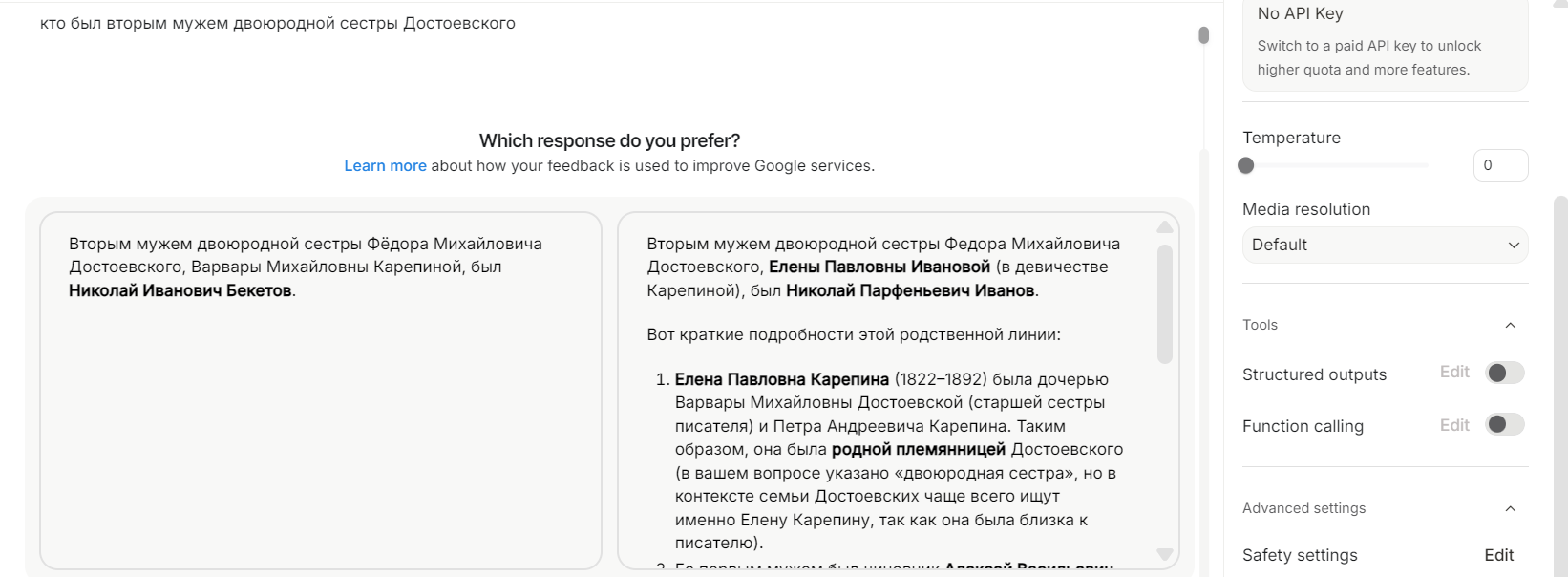
Спросите ChatGPT, в каком году умер Пушкин, — он ответит правильно и уверенно. Спросите, кто был вторым мужем двоюродной сестры Достоевского, — и он ответит так же уверенно. Только на этот раз соврет.

Это одна из самых неприятных особенностей больших языковых моделей (LLM): они не умеют сомневаться. Точнее — не умеют показывать сомнение. Внутри модели вычисляются комбинации ответов, и каждому соответствует значение вероятности. Пользователь видит только один из этих ответов — тот, который был выбран путем довольно сложных вычислений в данный момент. Даже если абсолютное значение вероятности не очень высокое, модель ответит без оговорок, без «возможно», без честного «я не уверен».

В машинном обучении это называется проблемой калибровки (calibration) [1]. Когда хорошо откалиброванная модель говорит «я уверен на 70%», она действительно оказывается права в 70% случаев. Плохо откалиброванная — а это почти все современные LLM — может выдать 95%-ную уверенность там, где для этого нет никаких оснований [2].
Результатом плохой калибровки или неучета настоящих вероятностей ответа становятся галлюцинации LLM — как в примере выше, где ChatGPT 5.2 зачем-то поженил двоюродную сестру Достоевского на Н. Н. Страхове.
Практические последствия LLM-галлюцинаций
Излишняя уверенность и неспособность указать на неуверенность может навредить во многих ситуациях
Медицина. ИИ-системы для диагностики должны не только ставить диагноз, но и указывать уровень уверенности. Когда врач использует ИИ-ассистента, ему критически важно понимать: это надежное заключение, повод для дополнительных исследований или модель просто генерирует правдоподобный текст? Американские законы уже требуют от медицинских ИИ-систем предоставлять информацию о неопределенности.
Юриспруденция. Когда ИИ помогает анализировать контракты или прецеденты, юристу важно знать, где модель уверена, а где «галлюцинирует». Ошибка в юридическом документе может привести к миллионным убыткам.
Digital Humanities. Датировка исторических документов, атрибуция авторства, классификация текстов по эпохам — все эти задачи требуют не точечных предсказаний, а предсказаний с доверительными интервалами. Историк, получивший от алгоритма дату «1847» без указания погрешности, не может использовать эту информацию в научной работе, ведь «1847 год» — это совсем не то же самое, что «между 1840 и 1855 с вероятностью 85%».
Образование. Студенты все чаще используют LLM для учебы. Если модель выдает ложную информацию с той же уверенностью, что и истинную, студент не может отличить надежные факты от галлюцинаций.
Температура уверенности
Технически языковая модель на каждом шаге генерации при помощи алгоритма сэмплирования выбирает следующий токен (слово или его часть). Каждому токену соответствует значение вероятности, а все эти вероятности вместе образуют распределение. Параметр температура (temperature) управляет тем, насколько «размазано» это распределение [3]:
- при температуре близкой к нулю модель почти всегда выбирает самый вероятный токен — ответы получаются более детерминированными, но однообразными;
- при высокой температуре распределение становится более равномерным — появляется креативность, но растет и вероятность галлюцинаций.
Однако температура — это параметр генерации, а не знания. Она не говорит нам, насколько модель уверена в фактической правильности ответа. Модель может с низкой температурой уверенно выдать ложный факт, потому что именно этот факт чаще всего встречался в обучающих данных — даже если он был ошибочным.

Как устроена калибровка
Калибровка вероятностей — это свойство модели, при котором ее выходные вероятности правильно отражают частоту событий в реальности. Другими словами, если модель прогнозирует событие с вероятностью p, то среди всех случаев с таким прогнозом событие должно происходить примерно p × 100% времени. Например, если модель предсказывает класс «+» с вероятностью 0,8, то в хорошо откалиброванной модели примерно 80% таких примеров действительно принадлежат к этому классу. Именно такое соответствие между предсказанными вероятностями и эмпирическими частотами и называется калибровкой вероятностей.
Проблема в том, что современные нейросети систематически переоценивают вероятность события (overconfident). Здесь под событием подразумевается появление конкретного токена после текущего контекста. Во время обучения мы знаем, что этот токен встретился после какой-то последовательности других токенов, но не знаем, как часто такая ситуация возникает. Поэтому наш сигнал для обучения получается как бы слишком грубым — мы говорим модели, что вероятность встречи того или иного токена после конкретного контекста либо 0, либо 1, хотя на самом деле значение может быть любым от нуля до единицы. Из-за этой особенности обучения выходит, что модель стремится всю вероятность назначить одному токену, а всем остальным занизить до 0 (потому что сумма всех вероятностей должна быть равна единице).
Методы калибровки
Temperature scaling — самый простой метод. Представьте, что модель выдала вероятности: 95% для ответа А и 5% для ответа Б. Звучит уверенно, но на практике модель ошибается чаще, чем в 5% случаев — допустим, в 20%. Это и есть плохая калибровка.
Temperature scaling работает так: после обучения основной модели мы находим один дополнительный параметр T (температуру). Этот параметр применяется к логитам — внутренним «сырым» оценкам модели, которые она выдает перед финальным преобразованием в вероятности [4].
Что это дает на практике? При T > 1 распределение сглаживается: вместо 95% / 5% модель может выдать 70% / 30%. Теперь, когда модель говорит о 70% уверенности, она действительно права примерно в 70% случаев. Калибровка улучшилась — заявленная уверенность соответствует реальной точности.
Platt scaling и isotonic regression — более сложные методы, которые обучают отдельную модель для преобразования исходных вероятностей в откалиброванные.
Байесовские нейросети подходят к проблеме фундаментально иначе. Обычная нейросеть хранит каждый вес как одно число (например, вес связи = 0,43). Байесовская нейросеть вместо этого хранит распределение вероятностей для каждого веса (например, «вес с вероятностью 68% находится между 0,4 и 0,46»).
Зачем это нужно? Когда модель делает предсказание, она учитывает не одно значение веса, а множество возможных вариантов. Это автоматически дает оценку неопределенности: если при разных вариантах весов получаются разные ответы, модель не уверена. Это естественный способ моделировать «незнание», однако его невозможно использовать повсеместно, поскольку современные LLM содержат миллиарды весов — для того, чтобы хранить и вычислять распределение для каждого веса, требуются слишком большие вычислительные затраты [5].
Ensemble методы — обучают не одну модель, а несколько (обычно 5–10), и смотрят на разброс их предсказаний. Если все модели дают один ответ — уверенность высокая. Если ответы расходятся — уверенность низкая.
Откуда берется разброс? Ключевой момент: модели обучаются немного по-разному. Например, на разных подвыборках данных (bagging), с разной инициализацией весов, или даже с разными архитектурами. Из-за этого каждая модель «смотрит» на задачу под своим углом и фокусируется на разных паттернах в данных.
Если все модели переобучатся на одинаковую систематическую ошибку в обучающих данных, они действительно будут одинаково «переуверены». Но в областях, где обучающих данных мало или они неоднозначны (то есть именно там, где модель должна сомневаться!), разные модели принимают разные решения, и разброс предсказаний растет [6].
Вербализованная неуверенность
Интересный подход к LLM — не извлекать вероятности из внутренних состояний модели, а просто попросить ее выразить неуверенность словами.
Оказывается, если правильно сформулировать промпт, модель может генерировать ответы вроде:
«Скорее всего, это произошло в 1847 году, хотя я не уверен — возможны варианты от 1845 до 1850»
Или:
«Я не могу надежно ответить на этот вопрос. В моих обучающих данных могла быть противоречивая информация»
Исследования показывают, что такая «вербализованная калибровка» помогает справиться с излишней уверенностью. Модель может научиться говорить, что она сомневается, даже если она не откалибрована внутренне. Однако это скорее полезный хак для пользователей, чем решение проблемы [7].
Что делать прямо сейчас
Пока идеальной калибровки не существует, есть несколько практических советов:
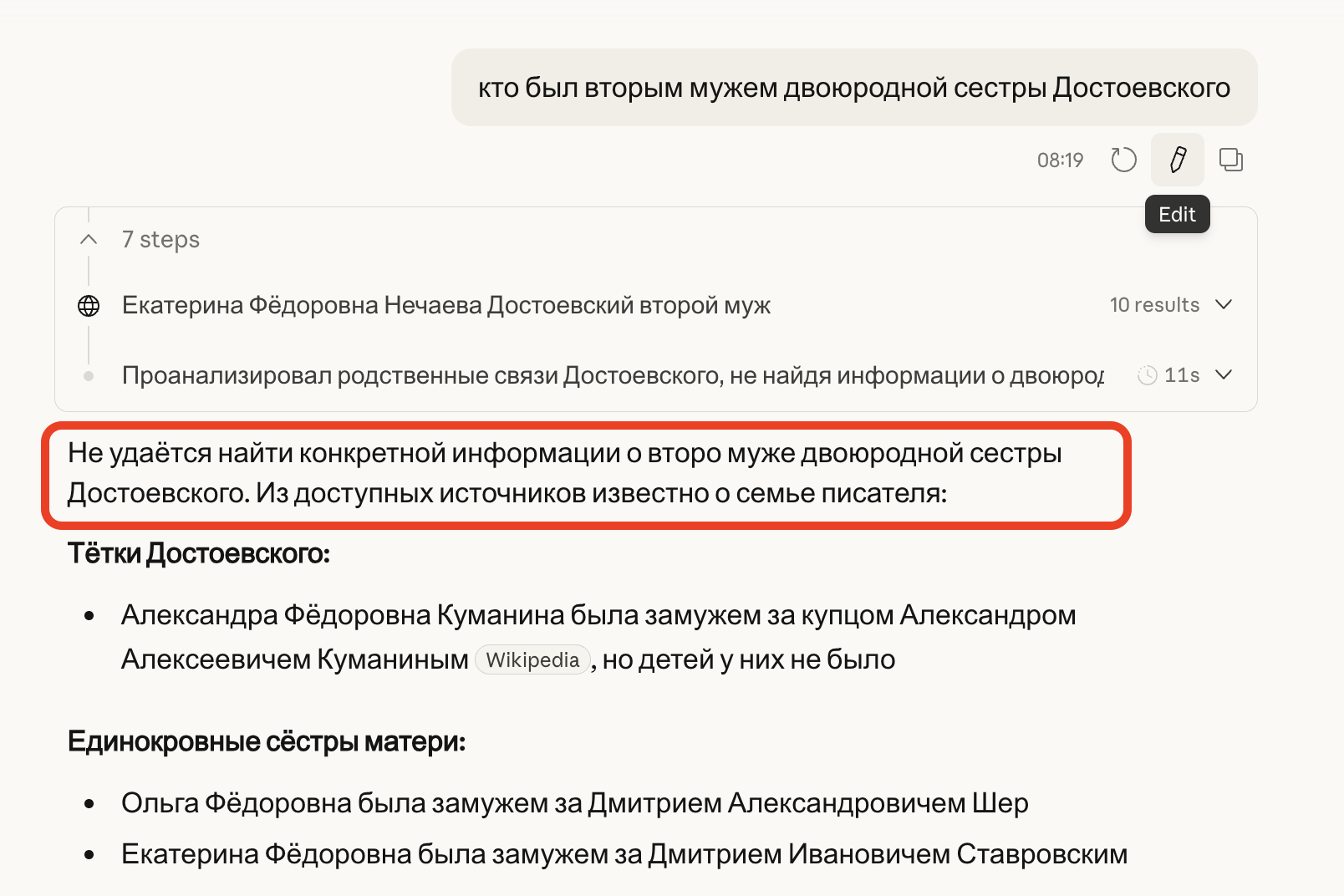
- Используйте reasoning модели (включайте режим thinking насильственно). Когда модель «рассуждает», она часто сама обнаруживает противоречия и выражает сомнения. Та же самая ChatGPT при жестко заданном Thinking-режиме отвечает про Достоевского куда осторожнее:

- Просите модель выразить неуверенность явно. Формулировки вроде «Оцени свою уверенность в этом ответе по шкале от 1 до 10» или «Укажи возможные альтернативные варианты» могут помочь.
- Перепроверяйте критически важную информацию. Особенно цифры, даты, имена и цитаты — именно здесь LLM галлюцинируют чаще всего.
- Сравнивайте ответы нескольких моделей. Если ответы GPT, Claude и Gemini расходятся, то есть повод для дополнительной проверки.
Автор, Басс Роза, благодарит читателей за внимание и признает, что уверенность в корректности этой статьи составляет примерно 73% ± 12%.
Источники
- Wang C. Calibration in deep learning: A survey of the state-of-the-art. 2023. DOI: 10.48550/arXiv.2308.01222.
- Tian Z., Han Z., Chen Y. et al. Overconfidence in llm-as-a-judge: Diagnosis and confidence-driven solution. 2025. DOI: 10.48550/arXiv.2508.06225.
- Li L., Sleem L., Gentile N. et al. Exploring the Impact of Temperature on Large Language Models: Hot or Cold? 2025. DOI: 10.48550/arXiv.2506.07295.
- Ding Z., Han X., Liu P., Niethammer M. Local temperature scaling for probability calibration // Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021. P. 6889–6899. URL: https://openaccess.thecvf.com/content/ICCV2021/html/Ding_Local_Temperature_Scaling_for_Probability_Calibration_ICCV_2021_paper.html.
- Ben‐Gal I. Bayesian networks // Encyclopedia of statistics in quality and reliability. 2008. DOI: 10.1002/9780470061572.eqr089.
- Lakshminarayanan B., Pritzel A., Blundell C. Simple and scalable predictive uncertainty estimation using deep ensembles. Advances in neural information processing systems. 2017. DOI: 10.48550/arXiv.1612.01474.
- Lin S., Hilton J., Evans O. Teaching models to express their uncertainty in words. 2022. DOI: 10.48550/arXiv.2205.14334.

