
Зачем нужен автоэнкодер?
Сейчас в мире существуют более 120 зеттабайт данных (= около 132 триллионов гигабайт). К 2025 году аналитики предсказывают увеличение этого числа до 180 зеттабайт. И многие из этих данных имеют сложную структуру, обработка и передача которой требуют большого количества времени и высоких вычислительных мощностей. Нейросети помогают справляться с такими объёмами.
Для начала представим, что у нас есть фотография и мы хотим найти похожие на неё снимки среди большой коллекции других фотографий. Если мы будем попиксельно сравнивать полноразмерные картинки — на поиск уйдёт слишком много времени. Более того, даже если фотографии изображают один и тот же объект, они могут очень сильно различаться ракурсом, освещением, качеством и т. д. В таком случае поиск по полному совпадению выдаст нерелевантные результаты. Однако если мы «сожмём» изображения, сохранив только ключевые признаки, то процесс их сравнения и поиск совпадений будут гораздо быстрее и точнее.
Итак, чтобы сложные данные представить сжато и информативно, используется специальный вид нейросетей — автоэнкодер, или автокодировщик (от англ. autoencoder).
Как устроен автоэнкодер?
Для обучения автоэнкодера не нужна размеченная обучающая выборка, достаточно просто самих данных: изображений/текстов/аудиофайлов. Такой процесс называется машинным обучением без учителя. Подробнее о том, что такое машинное обучение и как оно работает, — читайте в глоссарии «Системного Блока».
Автоэнкодер состоит из двух частей. Первая — энкодер, который сжимает высокоразмерные данные. Например, исходные параметры изображения: 224×224×3 (ширина, высота и три цвета RGB). Перемножив эти характеристики, получим размерность изображения, равную 150 528. Энкодер сжимает такую картинку до размерности 128 — то есть происходит сжатие в 1 176 раз! Результат работы энкодера — это вектор (или набор векторов).
Вторая часть — декодер, и его задача реконструировать исходные данные из сжатого представления. Работа декодера во многом симметрична работе энкодера: он производит с полученными векторами обратные трансформации. При обучении автоэнкодера обе части взаимодействуют друг с другом: энкодер учится оставлять в сжатом представлении только самую важную информацию, а декодер — наиболее качественно восстанавливать исходные данные. Кстати, и энкодер, и декодер — это нейронные сети.
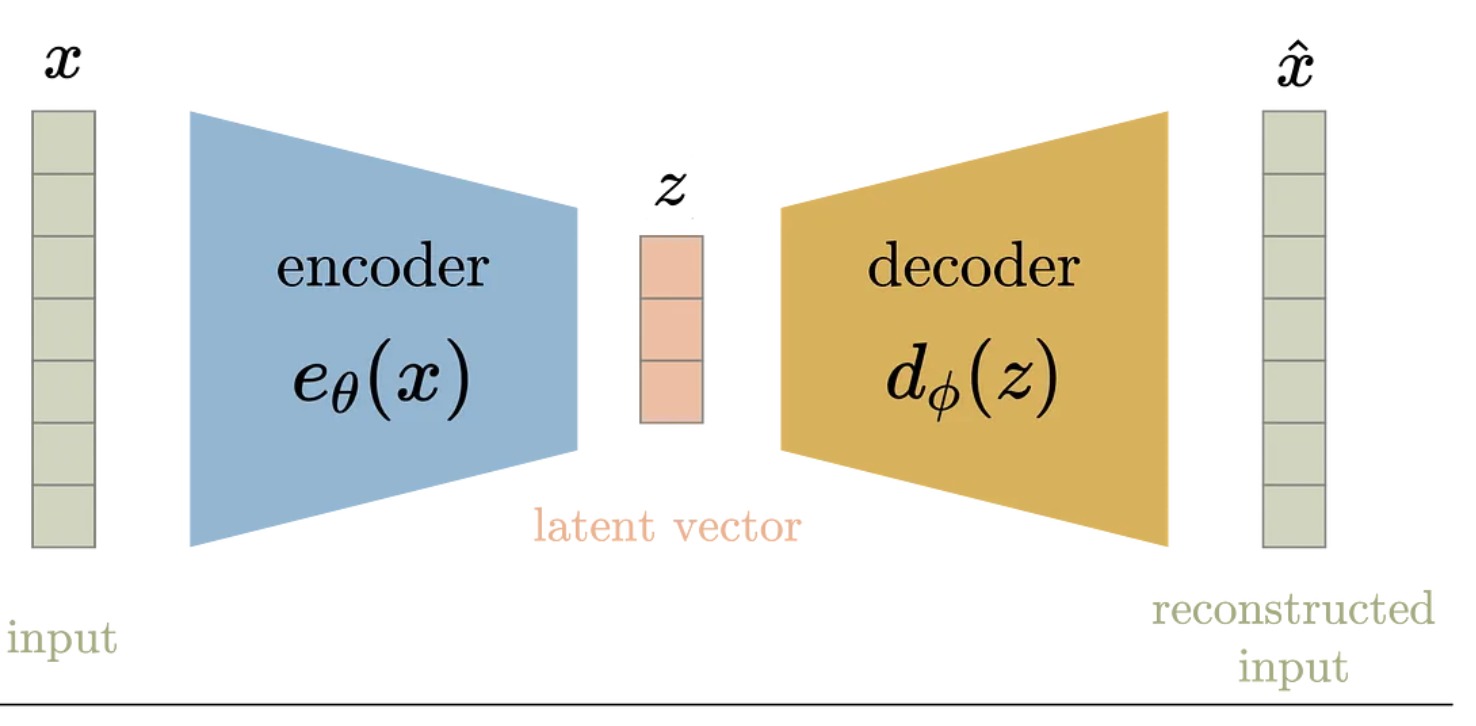
Что такое латентное пространство?
Как мы уже поняли, энкодер строит по высокоразмерному представлению объекта его низкоразмерное представление. Низкоразмерные представления объектов образуют скрытое, или латентное, пространство. Пространство называют скрытым, так как оно содержит скрытые, сложные признаки данных. Поэтому и представления, которые выдаёт энкодер, также называют скрытыми, или латентными. Скрытое представление объекта — это вектор, содержащий основную информацию об объекте. Так, при подаче энкодеру фотографии собаки, нейросеть оставляет информацию о внешних чертах собаки, но отбрасывает информацию о фоне.
Энкодер располагает векторы в латентном пространстве так, что у схожих объектов они будут располагаться близко друг к другу, образуя кластеры, а у различных — далеко. Например, при подаче хорошо обученному энкодеру фотографии кошки он расположит её вектор близко к тем, которые соответствуют фотографиям кошек, а вектор фотографии собаки он поставит в другом месте, близко к векторам собак.

Декодер после обучения может восстанавливать из латентного вектора исходный высокоразмерный объект. Однако он может использоваться не только для этого, но и для генерации совершенно новых данных. Нужно просто подать ему латентное представление тех объектов, которых не было в обучающих данных. Остаётся вопрос — откуда брать латентные представления, если мы не используем энкодер? Об этом расскажем в следующем материале про вариационный автоэнкодер.
Пример работы автоэнкодера
Одна из областей применения автоэнкодеров — шумоподавление. Ведь если нейросеть может определить, что на картинке главное, а что нет, то можно использовать её для удаления шума с изображений.
Для демонстрации работы автоэнкодера возьмём, к примеру, набор данных Fashion-MNIST, который содержит 70 тысяч изображений одежды и аксессуаров. Они выглядят вот так:

Картинки внутри Fashion-MNIST чёрно-белые, но в этой статье они отображаются цветными, потому что так красивее результат работы автоэнкодера на цветных изображениях лучше заметен.
Данные самой выборки не содержат шум, поэтому мы наложим его искусственно:

Далее обучим модель автоэнкодера работать с изображениями, на которых есть шум. Энкодер получает на вход зашумленные изображения выборки, а декодер после обучения должен возвращать исходные изображения без шума.
Посмотрим на то, как обученный автоэнкодер может избавляться от шума на изображениях:
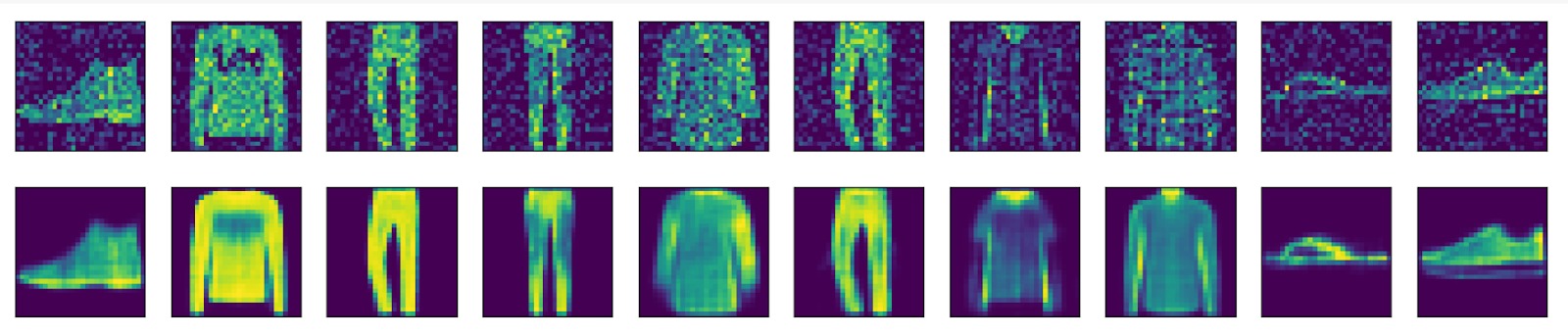
На приведённом примере видно, что модель можно эффективно использовать для шумоподавления: все предметы гардероба можно идентифицировать (даже шлёпанцы, которые до обработки было бы очень сложно определить). Однако заметен и один из недостатков автоэнкодеров — потеря качества и мелких деталей в реконструированных данных. Подробнее о недостатках автоэнкодеров и том, как их исправить, можно будет прочитать в следующем материале про вариационный автоэнкодер.
А заглянув в код, вы можете увидеть, как проходит работа с автоэнкодером изнутри.
Где ещё применяется автоэнкодер?
Из-за способности автоэнкодеров к обработке сложных данных их часто применяют для работы с картинками и видео (видеоряд можно представить как последовательность кадров, то есть тех же картинок). Почти в каждом современном смартфоне есть функция распознавания лиц: сенсоры устройства сканируют лицо, и смартфон определяет, владелец это или нет. Реализовать такую технологию можно при помощи автоэнкодера. При первоначальной настройке с сенсоров собираются данные о лице владельца, далее энкодер сжимает данные в вектор и сохраняет его в памяти устройства. При попытке разблокировки сенсоры вновь собирают данные, они кодируются в вектор и сравниваются с векторами, сохранёнными при первичной настройке. Если векторы достаточно близки, значит, сжатое представление лица похоже на сжатое представление лица владельца, а значит, и само лицо похоже на лицо владельца. Кстати, подобная система также используется для классификации и группировки фотографий в галерее смартфона.



