
Убийца — дворецкий
С одной стороны, художественная литература вполне предсказуема: если она вписывается в жанровые конвенции, мы знаем, чего ожидать. В детективе убийцей окажется садовник или дворецкий, в сказке принц спасет принцессу, в древнегреческой трагедии в конце все умрут.
Группа ученых под руководством Маартена Сапа проверила это предположение, используя языковую модель на основе популярной сегодня нейросетевой архитектуры GPT. Эта модель предсказывает вероятность появления предложения в том или ином контексте.
Сап и его коллеги использовали корпус Hippocorpus, который они собрали самостоятельно. Они разделили информантов на две группы: одну попросили придумать небольшую историю на 15-25 предложений, вторую — описать какую-нибудь ситуацию, которая произошла с ними за последние полгода. Дальше они разбили тексты на предложения и с помощью языковой модели попытались восстановить их последовательность.
Оказалось, что на выдуманных историях модель работает лучше. Ей было легче предсказать, какое предложение последует за предыдущим. Из этого Сап и коллеги сделали вывод, что выдуманные истории, в отличие от описания реальных ситуаций, подвергаются нарративизации, то есть события в них более линейны и предсказуемы.
… или нет
Предыдущее утверждение легко опровергнуть интуитивно: художественная литература во многом построена на неожиданности. Если книга не нарушает ожидания читателя, ее будет неинтересно читать.
Тед Андервуд, ученый из университета Иллинойса, решил сравнить тексты 32 биографий и 32 романов. Метод, который он использовал, похож на метод Сапа и коллег: он разбивал тексты на предложения и с помощью нейронной сети BERT восстанавливал их. Однако тексты, с которыми он работал, были гораздо длиннее.
Результат, который получил Андервуд, был прямо противоположен выводам Сапа: романы нейросеть восстанавливала гораздо хуже, чем биографии. На рисунке ниже можно увидеть результат ее работы: предложения из романа «Гордость и предубеждение» она не смогла отделить от предложений из научно-фантастического романа Э. Эббота «Флатландия». Читатель удивится, когда к концу абзаца выяснится, что мистер Дарси разговаривает с разумной сферой, которая рассказывает ему о бананах, но это совсем не то удивление, которое можно ожидать.

Нейросети — не решение
Андервуд также оценил степень сходства между предложениями, которые нейросеть поставила друг за другом. Для этого он использовал GloVe — модель, которая превращает предложения в векторы одинаковой длины и при помощи косинусного расстояния оценивает, насколько далеко они находятся друг от друга.
Разница между оценками BERT и косинусного расстояния заметна по третьей и пятой строкам таблицы выше. Косинусное расстояние показывает, что третье предложение (где упоминаются некие голубые сферы) меньше похоже на второе (рассказывающее о соседях и родственниках), чем пятое на четвертое (в них, по крайней мере, одинаковые местоимения). Тем временем BERT решил, что третье предложение идет за вторым с большей вероятностью, чем пятое за четвертым).
Судя по этим неоднозначным результатам, предложение — слишком мелкая единица, чтобы с ее помощью оценивать предсказуемость произведения. К тому же, когда мы читаем книги, мы представляем их как последовательность событий. Поэтому гораздо легче пытаться угадать, какое из двух событий встречается в книге раньше.
Угадай событие
Для этого Андервуд обучил модель логистической регрессии на текстах 48 детективных романов. Он разбил их на отрывки по тысяче слов, с помощью GloVe он преобразовал эти отрывки в векторы и попытался предсказать, какие из двух случайно взятых фрагментов идут друг за другом. На рисунке 2 представлены результаты его исследования.
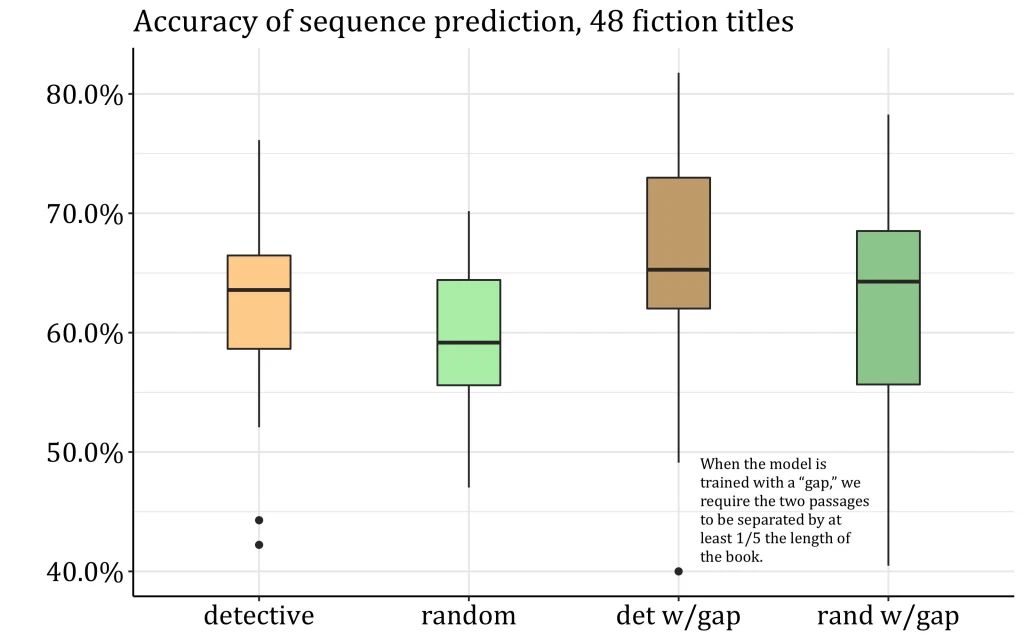
Как видно на графике, в целом точность определения последовательности средняя: около 63 процентов. Медианная точность возрастает до 64-65 процентов, когда модель обучают на фрагментах, которые далеко отстоят друг от друга в книге (больше, чем на 20% от общего количества слов). Такая точность кажется невысокой, но если такую же задачу дать человеку, вряд ли точность его предсказаний будет значительно выше.
Когда математика не работает
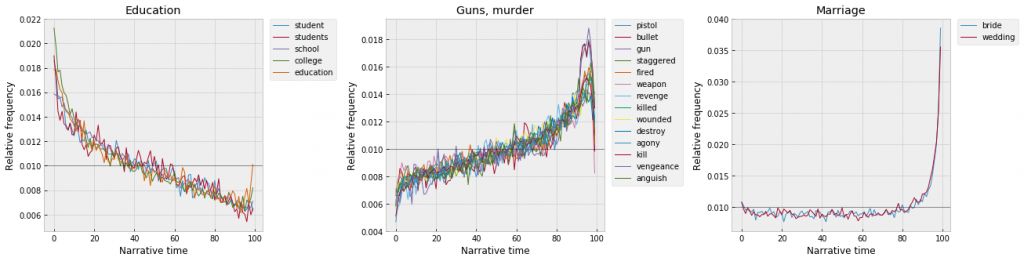
Если математика не работает, можно попытаться выделить лингвистические особенности художественной литературы, которые делают ее предсказуемой. Например, Дэвид Макклур и Скотт Эндерле, анализируя тексты детективов, обнаружили, что слова «свидетель», «вина», «тюрьма» чаще всего появляются ближе к концу романа.
Это не первое исследование Макклура и его коллег по распределению тематических слов в литературе. Ранее на 50 тысячах книг они показали, как частотность слов, связанных с убийством, перестрелками и т.п возрастает незадолго перед концом текстов (видимо, в момент кульминации, перед развязкой), слова образовательной тематики чаще упоминаются в началах романов (представление героев, их взросление), а свадьбы гораздо чаще упоминаются в самом конце.
В этой же работе они показали, возможно, наиболее банальный результат в истории цифрового литературоведения. А именно: определенный артикль the гораздо чаще употребляется в конце, а неопределенные артикли a и an — в начале. Например, в начале романа вполне может встретиться такое предложение: «A mysterious old man enters a room» («Загадочный мужчина входит в комнату»). Через несколько страниц уже будет использоваться определенный артикль.
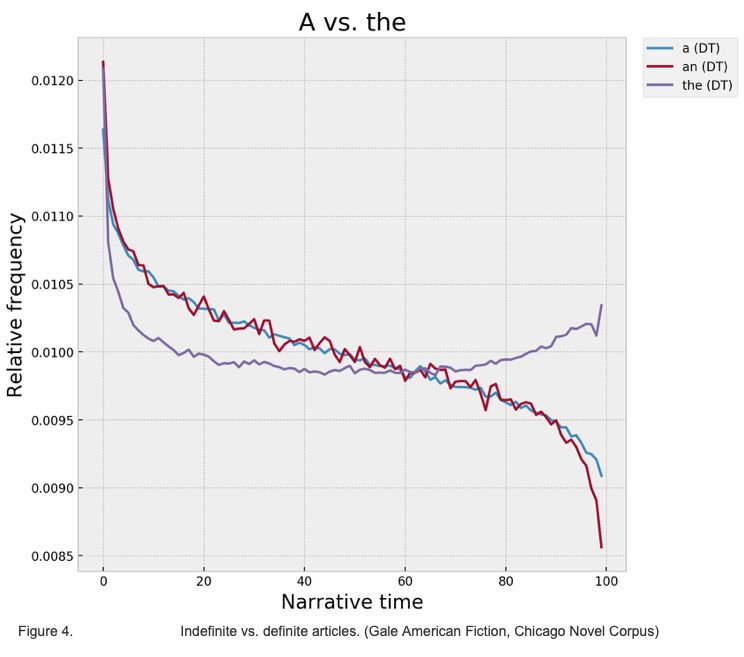
Конечно, с помощью таких особенностей восстановить сюжет не получится, но можно гораздо лучше решить ту же задачу: определить, какой из двух фрагментов идет первым.
Андервуд использовал работы Макклура и Эндерле и подтвердил их предположения: в художественной литературе частота использования the возрастает к концу. Выборка, с которой работал Андервуд, слишком маленькая, чтобы сделать статистически значимый вывод, но он заметил, что эта особенность не характерна для нон-фикшена: в биографиях точность решения таким методом гораздо ниже.
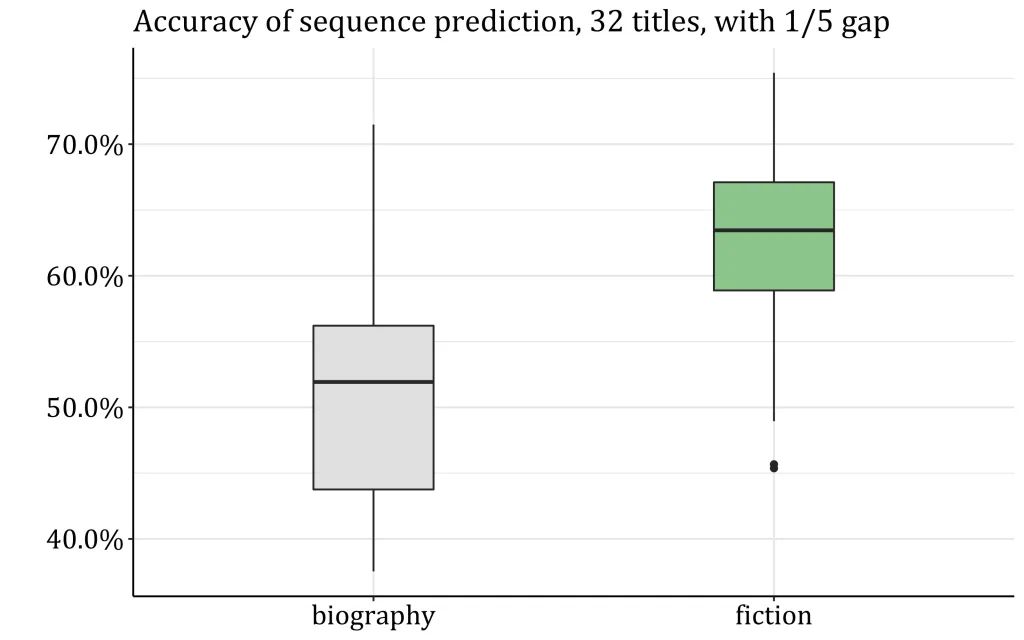
Работы Андервуда и других авторов показывают, что предсказывать события в книгах абсолютно точно пока невозможно. Однако они отмечают важные для будущих исследований черты: например, что в ряде случаев расшифровать последовательность событий в художественной прозе бывает даже легче, чем в нон-фикшене.
Чем больше разных данных соберут ученые, тем проще алгоритмам будет распознавать текст. И однажды, возможно, миллионы школьников и студентов, которым приходится читать по пять книг в неделю, вздохнут с облегчением. Хотя наука, конечно, делается не для этого. Ее цель — научиться измерять то, что пока неизмеримо: устройство художественного текста и стоящие за ним механизмы литературного творчества.
