
Большие языковые модели (LLM) способны искать переклички между текстами — скрытые цитаты, аллюзии, реминисценции, повторения целых сюжетных поворотов, в общем, сходства разной природы — как преднамеренные, так и бессознательные. Однако на этом сложном направлении исследований сегодня делается намного меньше, чем могло бы. Обсудим, как может выглядеть такой поиск, каких результатов уже можно добиться с современными моделями и куда идти дальше.
Семантический поиск
Возможности LLM кардинально меняют поиск в интернете, поскольку позволяют перейти от поиска по ключевым словам к поиску «по смыслам», т. е. по содержательным пересечениям. О таком семантическом поиске «Системный Блокъ» уже писал, но я все же приведу пример. Представьте, что мы хотим найти произведения искусства, которые выражают определенную философскую идею. Те алгоритмы поиска, к которым мы за много лет привыкли (пользуясь Google и Яндексом), с этой задачей могут справиться только в редких случаях — если кто-то именно про это написал и к тому же эта запись была проиндексирована. LLM же дают прямые ответы на подобные запросы, и качество этих ответов неуклонно растет вместе с качеством моделей. Такими разработками в области семантического поиска занимаются самые заметные игроки: Google, OpenAI и т. д.
LLM в поиске
Подробнее про использование компанией Google больших языковых моделей в поиске см. тут и тут; как их использует OpenAI — тут и тут. О том, что LLM революционно изменит поиск в интернете и как это может быть реализовано сейчас, см. [1] (pdf-файл — здесь).

Как работает архитектура семантического поиска от Google: на первом шаге две нейросети — «башня» запросов и «башня» документов из базы данных — обучаются на парах запрос-ответ. На втором шаге «башня» документов строит векторы (эмбеддинги) для текстовых документов, в результате эмбеддинги отображаются как точки в векторном пространстве. На третьем шаге во время исполнения запроса строятся эмбеддинги запроса, и ответом становится самый близкий вектор из базы данных. Источник
LLM для поиска интертекстуальных связей в филологии
При этом получить очень интересные результаты в семантическом поиске, на мой взгляд, можно и с минимальными ресурсами. Для этого надо удачно выбрать ответвление этой большой задачи и приложить хоть и не очень большие, но систематические усилия.
Text reuse
Эта большая задача — среди прочего — включает в себя:
- поиск плагиата,
- определение авторства,
- поиск цитат (см. в том числе недавний препринт статьи [2] по «асимметричной интертекстуальности» (asymmetric intertextuality). Этот термин отсылает к неизоморфности связи между текстами, в частности, отсутствию взаимного цитирования. Авторы статьи описывают, как использовать LLM для поиска таких связей),
- и вообще всё, что рамочно называют «повторным использованием текста» (text reuse, см. монографию [3]). Задачи, перечисленные выше, также являются частными случаями text reuse.
Сюда примыкает и многое другое: анализ стиля, вычленение тем, нарративов, определение природы текста (в том числе детекция машинного текста) и т. д.
Я предлагаю внимательно присмотреться к связям именно между литературными текстами. На то, чтобы выделить только художественные, а не все тексты вообще, есть несколько причин. Во-первых, концепция интертекстуальности («Системный Блокъ» затрагивал ее здесь и здесь) — одна из центральных в филологии уже более полувека, поэтому здесь нет недостатка как в интересе профессионалов, так и в научных разработках.
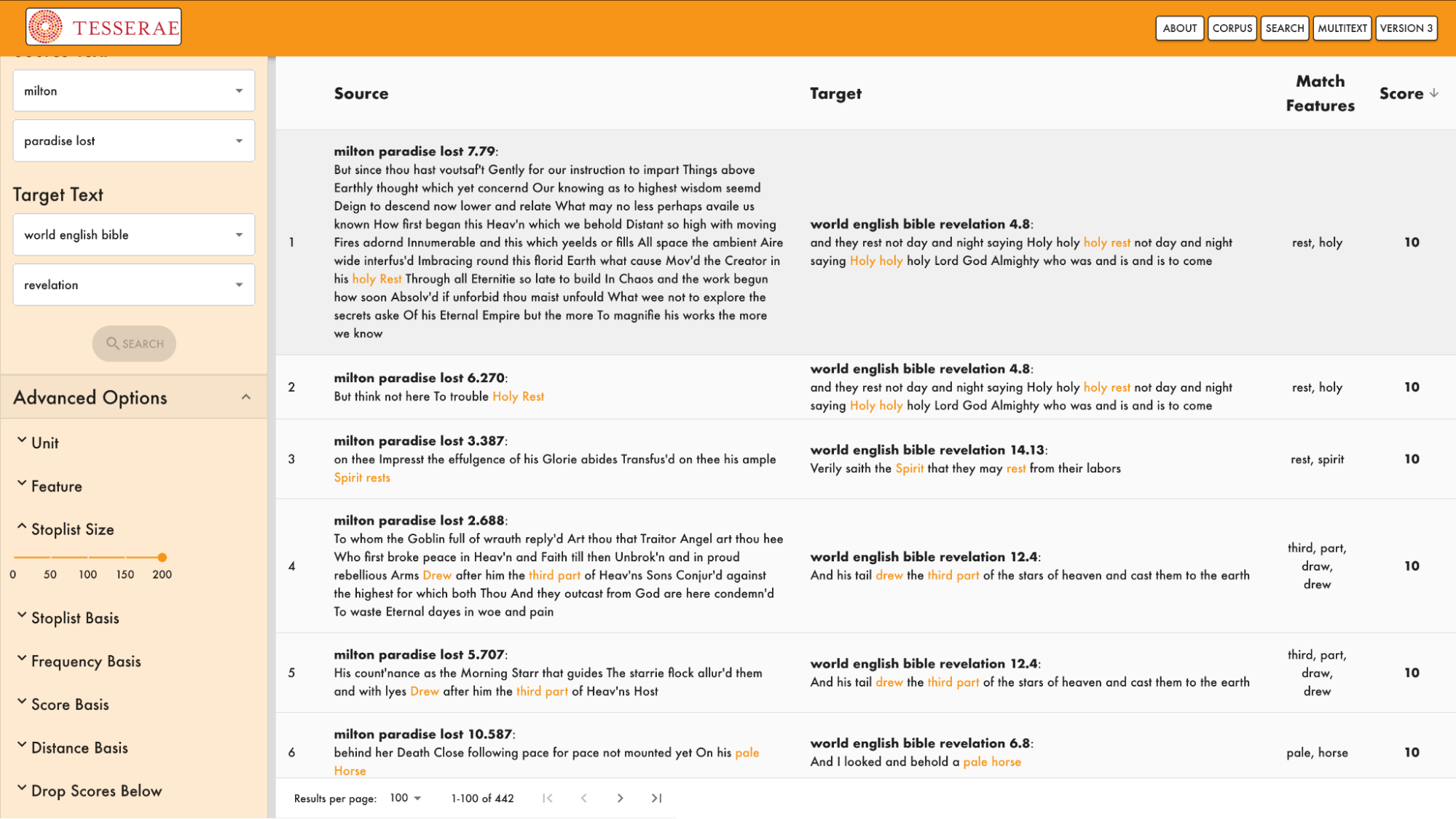
Поиск связей между «Потерянным раем» Мильтона и Библией в проекте Tesserae; это простой поиск по совпадению слов без использования LLM
Во-вторых, чтобы оценивать качество этих связей, одной лишь компетенции в компьютерных науках недостаточно, здесь нужна экспертиза филологов, литературоведов, — поэтому здесь можно в чем-то обойти и технологических гигантов.
В-третьих (и это едва ли не наиболее важное), сейчас закладываются основы будущих фундаментальных направлений. Вероятно, многие решения, которые будут предложены сейчас, их форма, акценты, повлияют на то, как будет выглядеть эта сфера. Поэтому филологам, которые (в основом) не спешат использовать новые технические возможности, есть резон поторопиться.
Какие связи будем искать
Итак, мы приходим к задаче поиска «нетривиальных связей» между художественными текстами с помощью LLM. Первый вопрос, который здесь неизбежно возникает, — что такое нетривиальная связь? Ведь без этого неясно, что мы будем искать.
На мой взгляд, на пути решения этой проблемы не стоит чрезмерно опираться на обширную теорию интертекстуальности (которую разработали целый ряд филологов и теоретиков культуры — от Кристевой, Бахтина и Женетт до Хатчен, Сандерс и Литча; подробнее об их теориях можно прочитать в монографии Грэма Аллена [4], пожалуй, главной книги про интертекстуальность на данный момент).
Почему я считаю, что существующие определения не совсем подходят? Во-первых, они не всегда соответствуют текущим возможностям LLM. Во-вторых, я бы уделил отдельное внимание тому, чтобы находки (то есть связи) были интересны не только профессионалам, но и любителям. Другими словами, более «наивные» ad hoc подходы могут дать более содержательные и интересные результаты.
Несколько месяцев назад в журнале «Новый мир» я продемонстрировал, как сильная (даже по состоянию на май 2025 года) языковая модель находит нетривиальные связи в художественных текстах. Модели удалось найти явные сближения между текстами Улицкой и Тэффи, Захара Прилепина и Анны Старобинец, Алексея Куприна и Дмитрия Глуховского, Валерия Брюсова и Даниила Хармса. Вот пример для последней пары: «Старик, увидав девочку, остановился. Катя решилась спросить его. — Скажите, пожалуйста, как пройти в Вифлеем?» («Дитя и безумец», Брюсов); «Молодой человек почистил перчатками свои брюки и деликатным голосом спросил: — Скажите, дедушка, как тут пройти на небо?» («Молодой человек, удививший сторожа», Хармс). Отловить все подобные сближения без помощи искусственного интеллекта было бы невозможно. Я думаю, мне удалось показать потенциал LLM для этой задачи.
Однако перед масштабированием метода надо проделать предварительную работу.
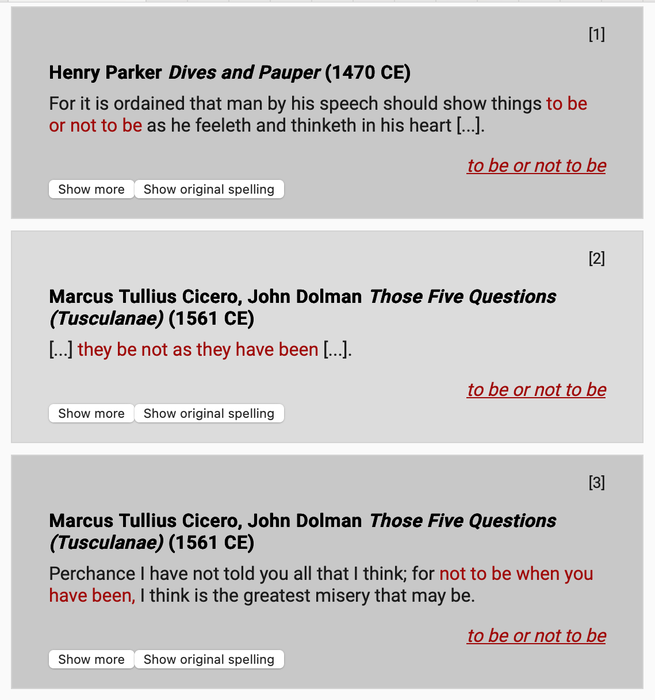
To be or not to be в пьесах до Шекспира. Источник: сайт WordWeb-IDEM
Литературно-вычислительный проект
Я вижу оптимальным следующий план. Собирается группа экспертов, они договариваются, какие связи интересны и при этом могут быть найдены текущими (желательно самыми сильными) моделями. После чего полностью размечается сравнительно небольшой корпус текстов: в них будут указаны все связи, которые удовлетворяют критериям. При этом приветствуется как можно более детальная аннотация: типы связей, их значимость и т. д. (На технических деталях этого процесса, как его лучше организовать, мы сейчас не останавливаемся.)
На основе этих данных подбираются и настраиваются модели — это «конвейер» (pipeline), который будет не только находить нужные нам связи в корпусе с приемлемым уровнем полноты и точности (recall и precision), но и делать это как можно более экономично (в рамках имеющихся у нас ресурсов).
При таком подходе я предлагаю организовать конвейер так, чтобы LLM в своих выводах опиралась только на предоставленные ей материалы, то есть на текст внутри запроса/промта без привлечения «знаний» о других текстах, полученных на этапе обучения. Это связано с тем, что современные модели, даже самые сильные, работают заметно аккуратнее, если материал, который необходим для ответа, содержится непосредственно в промте. О разных стратегиях «промтинга» (prompting) «Системный Блокъ» писал тут. В недавнем исследовании авторы тестировали возможности LLM для анализа художественных текстов [5]. Модель находила разные связи, в том числе и интертекстуальные, но на основе своих «знаний», полученных из обучающих данных (pdf здесь).
Результаты. Граф знаний
Натренированная модель далее будет запущена на новых, интересующих нас корпусах. Можно быть практически уверенным, что она найдет множество интересных, неизвестных, незадокументированных связей. И на их основе можно составить базу данных, граф знаний (knowledge graph). Отмечу, что на сегодняшний день ничего подобного, по крайней мере, на русском языке, нет. На других языках есть похожие проекты (см. ниже), но они существенно отличаются от того, о чем была речь сейчас.
Сегодня, чтобы определить связи одного литературного текста с другими, мы обращаемся к воспоминаниям, специальным статьям и книгам. Иногда что-то можно найти в интернете. Но именно базы данных мы для этого не используем. При этом я уверен, что каждый специалист по тому или иному автору знает множество примеров связей, которые, с одной стороны, представляют большой интерес, а с другой — о них никто не написал или, может, даже и написал, но об этом (почти) никому не известно.
Проекты для поиска интертекстуальности
Tesserae
C 2008 года на базе университета в Баффало осуществляется проект Tesserae, изначально созданный для поиска интертекстуальных связей между классическими древнегреческими, латинскими текстами (статья «Системного Блока» об этом уже упоминалась). У проекта есть действующий онлайн-интерфейс и репозиторий. Однако в Tesserae пока не используют современные возможности LLM. Создатели проекта опираются на проверенные методы обработки естественного языка (NLP).
Intertext.AI
В работе [6] (pdf здесь) авторы презентуют Intertext.AI — интерфейс на основе LLM, который помогает специалистам по античности искать интертекстуальные связи. К нему есть открытый онлайн-доступ, также доступен репозиторий. Еще упомянем проект Йельского университета Intertext, публично обнародованный в 2021 году и официально закрытый в сентябре 2024-го, — он был посвящен поиску повторного использования текстов (text reuse). Хотя LLM там не использовались, но это был довольно заметный проект, в связи с которым в том числе обсуждались разные варианты визуализации и систематизации результатов. Архив репозитория доступен.
InterText
Под тем же названием (InterText) сейчас развивается другой, едва ли не более амбициозный проект: на базе Дармштадтского технического университета разрабатывают теорию и инструменты для работы с разными версиями текстов, комментариями внутри них, ссылками — и многое другое. Этот проект находится в активной фазе, регулярно появляются новые статьи и репозитории — вот один из них. Особое внимание можно обратить на решения разработчиков по структурированию данных и графовой визуализации связей.
Intertextor
Также отметим проект Intertextor в университете Мюнстера (вот его текущий репозиторий). Он ориентирован не на автоматический детектор интертекстуальности, а на ручную разметку. То есть программа не ищет связи, а помогает описывать, структурировать и визуализировать уже имеющиеся у пользователя (возможно, сложные) отношения между текстами. Авторы отдельно говорят о перспективе создания глобального графа знаний (knowledge graph) по интертекстуальности. На данный момент нет ни открытого доступа к коду, ни онлайн-интерфейса, но авторы пишут, что желающие могут принять участие в проекте практически в любом качестве.
InterIDEAS
Чуть ли не самый большой интерес представляет работа, в рамках которой был создан «философский» датасет InterIDEAS на основе большого числа философских текстов (45 тыс. страниц, с 1750 по 1950 гг.), где с помощью LLM и экспертов аннотированы обращения (references) к внешним дискурсам — книгам, идеологиям, религиям, историческим событиям, а также словам и поступкам других людей; с указанием типа обращения, функции (зачем оно сделано) и оценки (тональности) в контексте данного фрагмента. К сожалению, на данный момент этот датасет недоступен: вероятно, авторы перерабатывают свою статью [7] (pdf здесь).
HyperHamlet, WordWeb-IDEM, Intertextual Hub
Говоря о данных с размеченными интертекстуальными связями, уместно вспомнить некогда известный проект Базельского университета HyperHamlet, где были собраны всевозможные цитатные переклички с «Гамлетом» — от Сенеки до Twitter. На данный момент эта база данных, к сожалению, недоступна, однако ее, скорее всего, можно получить у авторов, которые в том же университете делают новый проект — WordWeb-IDEM, где уже аннотированы не только «Гамлет», но и много других английских пьес эпохи Возрождения (хотя представленные связи пока не настолько всеобъемлющие). Также в этом контексте интересен проект Чикагского университета Intertextual Hub, одна из целей которого — навигация по интертекстуальным связям (на данный момент туда загружены французские тексты XVIII века). Статью [8] об этом проекте удобно прочитать здесь, также есть pdf здесь.
Что еще почитать на эту тему?
Отмечу также несколько вышедших недавно статей, наиболее близких к нашей тематике. В работе [8] (pdf здесь) LLM использовали уже в сценариях, которые достаточно похожи на то, что предлагаю я. К сожалению, многие их результаты существенно устарели, т. к. использованные модели уступают лучшим сегодняшним. Впрочем, это проблема практически всех опубликованных статей: даже для подготовки препринта обычно требуется как минимум несколько месяцев; кроме того, часто исследователи предпочитают использовать не самые дорогие модели.
В статье [9] (pdf здесь) среди прочего затрагивается тема использования LLM для поиска связей, мотивов и проч. в литературных текстах. В работе [10] (pdf здесь) тестируются возможности LLM для определения и количественной оценки интертекстуальных связей в библейских текстах (также исследуется, что происходит при переводах на другие языки).
Надеюсь, мне удалось убедить хотя бы часть читателей, что проект по поиску интертекстуальности с помощью LLM — реализованный пусть даже не в полном объеме — будет и важным для науки, и очень впечатляющим.
Источники
- Pokharel S., Roßrucker G. P., Kubek M. M. WebMap — Large Language Model-assisted Semantic Link Induction in the Web. [Электронный ресурс] // Innovations for Community Services (I4CS 2024). Communications in Computer and Information Science, vol. 2109, 2024. Pp. 121–131. URL: https://doi.org/10.1007/978-3-031-60433-1_8 (дата обращения: 25.05.2025).
- Lau P. K., McManus S. M. Mining Asymmetric Intertextuality. 2024. [Электронный ресурс] // arXiv preprint. URL: https://doi.org/10.48550/arXiv.2410.15145 (дата обращения: 25.05.2025).
- Gipp B. Citation-Based Plagiarism Detection: Detecting Disguised and Cross-Language Plagiarism Using Citation Pattern Analysis. Wiesbaden: Springer Vieweg, 2014. 350 pp. [Электронный ресурс] // URL: https://doi.org/10.1007/978-3-658-06394-8 (дата обращения: 25.05.2025).
- Allen G. Intertextuality. 3rd ed. Abingdon; New York: Routledge, 2022. 270 pp. [Электронный ресурс] // URL: https://doi.org/10.4324/9781003223795 (дата обращения: 25.05.2025).
- Yang Z., et al. Analyzing Nobel Prize Literature with Large Language Models. 2024. [Электронный ресурс] // arXiv preprint. URL: https://doi.org/10.48550/arXiv.2410.18142 (дата обращения: 25.05.2025).
- Gong A., Gero K. I., Schiefsky M. Augmented Close Reading for Classical Latin using BERT for Intertextual Exploration. [Электронный ресурс] // Proceedings of the 5th International Conference on Natural Language Processing for Digital Humanities (NLP4DH 2025). Albuquerque (USA): Association for Computational Linguistics, 2025. Pp. 403–417. URL: https://aclanthology.org/2025.nlp4dh-1.35 (дата обращения: 25.05.2025).
- Yang Y., Xu Y., Huang C., Jurgensen J. M., Hu H. InterIDEAS: An LLM and Expert-Enhanced Dataset for Philosophical Intertextuality. 2024. [Электронный ресурс] // OpenReview preprint (withdrawn conference submission). URL: https://openreview.net/forum?id=cA8iQJFioL (дата обращения: 25.05.2025).
- Umphrey R., Roberts J., Roberts L. Investigating Expert-in-the-Loop LLM Discourse Patterns for Ancient Intertextual Analysis. [Электронный ресурс] // Proceedings of the 4th International Conference on Natural Language Processing for Digital Humanities (NLP4DH 2024). Miami (USA): Association for Computational Linguistics, 2024. Pp. 31–40. URL: https://doi.org/10.18653/v1/2024.nlp4dh-1.4 (дата обращения: 25.05.2025).
- Papa E. (Re)Thinking Literary Interpretation in the Digital Age: AI, Virtual Reality, and Immersive Reading. [Электронный ресурс] // Open Journal of Social Sciences. 2025. Vol. 13, No. 4. Pp. 46–67. URL: https://doi.org/10.4236/jss.2025.134003 (дата обращения: 25.05.2025).
- McGovern H., Sirin H., Lippincott T. Characterizing the Effects of Translation on Intertextuality Using Multilingual Embedding Spaces. [Электронный ресурс] // Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2: Short Papers). Albuquerque (USA): Association for Computational Linguistics, 2025. Pp. 161–167. URL: https://aclanthology.org/2025.naacl-short.14/ (дата обращения: 25.05.2025).

