
Что такое автоматическая оценка сложности текста и зачем она нужна?
Автоматическая оценка сложности текста — это метод, который позволяет определить, как материал воспринимают читатели с разными уровнями подготовки. Редакторам, переводчикам и маркетологам — словом, всем, кто работает с текстами, — это помогает адаптировать подачу информации для целевой аудитории, а преподавателям и методистам — составлять учебные материалы.
Представьте, что вы составляете школьный учебник. Нужно определить, поймет ли ученик ваш текст. Подготовленные материалы должны соответствовать определенным критериям: слишком сложные снизят мотивацию, а слишком простые покажутся скучными. Однако составитель учебника, преподаватель, методист не всегда может объективно оценить сложность учебного текста. В этом вопросе лучше положиться на теоретические разработки. В материале мы расскажем вам о том, какие решения предлагали разные исследователи: будем опираться главным образом на диссертацию и работы А. Лапошиной, а также рассмотрим разные метрики и сервисы.
Что такое сложность и трудность текста
Слова «сложность» и «трудность» на первый взгляд кажутся синонимами. Однако лингвисты разграничивают эти два понятия при анализе текста [1]. Сложность — это свойство самого текста, а трудность учитывает еще и внешние факторы, например, навыки читателя.
Для вычисления сложности текста нужно оценить:
- особенности лексики: средняя длина слова, наличие слов различного уровня,
- грамматические признаки: наличие слов в определенных формах (например, глаголы 1-го лица),
- синтаксические признаки: средняя длина предложений в тексте, количество союзов и их разнообразие,
- дискурсивные признаки: лексические повторы, разные типы связок (причинные, временные и другие),
- нарративность и описательность текста: количество глаголов и прилагательных.
Формулы
Чтобы перейти от теории к практике, нужно создать универсальную формулу и шкалу интерпретации, которая бы комплексно учитывала признаки текста. Сейчас таких формул для разных языков насчитывается около 200. Первые формулы разрабатывались для далеких от образования целей: индекс Флеша-Кинкейда был создан для нужд военных, а формула МакЛафлина — для оценки инструкций к лекарствам.
Индекс Флеша-Кинкейда является наиболее популярным способом оценки сложности и удобочитаемости текста. Первый вариант формулы разработал Рудольф Флеш для английского языка в 1943 году. Выглядит она так:
Удобочитаемость по Флешу (сокр. УФ) = 206.835 — (1.015 * средняя длина предложения) — (84.6 * среднее число слогов)
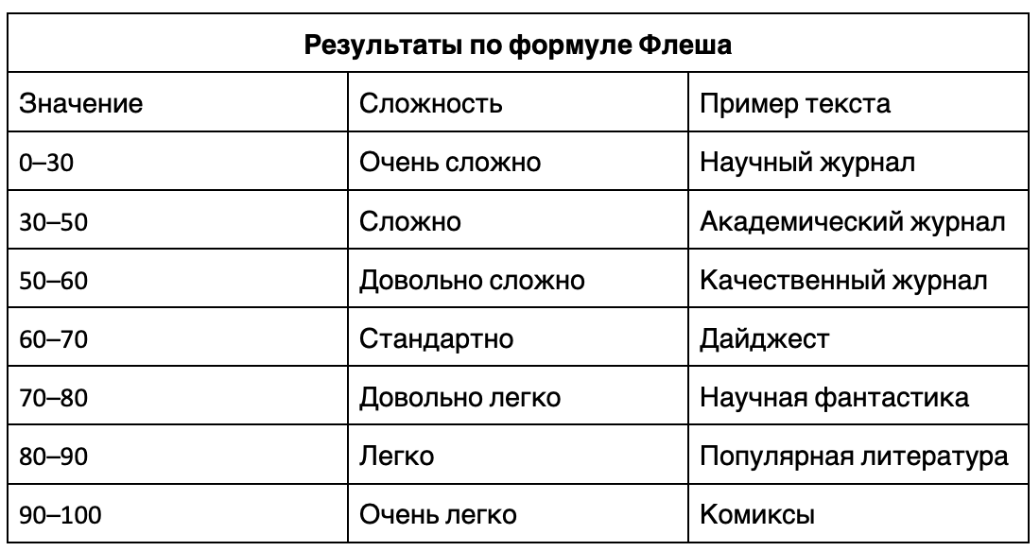
Интерпретировать результат можно по таблице:

Рис. 1. Таблица для интерпретации результатов по формуле Флеша
В переводе таблица выглядит так:
В 1975 году формула Флеша была доработана и стала называться индексом удобочитаемости Флеша-Кинкейда. Его использовали, чтобы упростить инструкции для военных американского флота. Формула выглядит так:
FKG = 0.39×ASL + 11.8×ASW − 15.59,
где:
- FKG (Flesch-Kincaid Grade Level) — сколько лет необходимо учиться, чтобы понять текст,
- ASL (Average Sentence Length) — среднее количество слов в предложении,
- ASW (Average Syllables per Word) — среднее количество слогов в слове.
Тексты, для которых значение индекса находится в диапазоне от 1 до 10, подходят по уровню ученикам средней школы, от 11 до 15 — студентам высших учебных заведений. Для сложных научных текстов индекс принимает значения от 16 до 20 [2].
Вот пример текста, который читали американские моряки в рамках эксперимента:
Passage 1
RGL (Readability Grade Level / Уровень образования, необходимый для чтения текста) = 6.9
TEMPORARY REPAIRS
Temporary repairs are usually made by securing some type of patch over the damaged section of pipe. The material used for the patch depends upon the type of piping that is being repaired. A good general rule to go by is to make the temporary patch from the same type of material that is used for the flange gaskets in the system. Back up the patch with a piece of sheet metal, and secure the sheet metal to the pipe with bolted metal clamps or similar devices. A sealing compound may be applied between the patch and the pipe to help seal the patched area. For low pressure salt water piping, a satisfactory patch can be made from red lead putty wrapped with canvas and served with marlin or friction tape. Small holes in some piping may be temporarily repaired by drilling and threading and inserting a screw.
Этот текст будет понятен носителям английского, которые окончили семь классов школы.
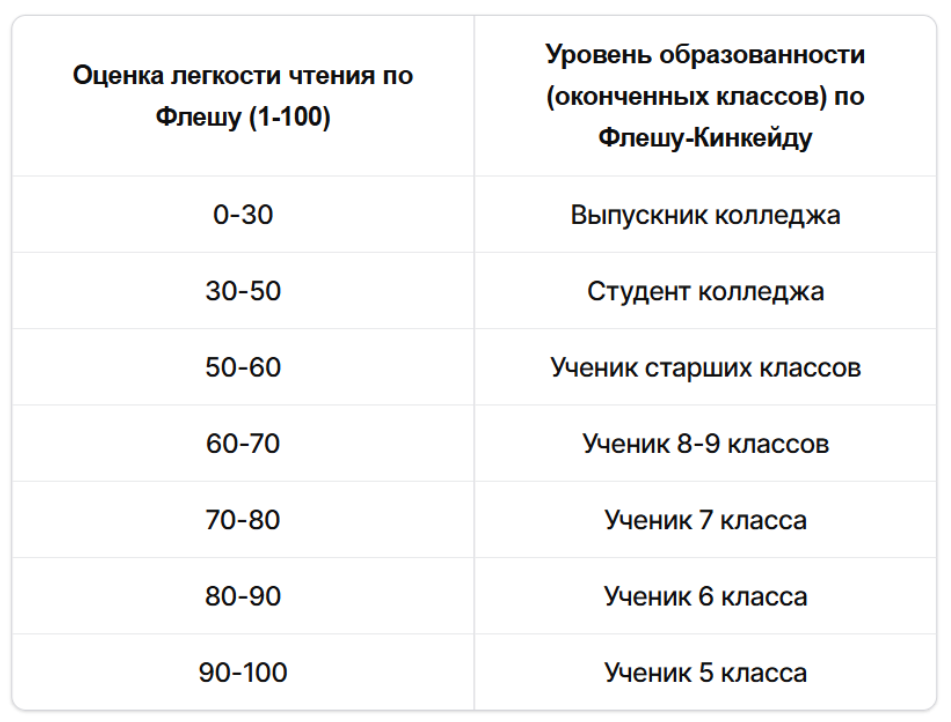
Рис. 2. Сопоставление результатов по формулам Флеша и Флеша-Кинкейда (русская адаптация)
Формула Флеша впоследствии была адаптирована под особенности разных языков. Например, исследовательница И. В. Оборнева в своей диссертации 2006 года сравнила характеристики русского и английского языков на выборке, состоявшей из 100 текстов [3]. Она изменила коэффициенты так, чтобы они соответствовали среднестатистическому тексту на русском языке. Ее вариант формулы применяется в макросе Microsoft Word для определения читабельности текста. Вот так выглядит ее вариант для русского языка:
K = 206.836 — 60.1 × W — 1.3 × S,
где:
- K — оценка трудности от 1 до 100,
- W — среднее число слогов в слове,
- S — среднее число слов в предложении.
В. Иванов, М. Солнышкина и В. Соловьёв, исследователи из Казанского федерального университета, позже проанализировали и еще раз скорректировали формулу И. В. Оборневой [4]. Они отметили, что формула иногда приписывает тексту бо́льшую сложность, чем есть на самом деле. Их вариант формулы выглядит так:
FKG = 0.36 × ASL + 5.76 × ASW − 11.97,
где
- FKG (Flesch-Kincaid Grade Level) — сколько лет необходимо учиться, чтобы понять текст,
- ASL (Average Sentence Length) — среднее количество слов в предложении,
- ASW (Average Syllables per Word) — среднее количество слогов в слове.
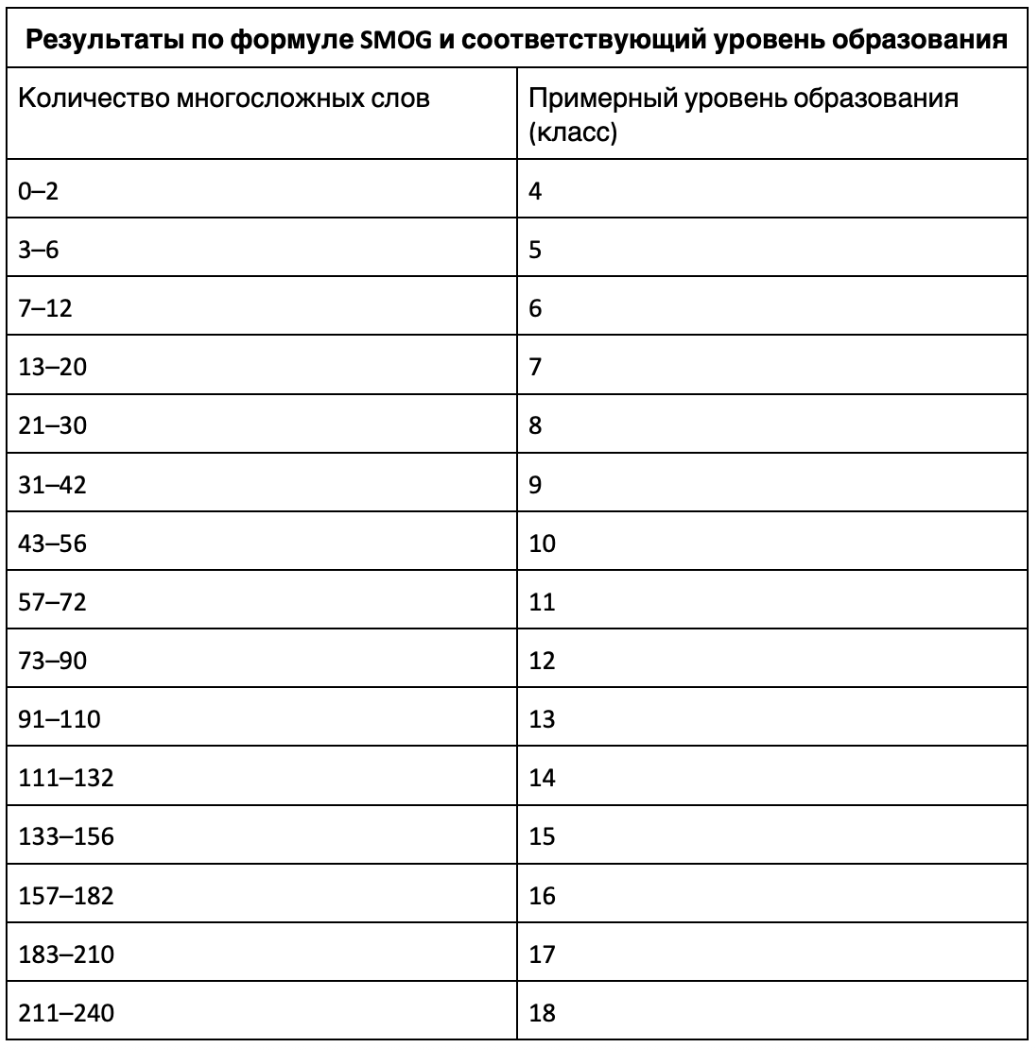
Еще одна формула под названием SMOG (Simplified Measure of Gobbledygook, на русский это можно перевести как «Упрощенная мера белиберды») была разработана Гарри МакЛафлином в 1969 году для оценки сложности научных текстов и инструкций к лекарствам. Формула выглядит так:
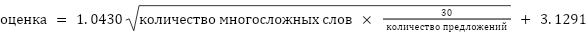
Она учитывает количество сложных слов (больше трех слогов) и количество предложений. Для интерпретации можно воспользоваться этой шкалой:
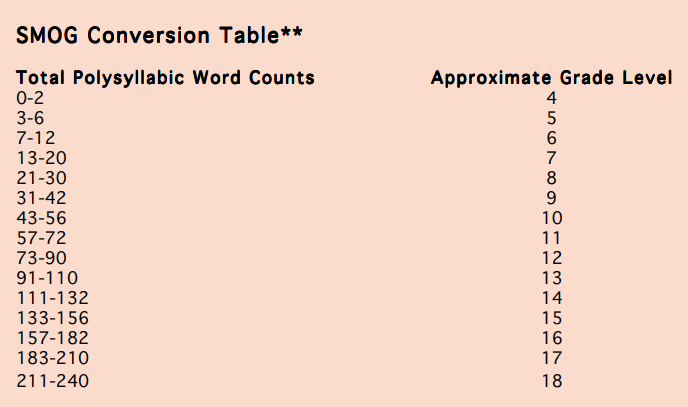
Рис. 3. Шкала результатов по формуле SMOG
В переводе таблица выглядит так:
Были попытки создать формулы для узких целей на русском языке. Например, Ю. Ф. Шпаковский вывел формулу для школьных учебников по химии:
Y = 20,24 + 0,48X1 + 0,58X2 + 0,41X3,
где:
- Y — сложность текста,
- X1 — процент слов длиной в 9 букв и больше,
- X2 — процент терминов,
- X3 — процент условных обозначений в химических реакциях,
«Текстометр»
Как мы уже выяснили, формулы действительно делают оценку сложности текста более объективной. Однако для того чтобы делать такие расчеты вручную, необходимо сначала подсчитать длину предложений, количество слогов или трехсложных слов. Чтобы не тратить много времени, эту задачу можно поручить компьютеру. Уже разработаны специальные сервисы, которые за считанные секунды выводят статистику и оценивают сложность или удобочитаемость текста по запросу пользователя. Они просты в использовании, так что любой учитель или методист сможет легко с ними работать. Разберемся, как работают такие инструменты, на примере сервиса «Текстометр».
Сервис работает в двух режимах: русский язык для носителей и для иностранных обучающихся. Пользователь может ввести прозаический текст длиной до 10 000 знаков или загрузить фото — тогда текст будет распознан автоматически.
Рис. 3. Интерфейс сервиса
Для обучения модели, на основе которой работает сервис, был взят специально размеченный корпус — 800 текстов из пособий по русскому языку как иностранному (РКИ). После нажатия кнопки «Анализировать» модель очищает текст от лишних знаков и лемматизирует его, а затем проверяет лексику по спискам частотности. В результате пользователь получает уровень введенного текста по общепринятой шкале CEFR (Common European Framework of Reference for Languages — Общепринятая европейская система оценки языковых навыков). При этом для каждого уровня выделены подгруппы: начальная, если ученик недавно получил соответствующий уровень, средняя, если владение языком на этом уровне уже уверенное, и продвинутая, если ученик близок к переходу на следующий уровень. Так преподаватели могут максимально точно подобрать материал под конкретную группу.
Русский для детей и подростков
Мы взяли первую страницу учебника по физике для 7-го класса и измерили сложность текста вводного параграфа, который знакомит школьников с наукой.

Рис. 4. Текст, который мы выбрали для анализа [5]
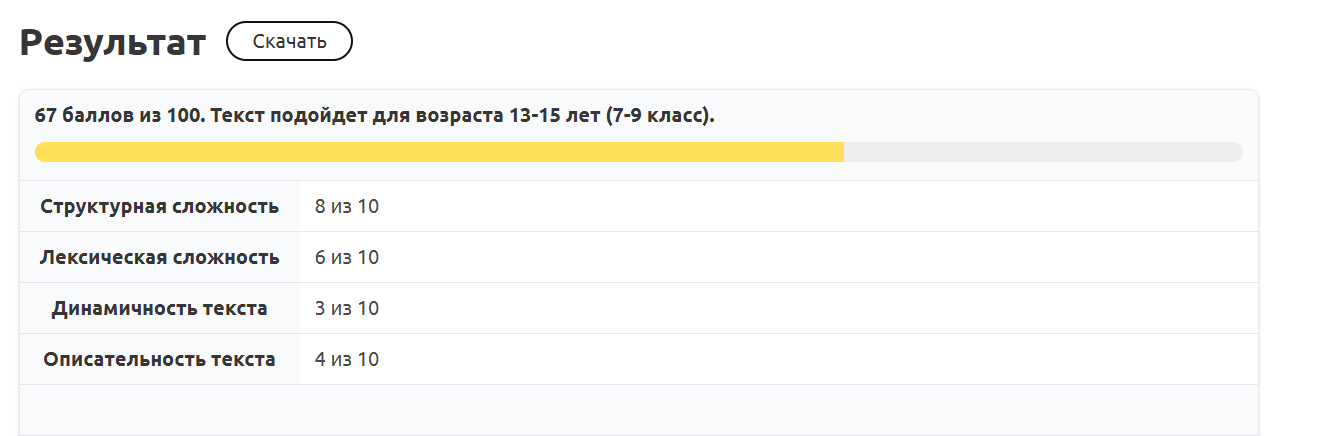
Рис. 5. Результат анализа текста из учебника по физике за 7-й класс
Как мы видим, вердикт сервиса — учебник соответствует уровню 7-го класса. Кроме определения уровня, программа также выводит дополнительную информацию о тексте. Главные критерии сложности текста — уровень синтаксиса и лексики, а также динамичность и описательность. Два последних параметра для нашего примера из школьного учебника имеют достаточно низкие значения. Динамика в тексте появляется за счет глаголов, обозначающих физические действия. Подобная лексика, с одной стороны, упрощает восприятие текста, так как образует сюжетную канву. С другой стороны, в научном стиле речи преобладает рассуждение, а не повествование. Описательность текста оказалась низкой из-за малого количества прилагательных. Наш учебник нужен для разъяснения физических терминов и явлений, так что описательностью и динамичностью приходится жертвовать ради точности и ясности изложения.
«Текстометр» также показывает:
- статистику по тексту,
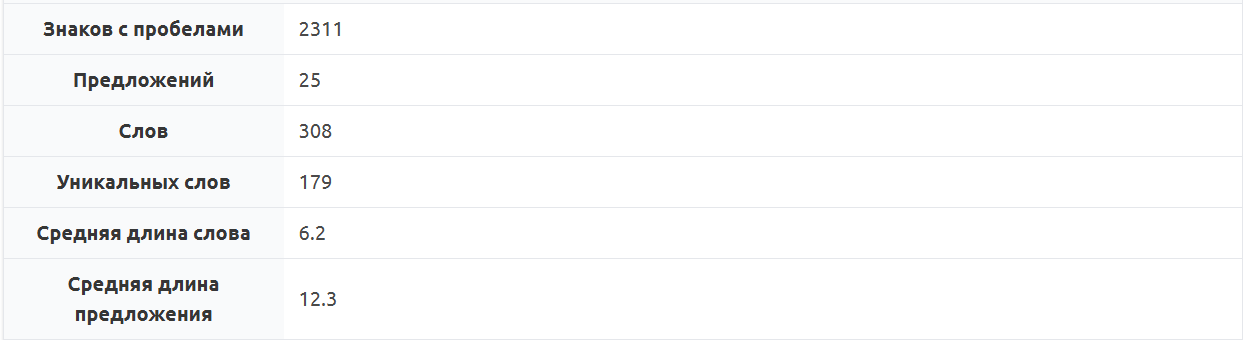
Рис. 6. Статистика в сервисе «Текстометр»
- расчеты по формулам Флеша и Флеша-Кинкейда с пояснениями. Однако нужно учитывать, что эти формулы изначально разрабатывались для англоязычного текста и американской системы образования,

Рис. 7. Оценка текста по формулам Флеша и Флеша-Кинкейда
- лексические особенности текста: разнообразие лексики, наличие редких слов; сервис также показывает, какой процент текста составляет лексика, доступная для детей (определяется по специальному списку) — это позволит учителю обратить внимание на слишком сложные слова, отрегулировать их количество, а значит и сложность текста,
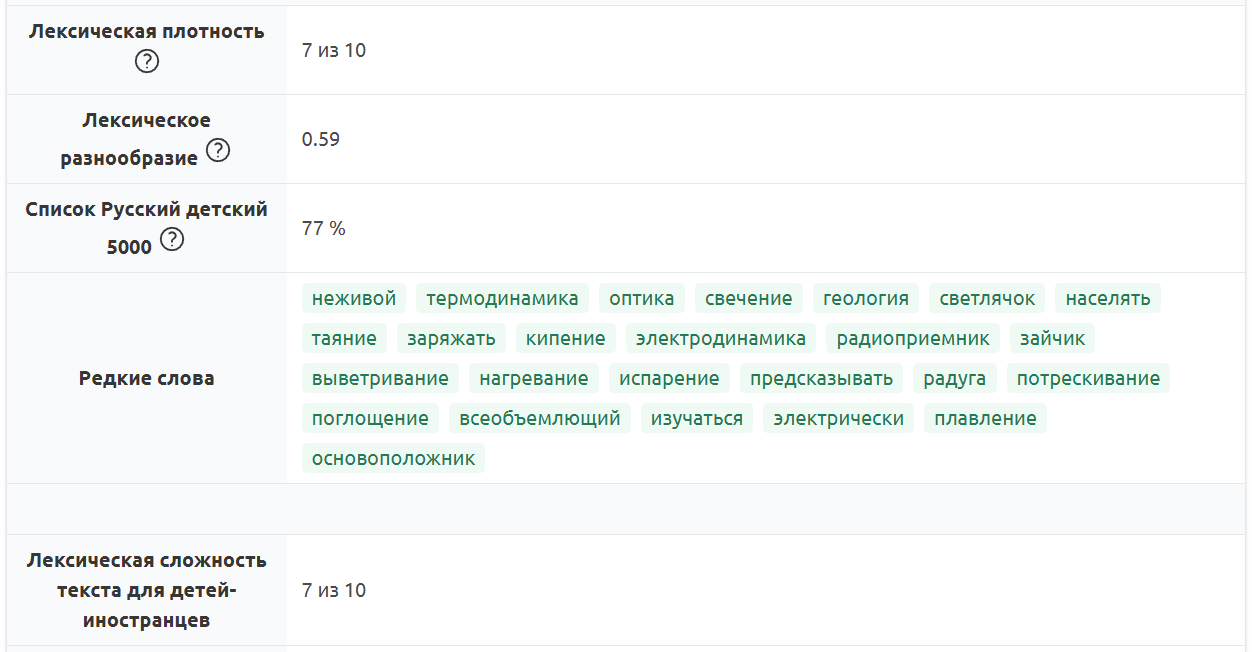
Рис. 8. Анализ лексических особенностей текста в сервисе «Текстометр»
- частотный словарь — он позволит учителю понять, насколько часто встречаются термины или иные группы слов.

Рис. 9. Частотный словарь
Русский как иностранный
Теперь представим, что мы преподаем русский язык иностранцам и не знаем, какие тексты подойдут для занятий. Детские сказки с простой лексикой уже прочитаны, а романы Достоевского все еще кажутся слишком сложными и непонятными. «Текстометр» снова приходит на помощь: протестируем режим «русский как иностранный».
На этот раз мы взяли рассказ А. П. Чехова «Открытие» в оригинале и в адаптированной версии из учебника русского как иностранного. Данный учебник предназначен для уровня B1 по шкале CEFR (Common European Framework of Reference for Languages — Общепринятая европейская система оценки языковых навыков) — адаптированный текст соответствует этому уровню.
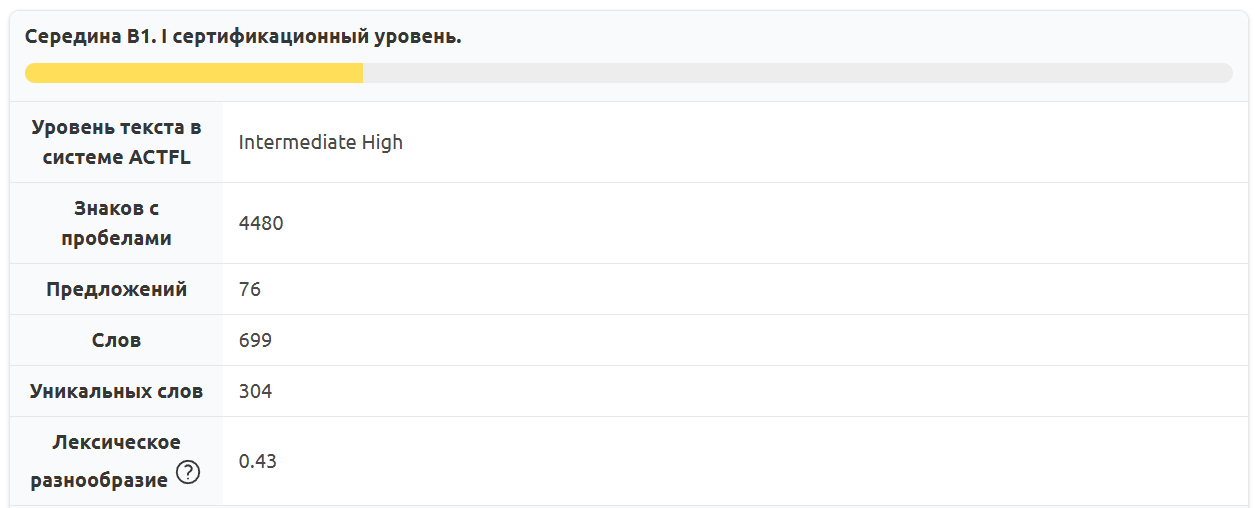
Рис. 10. Результат анализа адаптированного текста из учебника РКИ
Как и в режиме «русский для детей и подростков», здесь мы получили статистику по тексту. Отличие — группировка лексики по уровням языка, а также выявление ключевых и полезных слов. Полезные слова — это еще не знакомые студенту слова, которые, однако, часто встречаются в НКРЯ или лексических минимумах.

Рис. 11. Ключевые и полезные слова из адаптированного текста
Методистам и учителям может также пригодиться информация о том, сколько времени уйдет у учеников на чтение текста и какие грамматические темы стоит обсудить на занятии (об этой функции мы подробно расскажем чуть ниже):
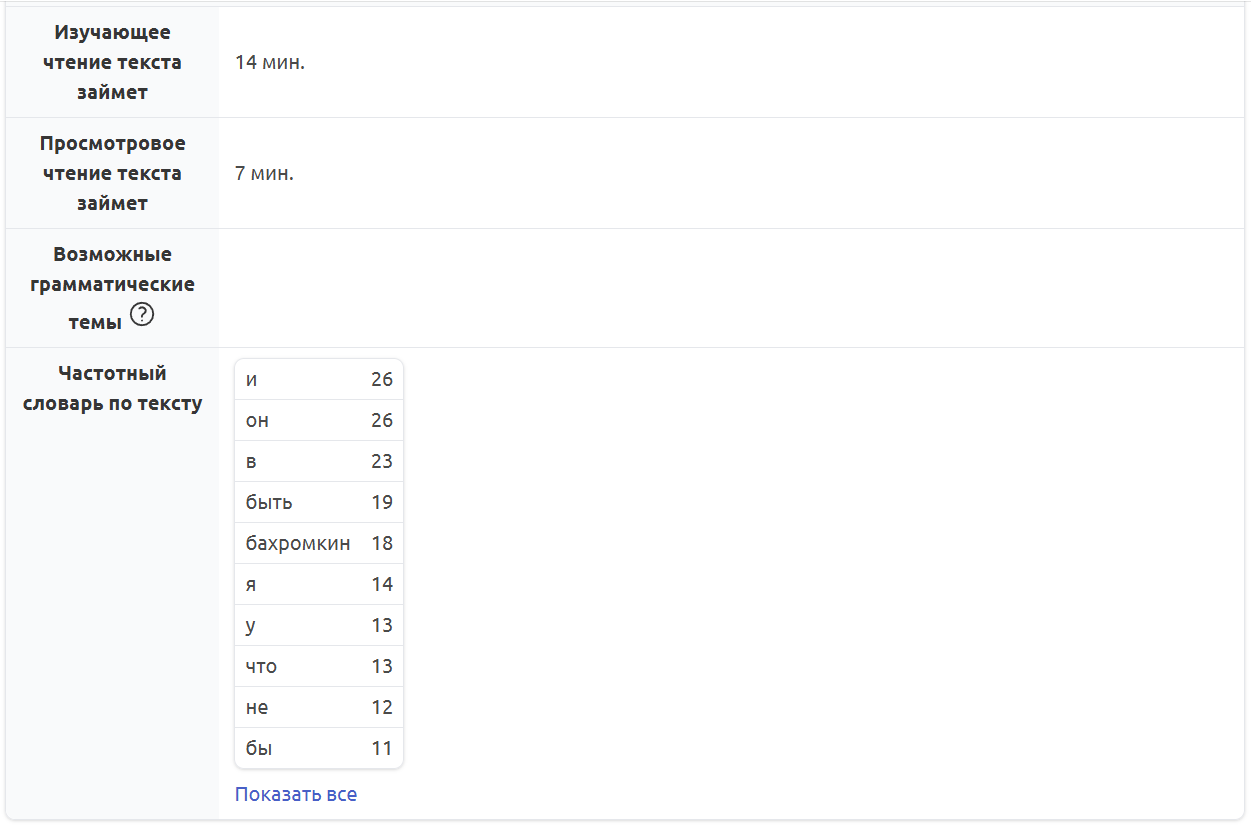
Рис. 12. Время чтения адаптированного текста и частотный словарь к нему
Теперь сравним, насколько сильно был упрощен оригинальный текст. Согласно расчетам «Текстометра», уровень оригинального текста — B2, то есть выше, чем уровень выбранного нами учебника.
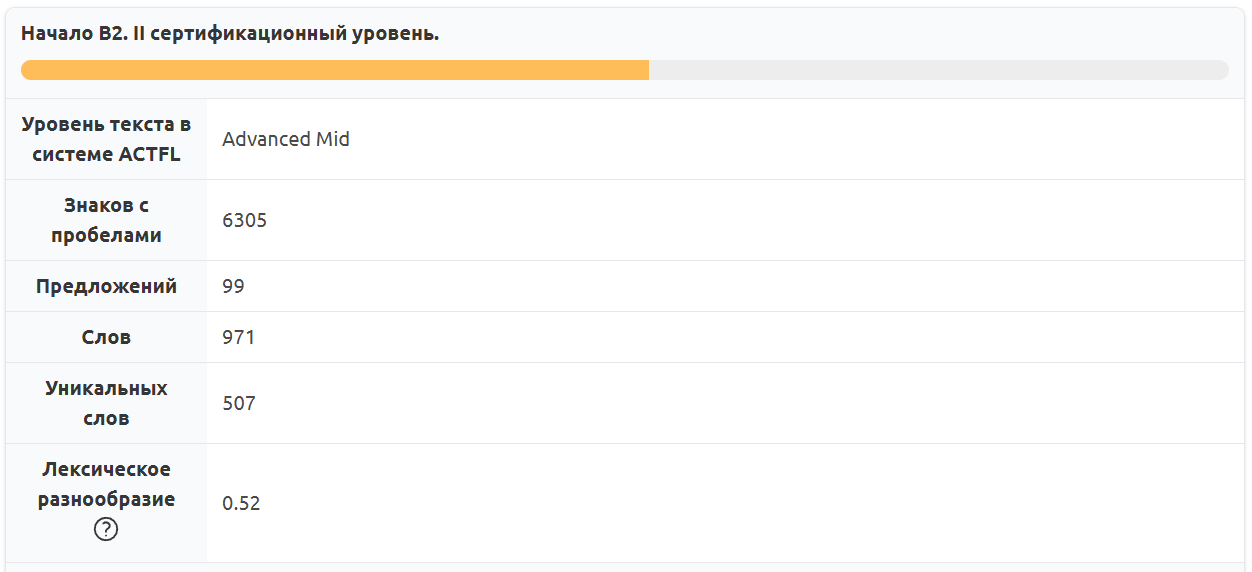
Рис. 13. Результаты анализа оригинального текста «Открытия» Чехова
Если сравнить два текста, мы увидим, что составители учебника убрали разговорные конструкции, заменили редкие слова синонимами, упростили синтаксис и сделали язык менее образным.
| Оригинальный текст | Адаптированный текст |
| Инженер статский советник Бахромкин сидел у себя за письменным столом и, от нечего делать, настраивал себя на грустный лад. Не далее как сегодня вечером, на бале у знакомых, он нечаянно встретился с барыней, в которую лет 20—25 тому назад был влюблен. В свое время это была замечательная красавица, в которую так же легко было влюбиться, как наступить соседу на мозоль. Особенно памятны Бахромкину ее большие глубокие глаза, дно которых, казалось, было выстлано нежным голубым бархатом, и длинные золотисто-каштановые волосы, похожие на поле поспевшей ржи, когда оно волнуется в бурю перед грозой… Красавица была неприступна, глядела сурово, редко улыбалась, но зато, раз улыбнувшись, «пламя гаснущих свечей она улыбкой оживляла»… Теперь же это была худосочная, болтливая старушенция с кислыми глазами и желтыми зубами… Фи! | Инженер Бахромкин, важный господин, сидел у себя дома за письменным столом и от нечего делать думал о грустном. Сегодня вечером на балу у знакомых он случайно встретился с дамой, в которую лет 20-25 тому назад был влюблён. Раньше это была замечательная красавица, в которую легко было влюбиться. Особенно хорошо Бахромкин помнил её большие глубокие голубые глаза и длинные золотые волосы. Красавица была гордой и неприступной, смотрела строго и редко улыбалась. Но когда она улыбалась, все мужчины обращали на неё внимание. Теперь же это была худая болтливая пожилая женщина с кислыми глазами и желтыми зубами… |
Этот текст Чехова скорее пригодится для тренировки навыков чтения — после него в учебнике есть вопросы на понимание содержания. Поэтому «Текстометр» не выделил конкретные грамматические темы, которые можно было бы разобрать на этом примере.
Попробуем заглянуть в материалы, приложенные к разделу с грамматикой. Мы проанализировали с помощью «Текстометра» адаптированный вариант другого рассказа Чехова — «С женой поссорился». Текст находится во второй части этого же учебника и тоже соответствует продвинутому уровню владения русским языком.
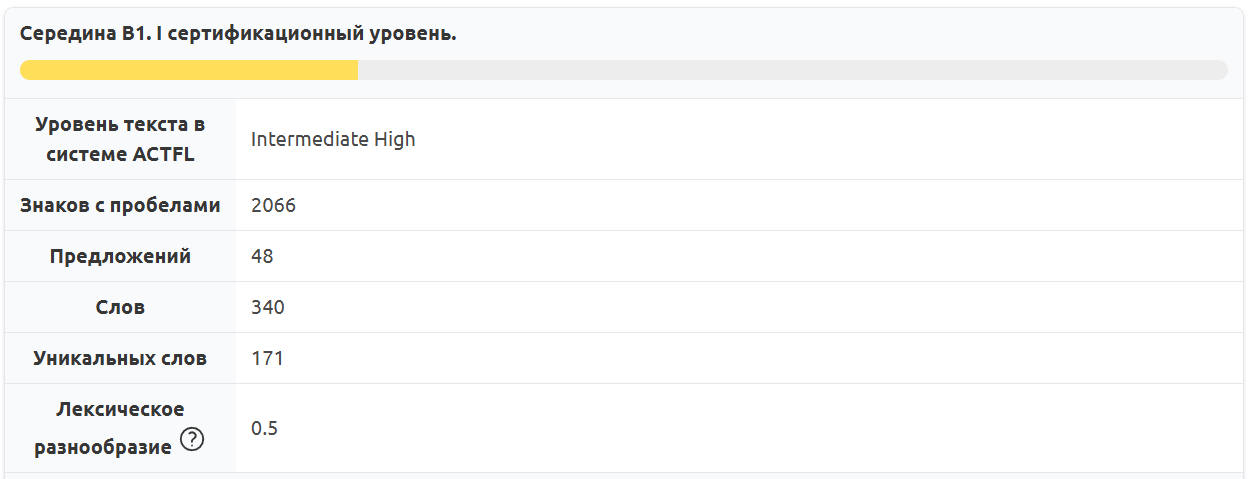
Рис. 14. Результат анализа адаптированного текста «С женой поссорился» из учебника РКИ
Этот текст — иллюстрация для грамматической темы «Деепричастия». Учащимся необходимо прочитать его и найти 10 деепричастных оборотов. «Текстометр» также предлагает изучить эту грамматическую тему на примере текста.
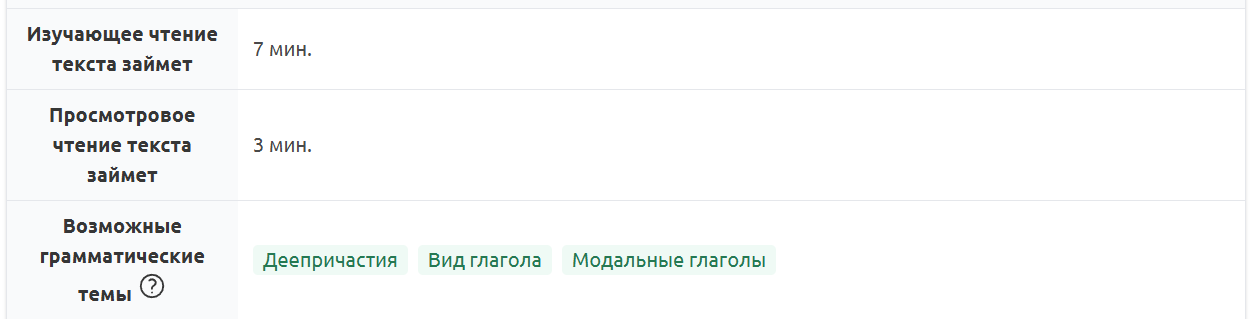
Рис. 15. Грамматические темы, предложенные «Текстометром»
Как и в случае с «Открытием», авторы учебника адаптировали этот рассказ. Сюжетная канва осталась неизменной, но составители заметно увеличили объем текста, упростив при этом лексику и добавив деепричастные обороты.
| Оригинальный текст | Адаптированный текст |
| — Чёрт вас возьми! Придешь со службы домой голодный, как собака, а они чёрт знает чем кормят! Да и заметить еще нельзя! Заметишь, так сейчас рев, слезы! Будь я трижды анафема за то, что женился! Сказавши это, муж звякнул по тарелке ложкой, вскочил и с остервенением хлопнул дверью. Жена зарыдала, прижала к лицу салфетку и тоже вышла. Обед кончился. | Закончив работу, усталый и голодный муж пришёл домой позднее обычного. Дома его ждали жена и обед. Обед был на столе. Сели за стол. Попробовав первое блюдо, муж сразу заметил, что суп был вовсе не горячий и даже не тёплый, а можно сказать, холодный. Настроение у него испортилось. — Что это такое! Я пришёл домой усталый, голодный, как собака; мне хочется отдохнуть, пообедать. А чем меня кормят дома? Холодным супом? Могу я в собственном доме пообедать нормально? Зачем я только женился?! Услышав эти слова, жена заплакала и вышла из столовой. — Ну вот, опять слёзы! Я даже сказать ничего не могу в собственном доме! Зачем я только женился?! Каждый день слёзы! — сказав это, муж вскочил и вышел, хлопнув дверью. Обед кончился. |
На примере «Текстометра» можно увидеть, из чего конкретно складывается сложность текста. Например, учителя могут обращать внимание на редкие слова в тексте и делать на них акцент на уроке. Незаменим этот сервис и для преподавателей русского как иностранного, ведь носитель языка не всегда сможет корректно определить уровень текста. Также Текстометр может быть полезен и для тех, кто готовит материалы для широкой аудитории и хочет, чтобы его понял каждый читатель или слушатель.
RuLingva
Частичными аналогами «Текстометра» можно назвать инструменты на платформе RuLingva. Эта разработка принадлежит исследователям из Института филологии и межкультурных коммуникаций Казанского федерального университета. На платформе есть специальные тесты на выявление уровня функциональной грамотности или вербального интеллекта. Кроме того, RuLingva предлагает два инструмента для оценки сложности текста: обычный и разработанный специально для начальной школы.
Один из алгоритмов позволяет оценить сложность текста для изучающих русский язык. Проверим уже знакомый нам адаптированный отрывок из рассказа А. П. Чехова.
Рис. 16. Интерфейс сайта RuLingva — пользователь может вставить свой текст или сгенерировать пример
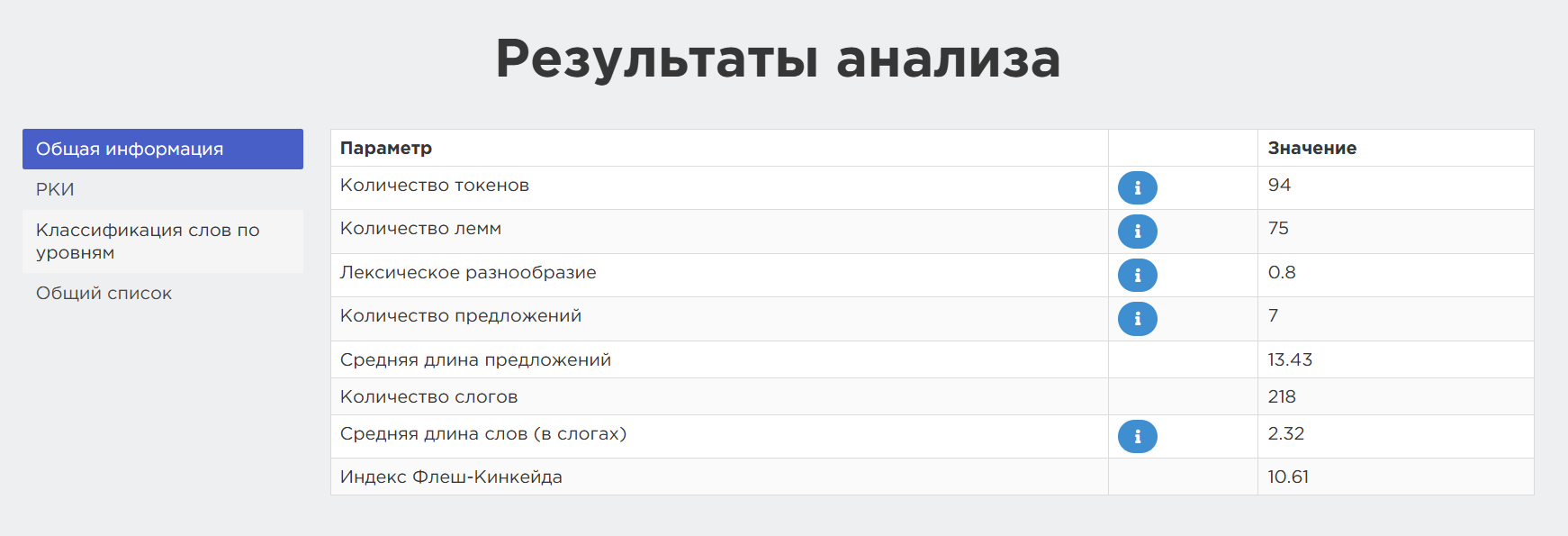
Рис. 17. Результаты анализа адаптированного текста — общая информация
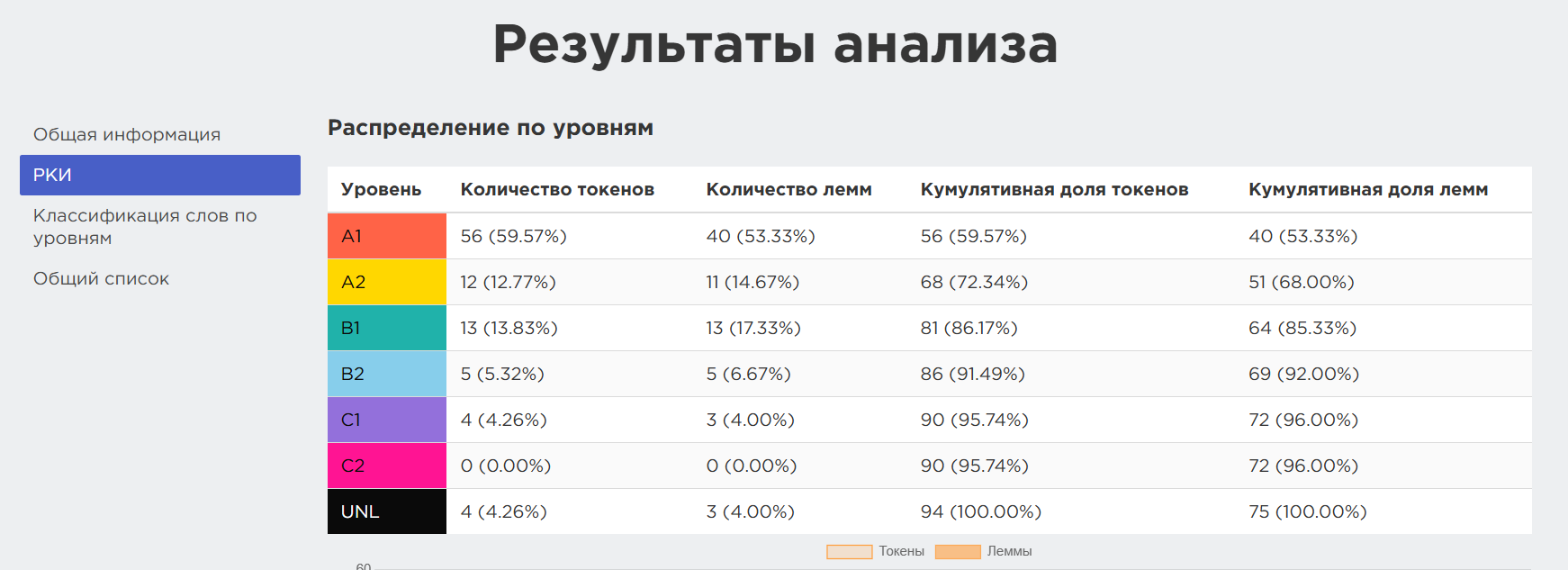
Рис. 18. Информация для преподавателей русского как иностранного
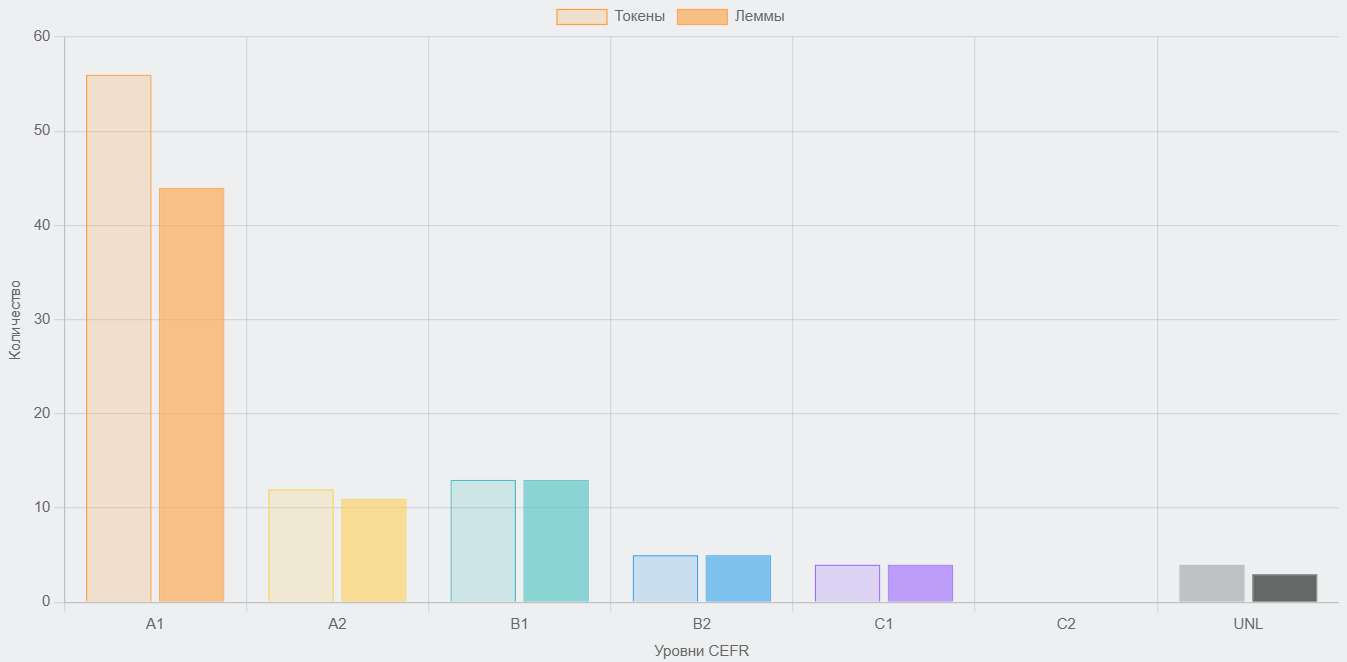
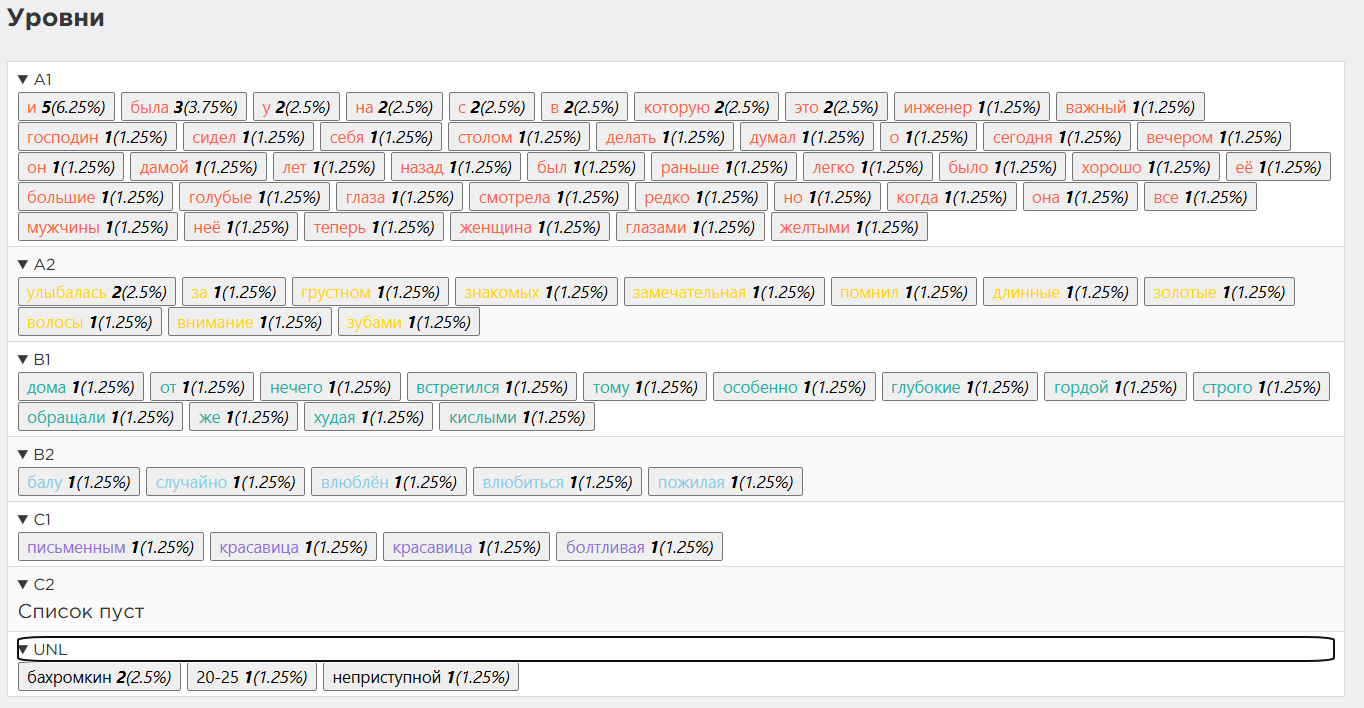
Рис. 19 и 20. Слова в тексте, соответствующие разным уровням языка
Для анализа лексики используется уже упомянутая выше международная шкала CEFR. Загрузив текст, пользователь получает общую статистику, распределение слов по уровням, частотные списки. Также сервис автоматически строит графики для наглядной оценки уровня текста. Кстати, чеховский адаптированный текст этот инструмент, по сравнению с «Текстометром», посчитал более легким.
Создать универсальный алгоритм для оценки сложности текста очень сложно. Эту проблему по-своему пытаются решить разные исследователи. Инструменты пока что ограничены в функционале или находятся в разработке. Так, например, «Текстометр» ожидает глобальных изменений уже этой осенью. Однако даже те наработки, которые уже существуют, позволяют по-новому посмотреть на преподавание и составление учебных материалов.
«Главред»
Измерение сложности текста может быть полезно не только в преподавании, поэтому кроме «Текстометра» существуют и другие инструменты.
Один из самых простых способов оценить текст — посмотреть, есть ли в нем определенные слова, и подсчитать их процент. Так устроен «Главред» — сервис, работа которого основана на методике из книги Максима Ильяхова и Людмилы Сарычевой «Пиши, сокращай». Максим Ильяхов собрал «правила» (авторский термин), чтобы определять клише и стоп-слова в рекламных текстах, а Анатолий Буров воплотил эту идею в виде онлайн-платформы.
У «Главреда» два режима: оценка чистоты и оценка читаемости текста. Вот так выглядит интерфейс:
Рис. 21. Стартовая страница сайта «Главред»
«Главредом» пользуются журналисты и редакторы — сервис позволяет быстро понять, что нуждается в исправлении. Особенно важны критерии чистоты и читаемости в публицистике и маркетинге, где текст должен вызвать отклик у целевой аудитории.
Посмотрим на текст, который появляется, если нажать на кнопку «Вставить пример». «Главред» нашел в нем 31 стоп-слово и посчитал его слишком клишированным. Стоп-слова в тексте выделяются на основе правил Максима Ильяхова, которые постоянно обновляются.
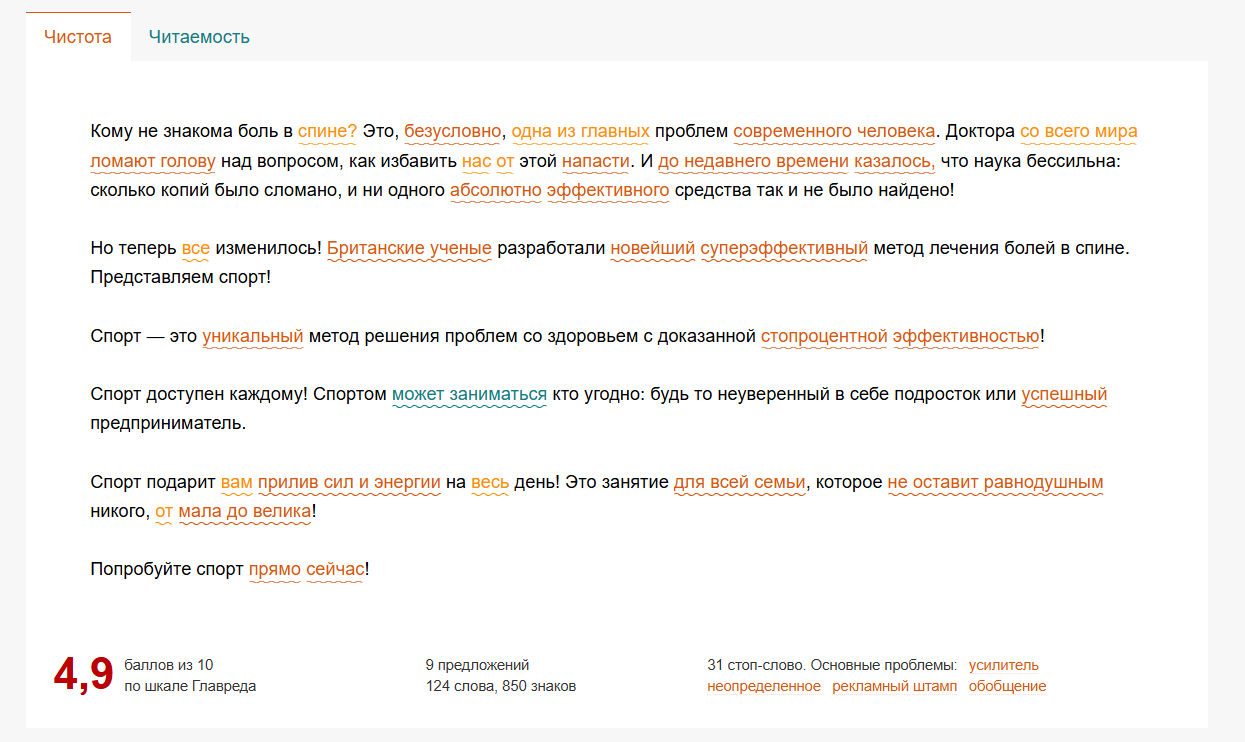
Рис. 22. Результат анализа текста-примера: красным и оранжевым цветом выделены стоп-слова
Если навестись на подчеркнутые слова, «Главред» предложит инструкцию для исправления ошибки. Текст можно отредактировать в том же в окне, результат анализа обновится автоматически.
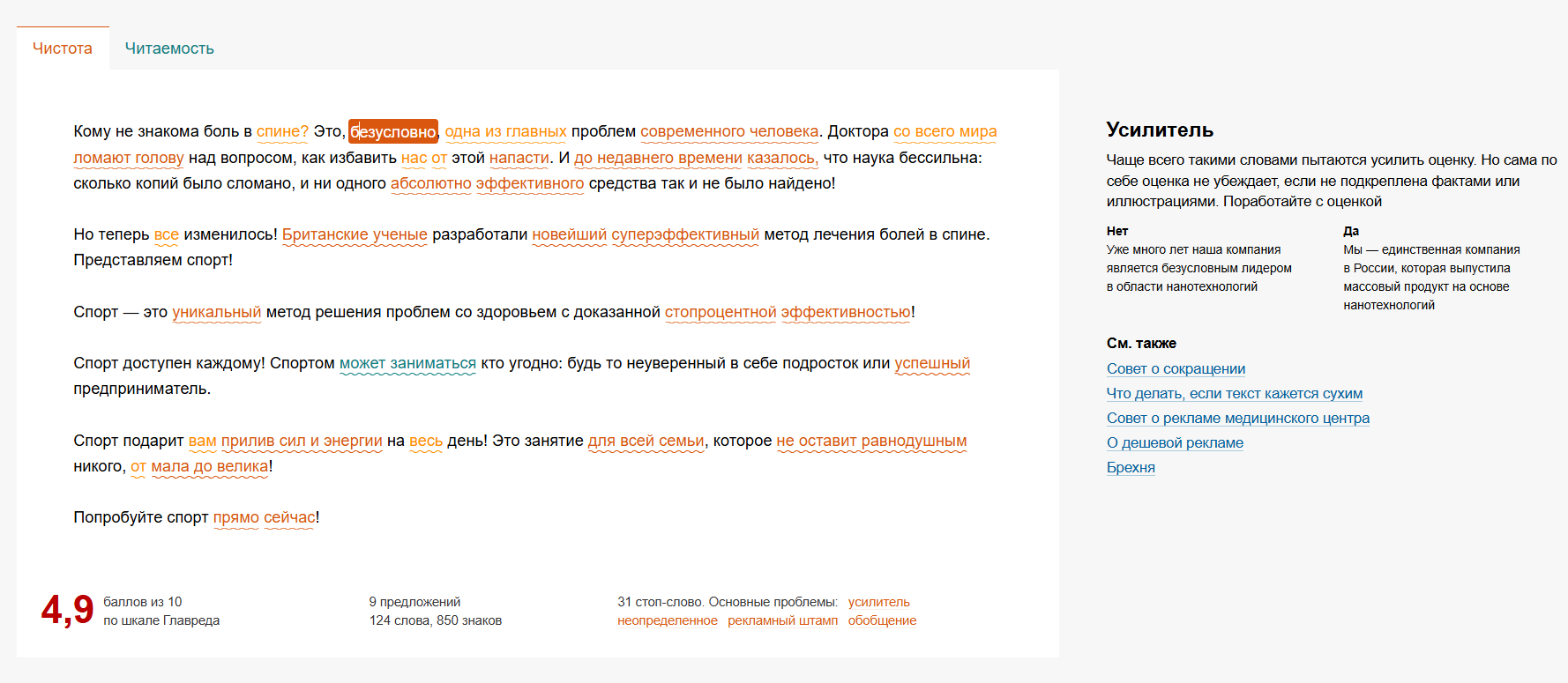
Рис. 23. Справа «Главред» объясняет, в чем проблема, и предлагает варианты исправления для слова «безусловно»
Режим «Читаемость» позволяет посмотреть на текст с точки зрения синтаксиса. По мнению автора книги и создателей сервиса, в основе хорошего публицистического или продающего текста лежит принцип простоты и лаконичности — усложнения синтаксиса делают текст менее понятным для читателя. В этом режиме сервис тоже предлагает варианты упрощения текста и рассчитывает оценку читаемости по 10-балльной шкале.
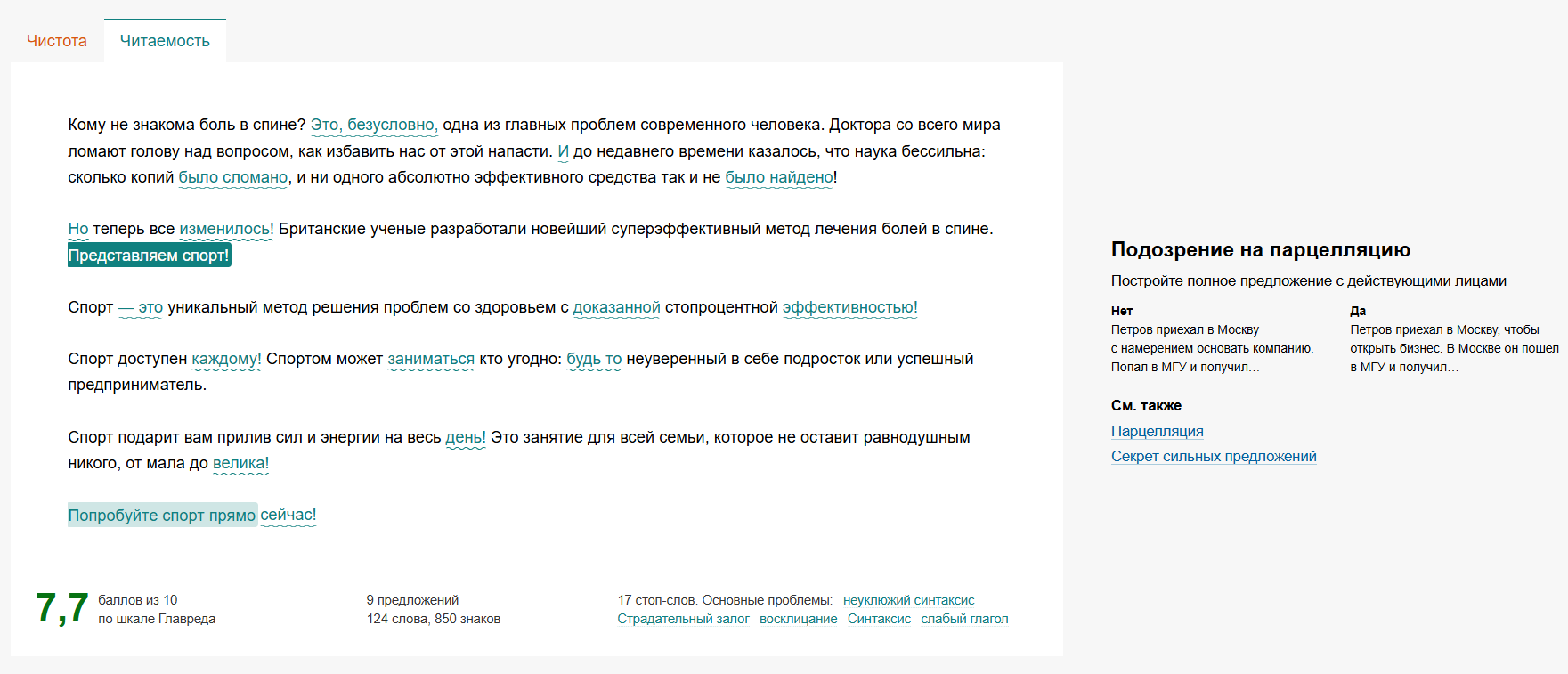
Рис. 24. Пример работы сервиса в режиме «Читаемость»
«Главред» — это полезный инструмент для журналистов, редакторов и маркетологов, однако он имеет свои ограничения. Например, алгоритмы сервиса не учитывают контекст, поэтому он не поможет со стилем и содержанием текста. Предупреждения «Главреда» стоит воспринимать как рекомендации и только ориентироваться на них, не пытаясь исправить текст до максимального балла.
Оценка синтаксической сложности текста от НИУ ВШЭ
Команда аналитиков, юристов и лингвистов из Высшей школы экономики провела исследование языка законодательных актов и предложила свою формулу для оценки сложности текста. Она легла в основу инструмента, который помогает оценить доступность официальных документов, нормативно-правовых актов и научных статей для читателей разного уровня.
Проверим, насколько сложен текст Конституции с точки зрения синтаксиса.
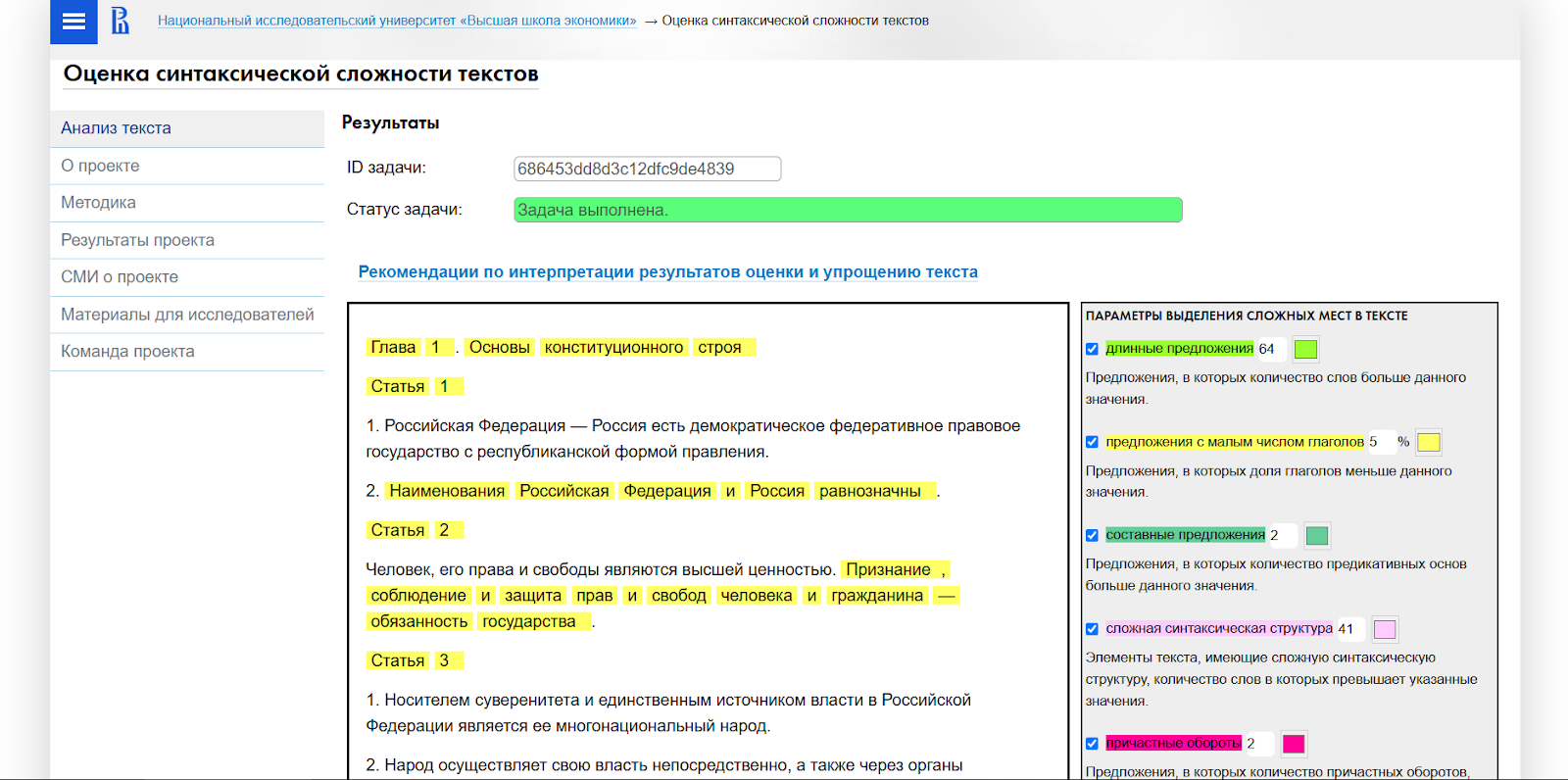
Рис. 25. Результат анализа текста Конституции при помощи сервиса НИУ ВШЭ
Анализ показал, что общая синтаксическая сложность Конституции — 66,75. Согласно шкале, предложенной создателями сервиса, неподготовленный читатель — обычный гражданин — не сможет понять такой текст без дополнительного разбора.
Перспективы
Автоматическая оценка сложности текста — это не только и не столько о том, как рассчитать значение по формуле. Лингвисты, которые стояли у истоков разработки формул удобочитаемости, пытались понять, какие именно параметры определяют сложность текста. Теперь же специальные сервисы рассчитают это за доли секунды, предоставив пользователю частотные списки, статистику по тексту и многое другое. Автоматическая оценка сложности текста — незаменимый инструмент в тех сферах, где важно установить коммуникацию с аудиторией. Это может быть обычный урок, чтение юридического документа или же презентация нового продукта.
Источники
- Лапошина А. Н. Лингводидактическое обоснование применения автоматической оценки сложности учебного текста в преподавании РКИ : автореф… дис. кан. пед. наук. — М.: 2023. — 25 с. URL: https://www.dissercat.com/content/lingvodidakticheskoe-obosnovanie-primeneniya-avtomaticheskoi-otsenki-slozhnosti-uchebnogo/read (Дата обращения: 25.09.2025).
- Маник С. А., Смирнова В. Л. Современные подходы к анализу сложности учебного текста на материале учебников английского языка // Вестник Ивановского государственного университета. 2022. № 2. С. 53–63 URL: https://humanities.ivanovo.ac.ru/wp-content/uploads/2022/06/%D0%92%D0%93%D0%9D22-2-54-64.pdf (Дата обращения: 25.09.2025).
- Оборнева И. В. Автоматизированная оценка сложности учебных текстов на основе статистических параметров : автореферат дис. кандидата педагогических наук : 13.00.02 / Ин-т содержания и методов обучения РАО. — Москва, 2006. — 18 с. URL: https://rusneb.ru/catalog/000199_000009_003261962/?ysclid=mfvmrscea1106011108 (Дата обращения: 25.09.2025).
- Solovyev, Valery & Ivanov, Vladimir & Solnyshkina, Marina. (2018). Assessment of reading difficulty levels in Russian academic texts: Approaches and metrics. Journal of Intelligent & Fuzzy Systems. 34. 1-10. 10.3233/JIFS-169489. URL: https://www.researchgate.net/publication/324583915_Assessment_of_reading_difficulty_levels_in_Russian_academic_texts_Approaches_and_metrics (Дата обращения: 25.09.2025).
- Физика. 7 класс : учеб. для общеобразоват. учреждений с приложением на электронном носителе / В. В. Белага, И. А. Ломаченков, Ю. А. Панебратцев; Российская академия наук, Российская академия образования, издательство «Просвещение». – М. : Просвещение, 2013. – 144 с. : ил. – (Академический школьный учебник) (Сферы). – ISBN 978-5-09-022267-9.

