
Зачин. Жили-были две LLM…
модели GPT-4 и LLaMA-3*. И дали им ученые задание сгенерировать множество альтернативных продолжений для одной и той же истории.
В качестве затравок использовались написанные людьми рассказы с Reddit (WritingPrompts), а также описания сюжетов телевизионных эпизодов из Википедии. Для каждой исходной истории с помощью LLM генерировалось множество альтернативных продолжений.
Завязка. А ученые тем временем…
замыслили поймать модели на повторении и перекладывании из пустого в порожнее.
Чтобы люди смогли оценить оригинальность созданных продолжений, команда исследователей из Microsoft [1] ввела метрику Sui Generis. Она измеряет уникальность сюжетного мотива среди других, сгенерированных с помощью одного и того же запроса к языковой модели.

Метрика Sui Generis была протестирована на 100 рассказах, которые состояли примерно из 3700 сегментов. Подсчитывалось, сколько раз исходный сегмент истории повторяется на нарративном уровне в альтернативных продолжениях.
Значение показателя уникальности соотносилось с оценкой уровня неожиданности: чем уникальнее сюжетный мотив, тем он неожиданнее, и наоборот. Сюжетный ход с высоким показателем уникальности часто соответствует ключевым моментам в развитии истории. И напротив, мотивы с низкой уникальностью не влияют на развитие сюжета и с позиции читательских ожиданий считаются «проходными».
Кульминация. И устроили ученые соревнование…
по продолжению историй между людьми и LLM.
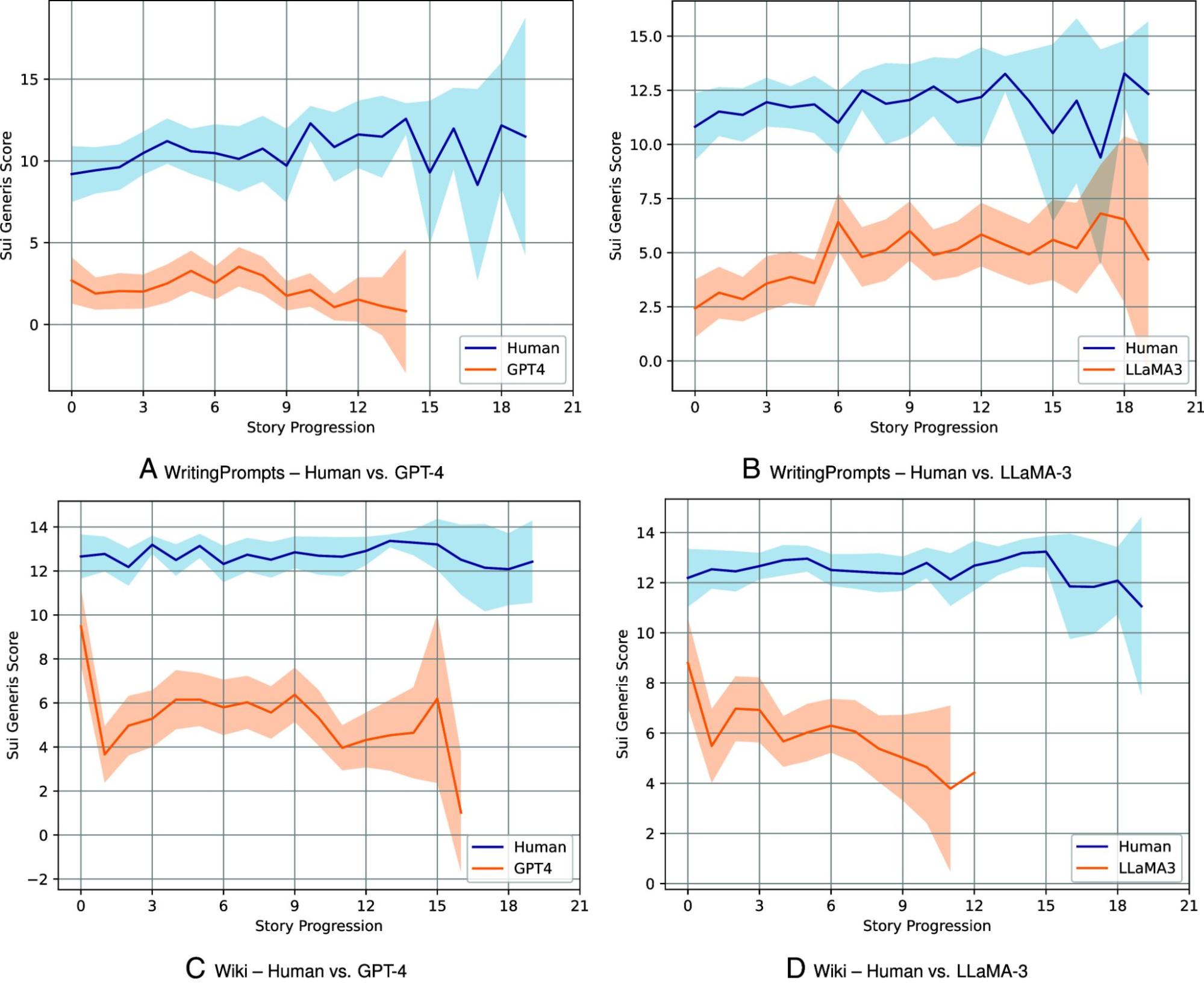
Для сравнения было использовано по 100 текстов каждого типа. Как видно на графиках, тексты, написанные людьми, по обоим наборам данных (WritingPrompts и Википедия) получают по метрике Sui Generis значительно более высокие оценки уникальности, чем истории, сгенерированные LLM.
Кроме того, тексты отличаются по темпу повествования. Истории, написанные людьми, как правило, имеют более медленный темп, плавно вводят сюжетные повороты и подготавливают читателя к развязке. В историях, сгенерированных LLM, повествовательный темпоритм ускорен, сюжетные линии не получают полноценного развития, что приводит к резким и неубедительным развязкам.
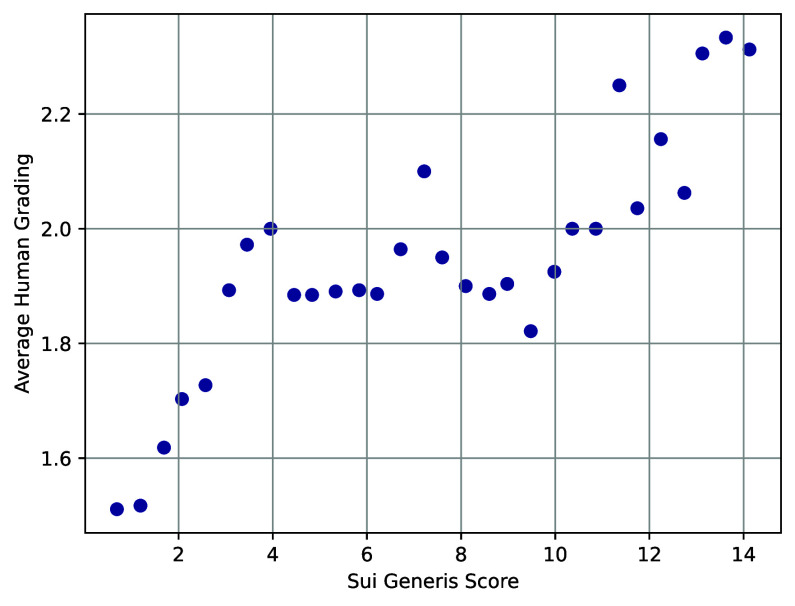
Для оценки неожиданности сюжетов была привлечена независимая группа экспертов. На графике рассеяния показана взаимосвязь между оценками людей и показателями Sui Generis. Оценки по минимальным и максимальным значениям у автоматической метрики и людей совпадают (оценки по оси Y попадают в интервал 1,4 вокруг оценок по оси X). Вместе с тем средние по версии Sui Generis показатели воспринимаются людьми как более неожиданные.
Развязка. А потом оценили работу LLM…
и обнаружили, что оригинальность сгенерированных сюжетных мотивов невысока.
Хотя отдельный текст LLM и выглядит оригинальным, сравнительный анализ нескольких текстов показывает типичность сюжетных структур. Языковые модели (по крайней мере те, что исследованы в этой работе) склонны к шаблонности, и их продолжения историй часто содержат повторяющиеся комбинации сюжетных элементов. В то же время «человеческие» тексты демонстрируют более высокий уровень уникальности и неожиданности.
Модели GPT-4 и LLaMa-3* показали схожие результаты в задаче по генерации художественных текстов, а метрика Sui Generis оказалась полезным инструментом для оценки уникальности и неожиданности LLM-нарративов.
Эпилог. Кафку пока не превзойти
GPT-4 попросили продолжить рассказ Ф. Кафки «И не надейся». LLM сделала 100 генераций, в которых сюжетные мотивы часто повторялись. Так, ровно в половине случаев, полицейский указывает повернуть налево на втором повороте, а в 18 из 100 генерациях рассказчику нужно повернуть направо. Хоть как-то приблизиться к варианту Кафки (на вопрос рассказчика полицейский говорит: «Сдавайся!») GPT-4 не удалось.

Так что сказочке, созданной человеком, пока точно не конец, а кто прочитал статью до конца — молодец!
*Компания Meta, выпустившая модель Llama, признана экстремистской и запрещенной на территории РФ.
Источник: Xu W., Jojic N., Rao S. et al. Echoes in AI: Quantifying lack of plot diversity in LLM outputs // Proc. Natl. Acad. Sci. USA. 2025. Vol. 122. N. 35. P. e2504966122. DOI: 10.1073/pnas.2504966122.

