Погружаемся в тему: акростих
Стихи с секретом: классическая форма
Акростих в своем классическом виде — это такой способ стихосложения, при котором первые буквы каждой строки вместе образуют что-то осмысленное. Таким образом можно зашифровать имена, слова и сочетания слов.

Термин происходит от греческого слова «акростихий» (ἀκροστιχίς), что переводится как «написанное на краю стиха». Самые ранние из дошедших до нас акростихов принадлежат греческому филологу и драматургу Эпихарму, жившему в V веке до н. э. в Сиракузах [3]. Таким изящным способом он подписывал свои произведения. Акростихи пользовались некоторой популярностью в Античности и Средневековье, а также у французских поэтов XIX–XX веков. Много акростихов можно найти у Льюиса Кэррола [1].
У акростиха есть близкие родственники: мезостих (акростих, но в середине строки), телестих (в конце строки), абецедарий (акростих, в котором зашифрован алфавит).
Акростих — это поджанр визуальной поэзии, где графическая форма текста играет значимую роль в его восприятии и интерпретации. И хотя это не самый популярный раздел поэзии, существует множество интересных акростихов — романтических посланий, провокационных высказываний или даже оскорблений. Желающие могут самостоятельно найти послание, которое Павел Мелехин, гострайтер более конъюнктурного поэта Михаила Касаткина, оставил последнему в стихотворении «Месяц в городе ночью не виден…».
Уникальное явление: акростих в прозе
Очевидно, что в прозаическом тексте тоже можно зашифровать что-то с помощью первых букв. Как, например, в следующем предложении:
Скоро ты реально обнаружишь красоту акростиха.
Такие шифры в прозаических текстах встречаются гораздо реже, чем в поэзии. Это явление настолько редкое, что для него даже не нашлось отдельного устоявшегося названия, и его обычно так и называют — акростих в прозе.
В качестве известных примеров акростихов в прозе можно привести политические высказывания Амфитеатрова о цензуре в газетном фельетоне, а также последнее слово Кирилла Серебренникова на судебном заседании по делу «Седьмой студии» [6].

Чтобы расшифровать акростих в прозе, важно понимать, где искать, то есть на каком уровне спрятано послание. Иногда акростих складывается из первых букв каждого слова в предложении, иногда — из первых букв самих предложений или абзацев. Можно, конечно, искать и в других местах (например, в последних буквах, в каждом втором слове и проч.), но чаще всего авторы выбирают один из этих трех способов.
Ниже приведены примеры акростихов по разным уровням.
Каждое слово:
Собственно, именно структурные текстовые единицы могут нести информацию и бесчисленные литературные образы, конструкции.
Отметим, что это самый сложный вид акростиха. Сложить что-то осмысленное и адекватно звучащее из заданных первых букв — большая удача. В основном все тексты с акростихами этого уровня похожи на генерацию старых нейросетей. Также обратите внимание на замену букв ы и й на букву и.
Первые буквы первых слов предложения:
Случается, одна мысль неожиданно приводит к другой. Тогда идеи складываются в осмысленный узор. Иногда кажется, что это и есть поток вдохновения. Хотя на деле всё рождается из терпеливой работы.
Первые буквы абзацев:
Судебная речь Кирилла Серебренникова, упомянутая выше.
Зачем авторы это делают?
Мы разобрались с тем, что такое акростихи — в поэзии и прозе. Посмотрели, на каких уровнях они складываются. Теперь несколько слов о том, зачем их складывают.
Во-первых, это способ авторской подписи. Помимо древнейших акростихов Эпихарма можно привести в пример роман «Тайна греческого гроба» Эллери Куин (творческий псевдоним Даниэля Натана и Эмануэля Леповски). Первые буквы названий глав этого романа образуют заглавие книги и имя автора.
Во-вторых, акростих — это способ спрятать что-то, что нельзя или сложно произнести явным образом. Оскорбления (послание Павла Мелехина, которое упоминалось выше), политические высказывания (Амфитеатров, Серебренников, скандал на конкурсе фантастических рассказов в 2022 году [7]).
В-третьих, акростих может использоваться для дополнения текста сюжетными, смысловыми и эмоциональными элементами. Например, у Набокова в рассказе «Сёстры Вейн», написанном на английском языке [5], последние буквы каждого слова в последнем абзаце складываются в предложение, представляющее рассказ совершенно в другом плане. Кстати, известный переводчик Набокова Владимир Барабтарло признается, что так и не смог перевести этот шифр удовлетворительным образом [8].
Разрабатываем инструмент
Небольшое исследование, из которого родилась эта статья, возникло из предположения, что по прозаическим текстам разбросано множество скрытых посланий, ждущих своего открывателя. Советские писатели, обходящие цензуру, предполагаемые авторы книг с оспариваемым авторством, шифрующие свою подпись. Нужно только придумать, как автоматизировать и прогнать через автоматический поиск как можно больше текстов.
Концепция алгоритма
На первый взгляд, алгоритм поиска акростихов довольно простой. Нужно собрать по исследуемому тексту первые буквы (слов/предложений/абзацев — в зависимости от уровня поиска), нарезать из них «скользящим окном» потенциальные слова, а затем оставить только те, которые найдутся в словаре настоящих слов (о словаре ниже).
Основа для проверки: выбираем словарь
Алгоритм есть, осталось найти хороший словарь, по которому можно проверять кандидатов. Важный момент: нужен словарь всех форм слов, а не только исходных, поскольку зашифрованные слова могут стоять в какой угодно форме. То есть в словаре, с которым мы будем сверяться, должно быть не только слово «рыбак», но и «рыбаки», «рыбаку», «рыбакам» и т. д.
Первый словарь для проверки идеи и отладки алгоритма был сгенерирован простым скриптом из 10–15 книг, взятых наугад. Затем оттуда были извлечены все уникальные словоформы, которые встретились больше 10 раз. На выходе получилось примерно 20 тысяч словоформ. Затем был найден хороший готовый словарь на 1,5 миллиона словоформ.
Несколько замечаний про подготовку словаря для тех, кто хочет воспроизвести исследование самостоятельно. Так как акростих складывается из первых букв, нужно обработать слова с ъ, ы, ь, а также — желательно — с буквами э и ю. Нужно или убрать их из словаря совсем, или удалить из них ъ, ы, ь, а э, ю заменить их на е и у. В последнем случае можно оставить первоначальные варианты вместе с модифицированными, чтобы точно ничего не упустить.
Для экономии вычислений я искал только акростихи размером n (обычно 5–7) букв. Соответственно, можно сделать словарь, в котором не будет слов меньше n букв, а слова, длина которых будет больше n, обрезать до n букв (например, из слова «человек» сделать слово «челов»). Найденные слова затем можно проверить через исходный (полный) словарь.
Данные
По счастливому совпадению у автора статьи после магистерской работы [2] остался корпус русской классики на 300+ текстов (19 и 20 век), который использовался для первого прогона алгоритма.
Нюансы обработки текстов для тех, кто хочет сделать собственное исследование:
- Все желательно привести к единому регистру.
- В текстах часто встречается такая р а з м е т к а, которая будет считываться как зашифрованное послание. Вообще, считается, что так разряжать неправильно, потому что разрядка — это элемент оформления, а оформление не должно влиять на содержание текста и должно располагаться на отдельном слое. Такую разрядку (а также вот такие в-о-з-г-л-а-с-ы и В.О.Т такие вещи) можно убрать с помощью регулярных выражений при первичной обработке текста.
Ожидания и реальность. Попытка № 1
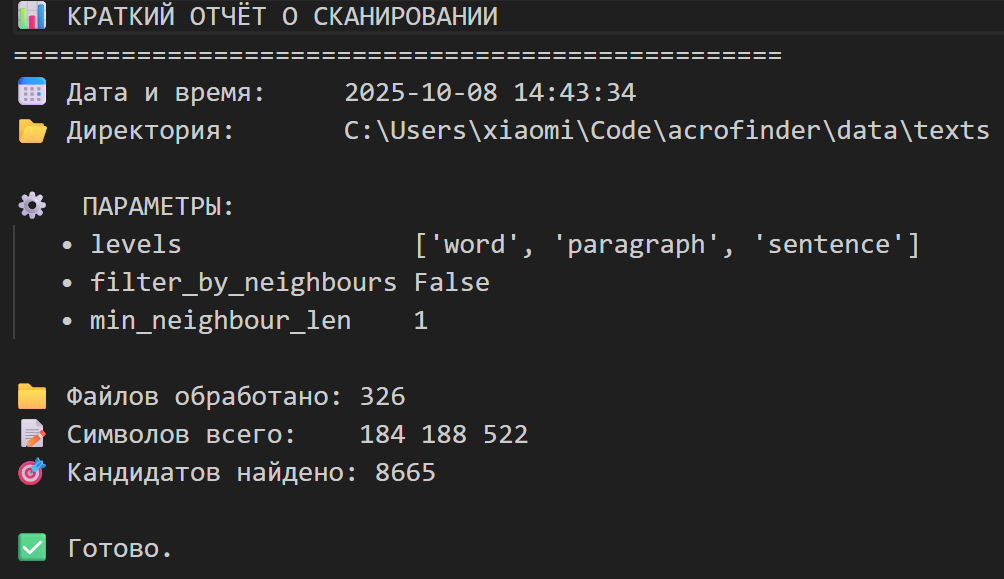
В результате первого прогона видим, что есть находки, даже множество! На корпус из 326 текстов приходится 8665 совпадений, построенных от 6+ буквенных n-грамм.
Однако видим, что все находки — это случайные совпадения.
Немного статистики
На самом деле, такой результат был вполне предсказуем. Попробуем подсчитать вероятность того, что случайная последовательность, например, из 6 букв, окажется словом из словаря.
Из 30 букв русского алфавита (исключая ъ, ы, ь) можно сложить 30^6, т.е. 729 миллионов «слов». Для простоты будем считать, что первые буквы распределены равномерно и все 729 миллионов сочетаний равновероятны.
В исходном словаре, с которым мы сверяемся, 54 827 слов из 6 букв. Соответственно, вероятность того, что случайная комбинация из 6 букв окажется словарной — 54 827 / 729 000 000 = 0.0000752085, то есть примерно 75 случаев из миллиона.
Средний размер художественного романа — 100 000 слов. Из него получится набор 100 000 первых букв, из которых скользящим окном можно построить 99 995 слов (из последних 5 букв 6-буквенного слова не получится). Учитывая вероятность 0.0000752085, примерно 7–8 слов из полученных должны оказаться словарными.
Соответственно, корпус из 300 произведений даст нам чуть больше двух тысяч словарных слов в качестве случайных совпадений.
Это предварительный расчет для слов из 6 букв, полученных только на уровне слов (без учета первых букв предложений и абзацев). Он основан на предположении об одинаковом распределении первых букв. На самом деле, случайных совпадений должно быть еще больше.
Внедрение фильтра и большой корпус. Попытка № 2
Хороший фильтр
Итак, нужен способ отфильтровать как можно больше случайных совпадений, не упустив настоящие акростихи.
Основные опции для фильтра:
- уменьшать словарь, с которым мы сверяемся (можно, но страшно выпустить что-то);
- искать только длинные слова, потому что чем длиннее, тем меньше число случайных совпадений (этот вариант использовался как рабочий в ходе первоначального исследования);
- для каждого найденного словарного слова проверять соседей — не окажутся ли и они словарным словами.
Третий вариант представляется наиболее перспективным: большая часть известных примеров состоит из нескольких слов. Более того, в отношении одиночного зашифрованного слова (особенно короткого), даже если оно будет найдено, сложно доказать преднамеренность. Тем не менее будущим исследователям акростихов в прозе останутся темные уголки, в которые я не заглянул.
Отбор кандидатов по соседним словам
Будем искать несколько словоформ подряд. У нас уже есть алгоритм, который позволяет находить единственное слово длины n+, которое есть в словаре. Добавим следующие действия для поиска соседей у найденного слова:
- Установим минимальный размер для слова-соседа m (не проверяем однобуквенные слова, начинаем с m, чтобы сократить случайных кандидатов);
- Берем m букв слева от найденного слова, проверяем, есть ли в словаре такое слово;
- Если нет, берём m+1 букв слева и проверяем — и так далее, пока не дойдём до максимального размера слов в словаре;
- Если какое-нибудь из соседних сочетаний окажется словарным словом, добавляем находку в наш список найденных акростихов;
- После проверки слева — проверяем симметрично справа.
Дополнительный корпус: нюансы парсинга
У нас есть алгоритм с хорошим фильтром, который отсеет большое количество случайных совпадений. Теперь нужно найти большой корпус.
После поверхностного поиска оказалось, что хороших русскоязычных корпусов большого размера нет. Поэтому было решено взять раздел классики на az.lib.ru. Можно спарсить страницу авторов, по ним собрать названия текстов и ссылки, а по ним уже сами тексты. Там больше 70 тысяч произведений.
И снова комментарий для тех, кто решит воспроизвести исследование. Вместо раздельного парсинга корпуса и последующего прогона через алгоритм, лучше обрабатывать ссылки последовательно, чтобы не терять прогресс: скачивать текст, обрабатывать и тут же сканировать на потенциальные акростихи.
Анализируем результаты: что (не) удалось найти
Были просканированы 72 137 текстов с az.lib.ru. Было найдено 1763 потенциальных акростиха. Потенциальные акростихи были проверены вручную. И… к сожалению, скрытых сокровищ, про которые срочно писать во все литературоведческие журналы и ехать с ними на конференции, не нашлось.
Настоящий акростих
Единственная настоящая находка: заметка Амфитеатрова, про которую мы писали в самом начале статьи. Причем самой заметки в корпусе не было, но было найдено ее цитирование в дневнике журналиста Владимира Короленко [9]:

Интересно, что Короленко называет криптограмму «школьническим приемом». Если акростихи действительно считались ребячеством, которым не стоит заниматься серьезному литератору, это может объяснить отсутствие находок. Здесь же стоит упомянуть, что Набоков писал в предуведомлении к одному из изданий «Сестёр Вейн», что такое (акростих, зашифрованный в каждом слове последнего абзаца) можно позволить себе только раз за тысячу лет литературы [4].
Единственная находка
Утешением во всех моих бесплодных поисках стал единственный интересный результат. Он попался мне случайно в самом начале исследования, и последний фильтр он бы не прошел. Это акростих из рассказа «Заклинатель змей» Варлама Шаламова [10]. Это явно случайное совпадение, но интересное: из первых букв предложений складывается слово «олени», которое тут же появляется в следующем предложении.
О кошке правильнее было бы сказать – эта тварь живуча, как человек. Лошадь не выносит месяца зимней здешней жизни в холодном помещении с многочасовой тяжелой работой на морозе. Если это не якутская лошадь. Но ведь на якутских лошадях и не работают. Их, правда, и не кормят. Они, как олени зимой, копытят снег и вытаскивают сухую прошлогоднюю траву.
Логичные итоги, датасет и утилита
Можно ли настроить алгоритм для автоматического поиска? Да — автоматический алгоритм нашел в корпусе процитированный акростих Амфитеатрова.
Рассыпаны ли зашифрованные послания по классическим литературным произведениям? Скорее всего, нет.
Что можно сделать еще? Можно сделать поиск по другим корпусам — поэтическому корпусу, по новостным и публицистическим сайтам (например, lenta.ru, proza.ru и проч.). Можно взяться за корпуса на других языках, если найти подходящий словарь (на английском с его неизменяемостью слов должно быть гораздо проще).
Утилита для поиска представлена в публичном репозитории. К ней прилагается нормальный readme, демонстрационный ноутбук, а также ноутбук со сканированием lib.ru. Если у вас возникнут вопросы по коду или исследованию — ищите меня в телеграме.
Отдельно привожу ссылку на датасет с результатами большого прогона на указанных параметрах. Допускаю, я что-то упустил, пока просматривал эту таблицу, поэтому желающие могут поискать настоящие акростихи или хотя бы забавные или поэтичные совпадения (вроде «носчик ирисов» или «имама мимами [дразнили, имама мимы довели]»). Если вы это сделали, — напишите мне (даже если ничего не нашлось).
Источники
CSV с результатом анализа более 70 тысяч произведений
Литература
1. Александровна С. Е., Владимировна В. В. Способы кодирования имени собственного (на материале акростихов Л. Кэрролла) // Филологические науки. Вопросы теории и практики. 2025. № 3 (18). C. 858–864.
2. Дуненков Е. Использование синтаксических особенностей текста для атрибуции авторства – Выпускные квалификационные работы студентов НИУ ВШЭ – Национальный исследовательский университет «Высшая школа экономики» [Электронный ресурс]. URL: https://www.hse.ru/edu/vkr/1054371506 (дата обращения: 18.10.2025).
3. Михайлов М. А. Акростих как инструмент идеологической борьбы // Юрислингвистика. 2005. № 6. C. 254–262.
4. Johnson R. The Vane Sisters — critical analysis and commentary — 48/50 // Mantex [Электронный ресурс]. URL: https://mantex.co.uk/the-vane-sisters/ (дата обращения: 18.10.2025).
5. Nabokov V. The Vane Sisters / V. Nabokov,.
6. Театръ • Речь Кирилла Серебренникова в суде [Электронный ресурс]. URL: https://oteatre.info/rech-serebrennikova/ (дата обращения: 18.10.2025).
7. Леонид Каганов: [Электронный ресурс]. URL: https://lleo.me/dnevnik/2023/04/24 (дата обращения: 18.10.2025).
8. Сестры Вейн (перевод Г. Барабтарло) [Электронный ресурс]. URL: https://nabokov-lit.ru/nabokov/rasskaz/sestry-vejn-barabtarlo.htm (дата обращения: 18.10.2025).
9. Lib.ru/Классика: Короленко Владимир Галактионович. Письма к П. С. Ивановской [Электронный ресурс]. URL: http://az.lib.ru/k/korolenko_w_g/text_1917_pisma_k_ivanovskoy.shtml (дата обращения: 18.10.2025).
10. Заклинатель змей // Варлам Шаламов [Электронный ресурс]. URL: https://shalamov.ru/library/2/18.html (дата обращения: 18.10.2025).