
Суммаризация текстов
Суммаризация — составление краткого пересказа автоматическим способом. Она бывает двух видов: экстрактивная и абстрактивная. В первом случае из текста извлекаются наиболее важные отрывки в неизменном виде, во втором — генерируется новый текст на основе заданного. Подробнее о суммаризации можно почитать вот тут, а здесь — пройти туториал от HuggingFace (также есть перевод на русский язык).
Суммаризация применяется везде, где существует потребность в сокращении написанного. Например, если ввести запрос summarization в сервисе Dimensions, в выдачу попадут статьи о суммаризации медицинских и юридических документов, патентов. Сегодня мы остановимся на эксперименте ученых Колумбийского университета по суммаризации нарратива длинных — объемом около 10 тыс. слов — рассказов [1].
Идея исследования
Авторы задались вопросом, насколько LLM, большие языковые модели, способны «понимать» нарратив — повествование о последовательности событий (о видах нарратива и его отличиях от собственно сюжета или фабулы СБъ уже писал тут). Для этого хорошо подошли рассказы, поскольку они могут иметь нелинейный нарратив и представлять некоторую сложность для пересказа. Нередко в текстах этого жанра используются разные языки, выдуманные фразы.
LLM имеют доступ буквально ко всему интернету, где содержатся уже опубликованные художественные произведения (ср. Project Gutenberg, CliCK Dickens и другие открытые корпуса). Поэтому ученые решили протестировать работу LLM на текстах, которых модели точно никогда не видели. В этом помогли реальные писатели, предоставившие свои еще не выложенные онлайн и никем не обсуждавшиеся публично произведения.
Как ученые тестировали языковые модели
Модели и данные
Использовали три модели: GPT-4, Llama-2-70B-chat* и Claude-2.1. Датасет насчитывает 25 рассказов девяти авторов (по пять рассказов от четырех авторов и по одному от пяти). Описательную статистику можно увидеть в таблице ниже.

Таблица 1. Описательная статистика датасета. Средние длины указаны в токенах (словах). Источник [1]
Генерация саммари
Для каждого рассказа было сгенерировано по три саммари — по одному от модели. Для Claude и GPT-4 использовался одинаковый промпт (текстовая затравка), поскольку их контекстное окно позволяет обрабатывать каждый из рассказов целиком. Интересно, что Claude отказалась суммаризовать два произведения: они содержали неэтичный (по ее настройкам) контент.
Llama* же принимает более короткие тексты, поэтому средние и длинные рассказы делились на несколько отрывков (чанков) по разделам или параграфам. Сначала модель пересказывала каждый из чанков, а затем генерировала финальный вариант по соединенным промежуточным саммари.
Почитать подробнее о настройках каждой модели и увидеть промпты можно в оригинальной статье [1].
Схема генерации изображена на Рисунке 1.
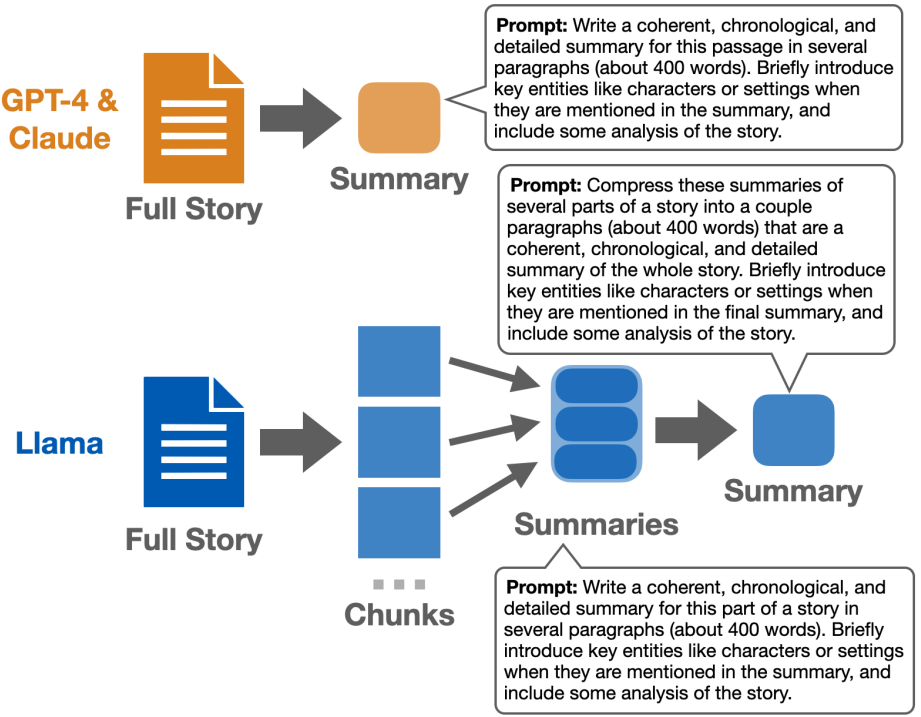
Рисунок 1. Схема генерации саммари. Длина саммари предполагала ~400 слов. Кроме саммари, модели должны были сгенерировать анализ рассказов. Источник: [1]
Описательную статистику по сгенерированным текстам можно увидеть в Таблице 2.

Таблица 2. Описательная статистика сгенерированных саммари (усредненные значения). Источник: [1]
Поясним, что отражает каждый из столбцов:
- охват (coverage) — процент слов, заимствованных из оригинального текста;
- плотность (density) — средняя длина отрывков, совпадающих с оригиналом;
- компрессия (compression) — во сколько раз саммари короче оригинала;
- n-граммы (последовательности из n символов) — средняя доля совпадений между n-граммами саммари и оригинального рассказа;
- наибольшая общая подстрока — среднее количество слов наиболее длинного сегмента, точь-в-точь повторяющего исходный рассказ.
Исследователи отмечают, что Llama* заимствовала оригинальный текст меньше всего, в отличие от GPT-4, способной скопировать даже 6-граммы. Claude тем временем показала наиболее высокое значение компрессии.
Как оценить саммари?
Работу моделей судили как авторы рассказов, так и сами LLM (об этом ниже). Оценка проводилась по трем уровням: фрагментов текста, самого саммари и рассказываемой истории.
Внимание обращалось на следующие аспекты:
- охват (coverage) — упоминание важных сюжетных точек. Выше уже шла речь об охвате на лексическом уровне текста, в данном случае метрика оценивает смысловую составляющую;
- достоверность (faithfulness) — наличие несуществующих в исходном тексте деталей или искажение истории;
- связность (coherence) текста;
- анализ — наличие верной интерпретации главного посыла или темы рассказа. То самое «что хотел сказать автор».
Уровень фрагментов текста (span-level)
Авторам было предложено самостоятельно выделить отрывки саммари, в которых были допущены неточности, и оценить по аспектам, приведенным выше. Для каждого из них были выделены категории ошибок.
Охват (coverage). В саммари включены незначительные части рассказа или важные для понимания истории поинты переданы смазанно.
Достоверность (faithfulness). Ошибки в:
- передаче чувств, эмоциональных состояний, реакций персонажей;
- описании персонажей;
- причинно-следственных связях событий;
- действиях персонажей;
- хронотопе.
Связность (coherence). Детали не соотносятся друг с другом, есть переключение с одной сцены на другую без связки между ними, вводятся новые темы/события/персонажи без контекста или необоснованно повторяются детали.
Анализ. Интерпретация некорректна или не соответствует фактам рассказа.
Уровень саммари (summary-level)
Здесь авторам нужно было оценить тексты саммари по шкале Лайкерта. Примеры вопросов и интерфейс для работы можно увидеть на рисунке ниже.

Рисунок 2. Интерфейс оценки саммари по шкале Лайкерта. Источник: [1]
GPT-4 и Claude тоже было предложено оценить свою работу по этому опроснику.
Исследователи воспользовались и автоматическими метриками: традиционными ROUGE (читайте оригинальную статью и пробуйте приложение от HF) и BERTScore (статья и приложение) и (относительно) новыми, предназначенными для оценки достоверности саммари: AlignScore [2], UniEval [3] и MiniCheck [4]. Наконец, связность и достоверность была оценена с помощью BooookScore [5] и FABLES [6].
Уровень рассказываемой истории (story-level)
Здесь изучалось воздействие стиля писателя на считывание истории и повествования моделью.
Уровень был разбит на три подуровня:
- нарратива, на котором оценивалось влияние надежного и ненадежного рассказчика на стиль;
- истории, где анализировались события и способы повествования о них;
- дискурса, где сравнивались рассказы по факту (не)включения флэшбеков в линию повествования.
Также была подсчитана читаемость произведений по шкале Флэша-Кинкейда. Этот тест предполагает оценку, на каком году обучения (по американской системе образования) человек может спокойно прочитать и понять тот или иной фрагмент текста. Пример оценки можно увидеть на Рисунке 3.

Рисунок 3. Пример оценки экспозиции рассказа по индексу удобочитаемости Флэша-Кинкейда. Верхний текст может понять первоклассник, а последний рассчитан на выпускников старшей школы. Источник: [1]
Так может ли LLM уловить нарратив?
Оценка саммари
В целом модели хорошо обработали тексты. GPT-4 и Claude смогли предоставить идеальные саммари, но только в половине случаев. Кроме того, пересказы первой модели лидируют по всем параметрам (см. Таблицу 3). При этом оценка по критерию достоверности у всех моделей ниже, чем по трем другим аспектам.
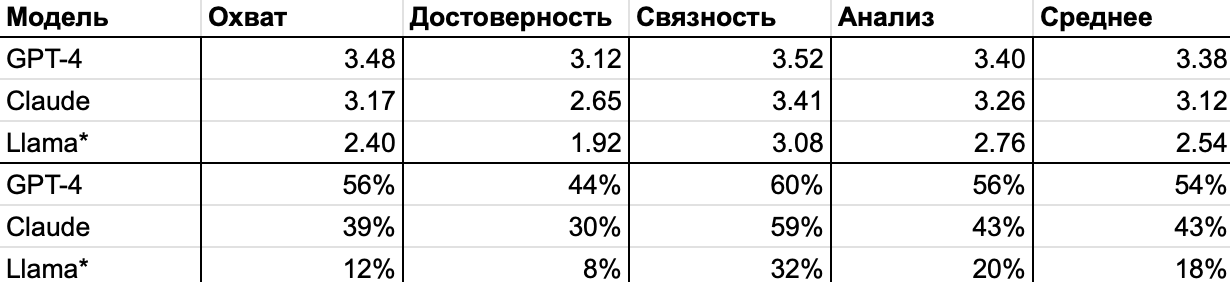
Таблица 3. Средние оценки саммари, выставленные писателями. Первые ряды показывают оценку по 4-балльной шкале Лайкерта, далее отмечен процент саммари, получивших наивысший балл (4). Источник: [1]
Оценка интерпретации
56% саммари GPT-4 содержат верную интерпретацию рассказов (с точки зрения самих же авторов). Тем не менее даже в тех вариантах, что получили оценку 4 из 4 за анализ произведения, допущена хотя бы одна ошибка по данному параметру. На уровне фрагментов в пересказах допущено столько же ошибок по критерию интерпретации, сколько и по достоверности. Все цифры можно увидеть в Таблице 4.
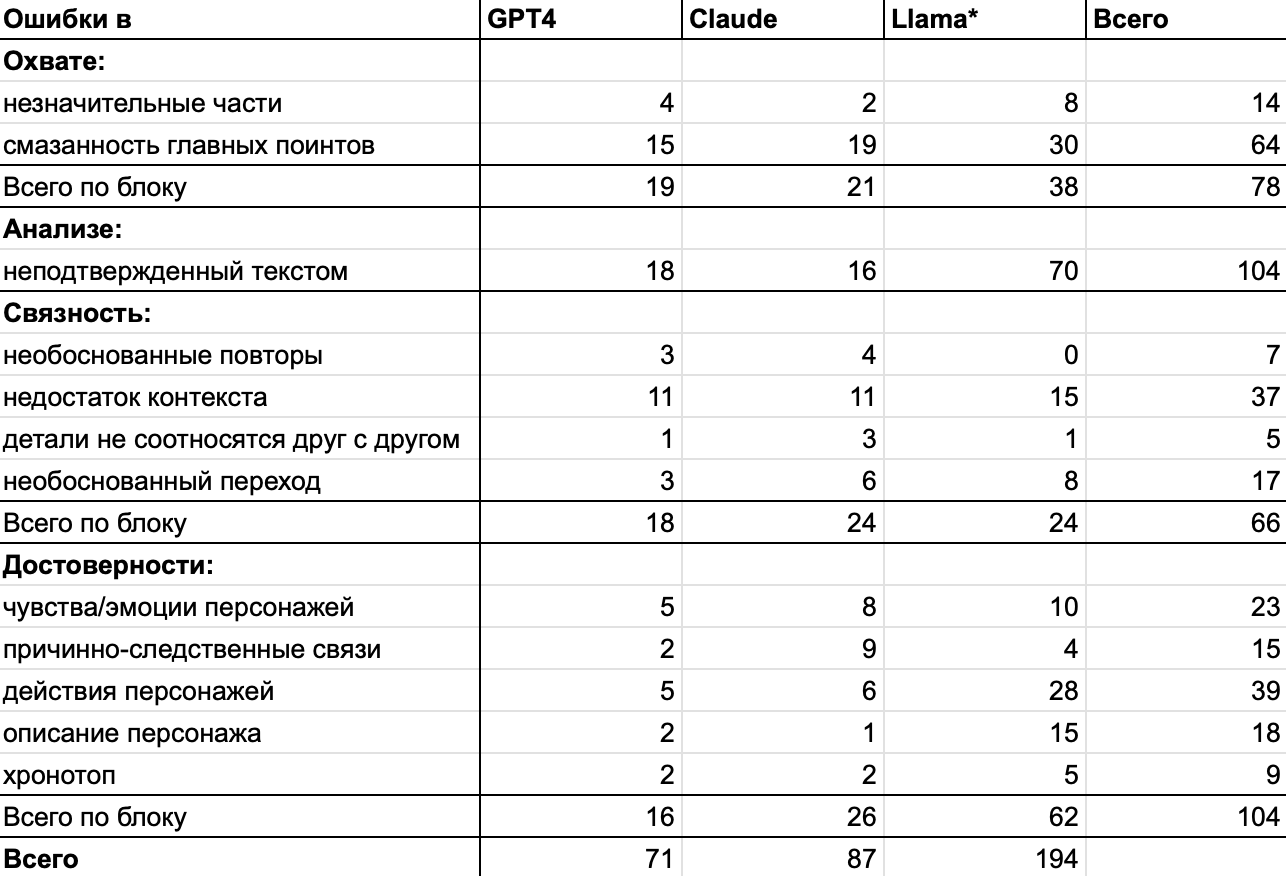
Таблица 4. Количество ошибок в саммари по каждой категории. Источник: [1]
Если кратко, качество саммари и интерпретации GPT-4 и Claude оценены примерно на одинаковом уровне (разница статистически незначима, но нужно помнить, что вторая модель отказалась пересказывать два текста). А вот Llama* справилась хуже по всем параметрам.
Примеры лучших интерпретаций можно увидеть на Рисунке 4.

Рисунок 4. Интерпретации, получившие наивысшую оценку. Источник: [1]
Помните, что GPT-4 и Claude должны были самостоятельно оценить свои результаты? Получилось так, что по каким-то параметрам (например, связности) они завысили баллы по сравнению с оценками авторов рассказов, другие (охват) — наоборот, недооценили. Ученые пришли к выводу, что при работе с данными LLM и обозначенной задачей человеческая оценка будет надежнее.
Что могло вызвать затруднение?
Длина текста не стала препятствием для GPT-4 и Claude: они одинаково хорошо справились и со сравнительно длинными, и с более короткими рассказами. А вот саммари Llama* становились хуже по мере увеличения количества слов в тексте.
Явной корреляции между сложностью текста для прочтения и количеством допущенных в саммари ошибок выявить не удалось. Зато для всех моделей стал проблемой ненадежный рассказчик — его наличие провоцировало больше ошибок в саммари.
Что говорят писатели?
Некоторые писатели поделились, что LLM при интерпретации выявили вещи, которые сами авторы не замечали ранее (!). Подобный колаб может быть плодотворным. «Писатели также оставили позитивный фидбэк вроде: «Я был(а) рад(а) прочитать это [саммари]… Оно показало слабые точки моего рассказа… некоторые второстепенные персонажи оказались более плоскими, чем мне хотелось бы» [1]**.
Кстати, о том, как не бояться нейросетей, а сотрудничать с ними при написании текстов, можно почитать в нашем материале.
В оригинальной статье также упомянуты расходы на эксперимент. Если вам нужен референс или просто интересно, сколько стоит использование трех моделей, просьба об участии писателей и другие вещи, посмотрите подробные приложения в источнике [1].
Заключение
Сегодня мы кратко поговорили о суммаризация текстов и посмотрели на эксперимент по резюмированию нарратива рассказов с помощью LLM. Модели смогли уловить ход повествования и даже проинтерпретировать произведения, однако допустили много ошибок при работе с ненадежным рассказчиком.
Если вам интересна тема сосуществования писателей и нейросетей, советуем почитать материалы специального проекта «Системного Блока» «Подтекст».
*Компания Meta, выпустившая модель Llama, признана экстремистской и запрещенной на территории РФ.
** ”Writers also left positive feedback like, «I’m glad to have read this [summary]… It shows some [weaknesses] of my story… some minor characters are more flat than I want»” [1].
Источники
- Subbiah M., Zhang S., Chilton L. B., McKeown K. Reading Subtext: Evaluating Large Language Models on Short Story Summarization with Writers. 2024. [Электронный ресурс] URL: https://arxiv.org/abs/2403.01061 (дата обращения: 13.02.2025).
- Zha Yu., Yang Yi., Li R., Hu Zhi. AlignScore: Evaluating factual consistency with a unified alignment function. In: Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics, 2023, Vol. 1: Long Papers. Pp.: 11328–11348. Toronto, Canada. Association for Computational Linguistics.
- Zhong M., Liu Y., Yin D., Mao Y., J. Jiao Y., Liu P., Zhu C., Ji H., Han J. Towards a unified multi-dimensional evaluator for text generation. In: Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, 2022. Pp. 2023–2038. Abu Dhabi, United Arab Emirates. Association for Computational Linguistics.
- Tang L., Laban P., Durrett G. MiniCheck: Efficient Fact-Checking of LLMs on Grounding Documents. 2024. arXiv preprint arXiv:2404.10774.
- Chang Y., Lo K., Goyal T., Iyyer M. Booookscore: A systematic exploration of book-length summarization in the era of LLMs. In: The Twelfth International Conference on Learning Representations, 2024.
- Kim Y., Chang Y., Karpinska M., Garimella A., Manjunatha V., Lo K., Goyal T., Iyyer M. Fables: Evaluating faithfulness and content selection in book-length summarization. 2024. arXiv preprint arXiv:2404.01261.

