
Каждое слово имеет, помимо своей фонетической и графической формы (звучания и написания) определенное значение. Это значение не обладает какой-то прямой связью с тем, как слово выглядит. Возьмем, к примеру, предложения «лук — основной ингредиент в знаменитом французском супе» и «луг пышно цветет летом». Несмотря на похожее звучание и написание, слова «лук» и «луг» здесь определенно имеют разное значение. А вот слово «шалот», как бы оно ни отличалось от слова «лук» по написанию, имеет с луком куда большее семантическое сходство, чем слово «луг».
Всё это понятно человеку, но как «объяснить» компьютеру семантику слова? Существует ли способ представлять смыслы слов в виде, который был бы понятен компьютеру? Оказывается, да — смысл слова можно представить в виде вектора.
Что такое вектор?
Разные дисциплины, которые используют это понятие (математика, физика, компьютерные науки) дают несколько разные (но все равно связанные) определения этому термину. Упрощенно можно сказать, что векторы представляют собой упорядоченные последовательности чисел. Векторы можно складывать и вычитать, умножать на число. Совокупность таких векторов образует векторное пространство. Это означает, что каждый вектор можно представить как точку в таком пространстве, координатами которой являются значения компонент вектора. Точки могут находится ближе или дальше друг от друга, т.е. между векторами можно измерить расстояние. Например, пары координат на координатной плоскости x, y являются векторами. Такие векторы называются двумерными, т.к. их можно представить в двумерном пространстве.
Также векторами являются упорядоченные последовательности чисел, такие как: [1,4, 6], [6,7,9]. Количество чисел соответствует количеству измерений вектора. Иными словами, каждое число является координатой вектора на определенной оси. При этом следует понимать, что измерений у вектора может быть сколько угодно.
Как получают векторные представления слов?
Теперь объясним, как векторы могут «хранить» внутри себя смысл слов.
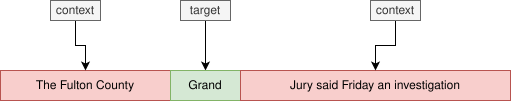
Лингвист Джон Ферс предположил, что значение слова определяется его контекстом, то есть словами, рядом с которыми оно появляется. Согласно ему: «Вы узнаете слово по окружающим его словам». Эта идея, которую в лингвистике называют дистрибутивной гипотезой — именно она служит теоретическим основанием для векторных представлений слов. Контекстом слова называют слова, находящиеся слева и справа от него — их часто называют контекстным окном. Обычно используется окно размером 4 — это означает, что берутся четыре слова слева от целевого слова (target) и четыре слова справа.
На основании совместной встречаемости слов и создаются векторные представления. Самым простым видом векторного представления слова является количество раз, которое слово встретились рядом с другим. Эти частотности удобно хранить в матрице слово-слово. Или другими словами — в виде размера N * N, где N — количество слов в корпусе (наборе текстов). Каждая ячейка содержит количество появлений одного слово в контексте другого. Возьмем для примера известную скороговорку: «Ехал грека через реку, видит грека — в реке рак. Сунул грека руку в реку, рак за руку греку — цап!».
| в | видеть | грек | ехать | за | рак | река | рука | сунуть | цап | через | |
| в | 0 | 1 | 2 | 0 | 1 | 2 | 3 | 2 | 1 | 0 | 1 |
| видеть | 1 | 0 | 2 | 1 | 0 | 1 | 2 | 0 | 0 | 0 | 1 |
| грек | 2 | 2 | 1 | 1 | 1 | 3 | 5 | 2 | 1 | 1 | 2 |
| ехать | 0 | 1 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 |
| за | 1 | 0 | 1 | 0 | 0 | 1 | 1 | 2 | 0 | 1 | 0 |
| рак | 2 | 1 | 3 | 0 | 1 | 0 | 2 | 2 | 0 | 1 | 0 |
| река | 3 | 2 | 5 | 1 | 1 | 2 | 1 | 2 | 1 | 0 | 1 |
| рука | 2 | 0 | 2 | 0 | 2 | 2 | 2 | 0 | 1 | 1 | 0 |
| сунуть | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 |
| цап | 0 | 0 | 1 | 0 | 1 | 1 | 0 | 1 | 0 | 0 | 0 |
| через | 1 | 1 | 2 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
Как же матрица совместной встречаемости слов связана с векторами? Вытащим из нашей столбец слова «рак».
| рак | 2 | 1 | 3 | 0 | 1 | 0 | 2 | 2 | 0 | 1 | 0 |
Эта последовательность чисел является векторным представлением слова рак.
Вместо простых частотностей слов можно использовать точечную взаимную информацию (Pointwise Mutual Information). Тем не менее, на практике такие вектора используются редко, поскольку являются разреженными (sparse), т.е. имеют большое количество нулевых значений. Кроме того, эти вектора имеют большую размерность, поскольку количество измерений равно количеству уникальных слов в корпусе, от чего их хранение требует большого объёма памяти.
Векторные представления и эмбеддинги
Часто в качестве синонима векторного представления используется слово «эмбеддинг» (на английском «embedding»). Эмбеддинги, которые используются в современных NLP задачах, это плотные вектора (то есть вектор с небольшим количеством нулевых значений) произвольной размерности. Их получают, используя алгоритмы машинного обучения. Одним из первых и известных алгоритмов для получения эмбеддингом является word2vec (word to vector).
Где используются векторные представления?
Векторные представления слов используются в огромном количестве задач, где требуются использование семантики слов. Например, человек, ищущий в поисковике интернет-магазина отсутствующий там шалот, скорее всего будет заинтересован в других видах лука. Это значит, что поисковик должен понимать, что слово лук находится близко к слову шалот. Эту задачу позволяют решать векторные представления. Эмбеддингами являются и выходы нейросетей, которые используются, например, для генерации текста.



