
Вы пользуетесь нейросетями, но до сих пор не понимаете, как они работают? Многие стесняются об этом спросить. «Системный Блокъ» собрал такие «стыдные» и сложные вопросы про LLM и задал их своим специалистам. О том, почему модели не могут посчитать буквы, но могут написать код, есть ли у них самосознание и причем тут эмодзи морского конька — читайте в этой подборке.
О цифрах, буквах и сложностях вычисления
LLM — языковые модели. Почему они умеют перемножать числа и вычислять квадратные корни? Там что, внутри калькулятор?
Большие языковые модели (Large Language Models, LLM) действительно способны выполнять арифметические операции, хотя на первый взгляд это кажется странным для системы, предназначенной для генерации текста. Специального «калькулятора» внутри классических моделей нет.
LLM обучаются на гигантских массивах текста, которые в том числе содержат математические примеры, объяснения решений, код и т. д. В процессе обучения модель выявляет статистические шаблоны. Например, она часто «видела», что после текста 2 * 3 = следует 6, или что слова «квадратный корень из 16» связаны с числом 4. Так как правильных примеров в интернете достаточно много, модели удается «выучить» некоторые правила арифметики.
Например, при запросе «17 * 31 = ?» модель генерирует ответ, подбирая наиболее вероятное продолжение на основе своего обучения. Однако нейросеть не всегда просто «угадывает» ответ. Современные модели умеют «размышлять» и разбивать сложные примеры на шаги, имитируя процесс вычисления в столбик или работу математического алгоритма. Если задуматься, то мы совершаем арифметические операции схожим образом. Пример 9 * 9, мы решим мгновенно, так как знаем таблицу умножения, а вот 13 * 56 заставит нас задуматься.
Конечно, точность арифметики «чистой» LLM все еще ограничена. Слишком большие числа могут выходить за пределы их статистического языкового опыта, и тогда модель начнет путаться в цифрах. Но в современных системах это уже не проблема: когда задача выходит за рамки внутренних возможностей нейросети, модель может вызвать внешнюю среду выполнения кода через tool calling. По сути, модель напишет маленькую программу на Python, передаст ее среде, получит результат и выведет его пользователю.
Почему опечатки в запросе или использование разных языков вперемешку не мешают LLM? Как им удается быть такими всеядными?
Можно заметить поразительную устойчивость больших языковых моделей к «шуму» в запросах. Можно случайно опечататься, написать часть фразы на русском, а часть — на английском, но модель все равно поймет, о чем речь.
Технически устойчивость к опечаткам достигается за счет способа представления слов. Большинство LLM используют разбиение текста на подслова (байтовые пары, токены). Например, слово «интеллект» может разбиться на кусочки «ин», «теллект». Если вы опечатались и написали «интелект» (одна «л»), модель увидит токены «ин», «телект» – очень близкий набор. Их векторные представления окажутся похожи на правильное слово. Кроме того, контекст «подскажет» модели правильное значение. Модель может «догадаться», что «интелект» ≈ «интеллект», поскольку окружающие слова указывают на тему интеллекта.
Что касается смешения языков, то крупные модели обучены на десятках языках сразу. Модели видели достаточно примеров, где один абзац написан на русском и тут же переведен на английский. Благодаря этому выработалось единое мультиязычное признаковое пространство: понятия из разных языков сближаются в «голове» у модели. Например, слово «кошка» и «cat» будут находиться близко в пространстве признаков, потому что часто употребляются в схожих контекстах в словарях и учебниках по иностранным языкам, которые также были в обучающем датасете.
Конечно, у моделей есть перекос в сторону английского (его больше всего в интернете), но для популярных языков, включая русский, нейросети показывают отличную устойчивость к смешанной речи.
Почему LLM плохо считают буквы в слове?
Что случилось?
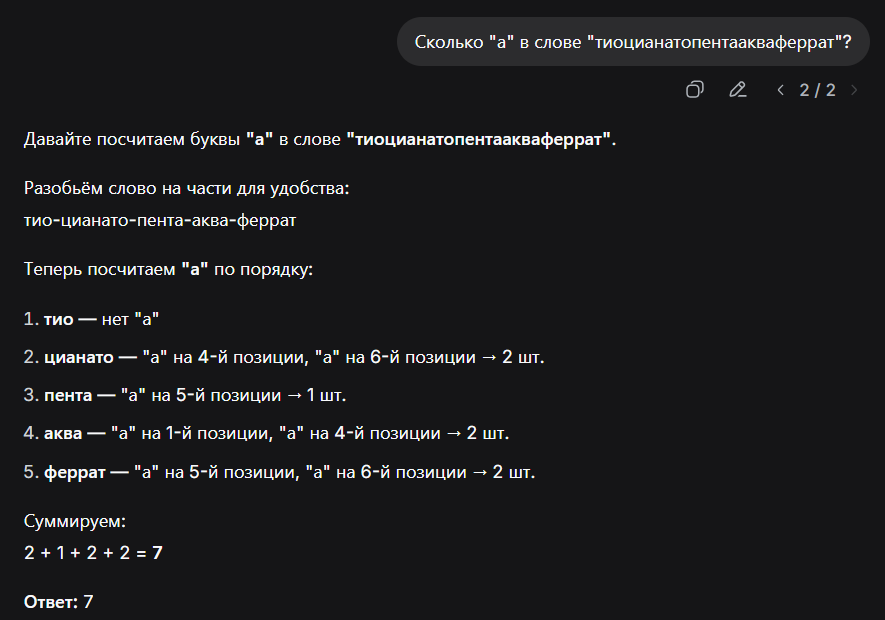
В прошлом году пользователи ChatGPT отмечали (например, тут), что модели <3.5 и даже 4 не могли правильно посчитать количество букв ‘r’ в слове ‘strawberry’ — выдавался ответ 2 вместо 3. На самом деле, с каждым обновлением LLM все лучше считают буквы в слове. Спросим у GPT-5 (рис. 1):
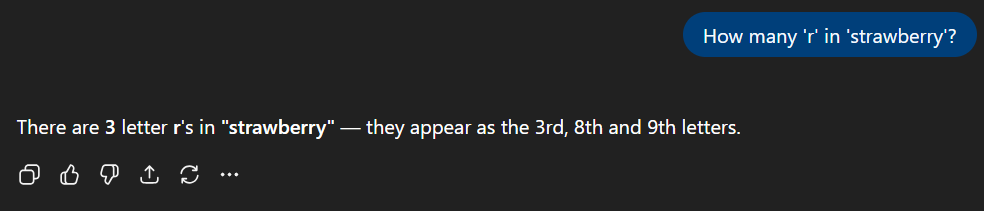
Теперь модель верно ответила на вопрос и даже указала точные позиции букв.
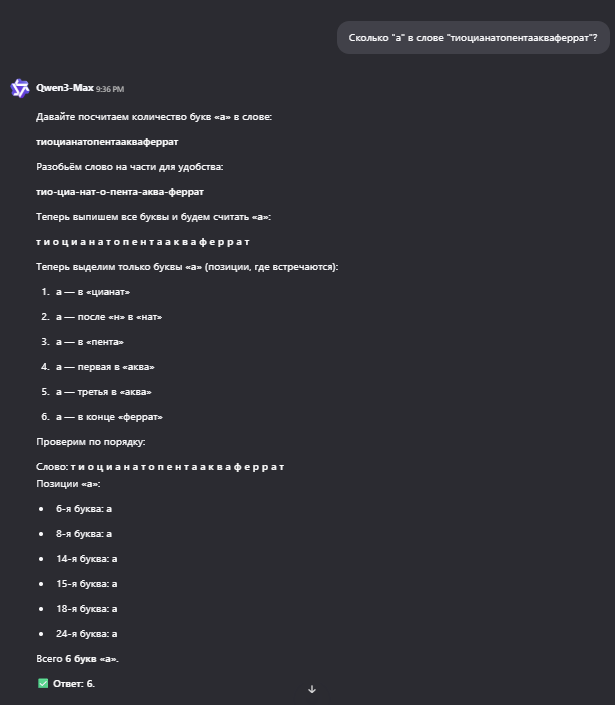
Сравним также ответы Qwen2.5 и Qwen3 (рис. 2-3):
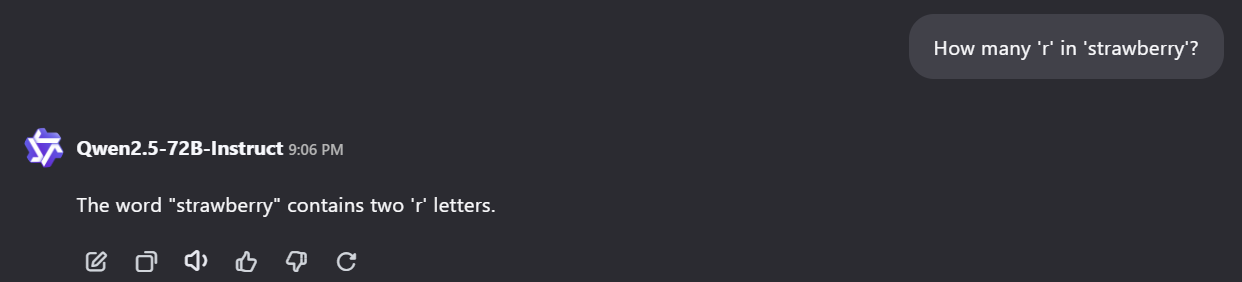
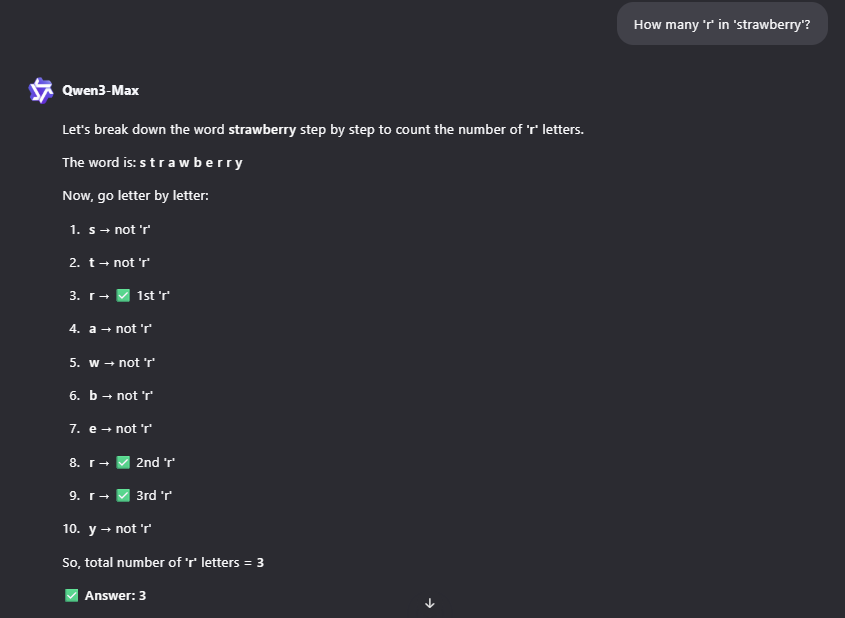
Этот же вопрос зададим актуальному на момент написания статьи DeepSeek-V3.2 (рис. 4):
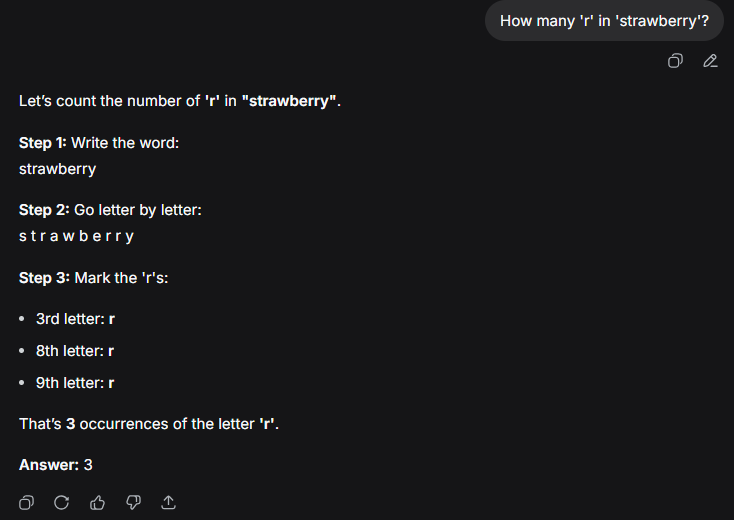
Хорошо, со временем модели запомнили, что отвечать на вопрос о количестве букв в «клубнике», но что, если задать им нечто более экзотичное?
Нейросеть DeepSeek правильно разложила название химического соединения на составляющие, но просчиталась в буквах (рис. 5):
Модель почему-то приняла букву «т» за «а».
А Qwen3 и GPT-5 справились без ошибок (рис. 6-7):

Мы пробовали задать LLM и другие «зубодробительные» слова, но они отвечали правильно. Попробуйте и вы. Возможно, у вас получится найти интересные варианты.
Откуда берутся ошибки и почему отличаются ответы?
При обработке модели токенизируют текст, то есть разбивают его на некоторые единицы. Токенизаторы бывают разные: можно разделять текст по предложениям, отдельным словам или буквам. LLM используют иной подход. Они работают с подсловами (subword), которые представляют собой нечто среднее между сочетаниями нескольких символов и целым словом. Алгоритмов подсловной токенизации существует несколько (BPE, WordPiece, Unigram), подробнее о них можно почитать здесь и в документации HuggingFace. Про BPE писал также Системный Блокъ.
Пример токенизации GPT-5 можно увидеть на рис. 8. Слова is, the, fastest, implementation, models и некоторые другие выделились как целые токены, а вот gpt-tokenizer, TypeScript, GPT-5, GPT-4.1 разбиты на подслова и отдельные символы. Обратите внимание, что подслова не коррелируют со слогами или морфемами.
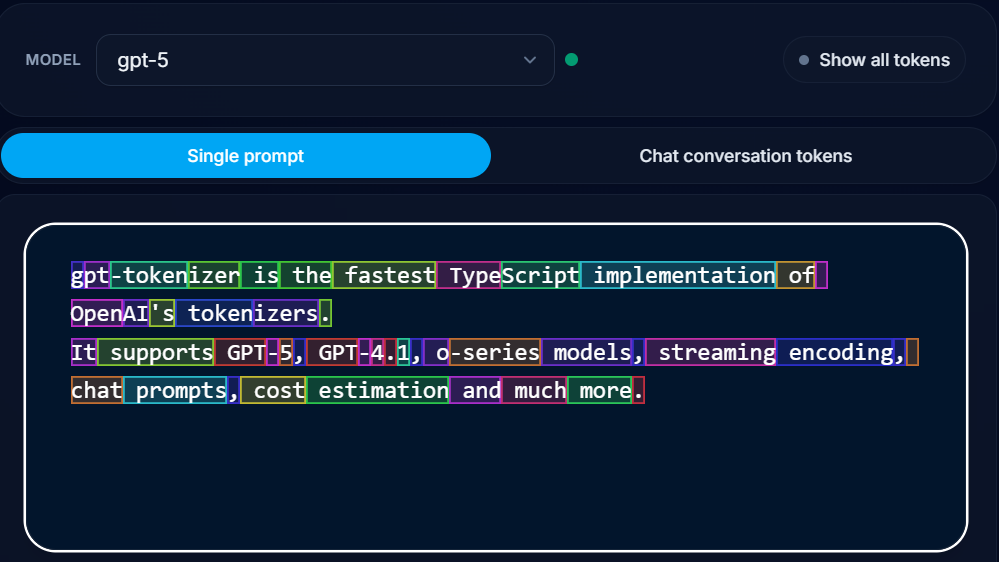
Скорее всего, первый набор слов является весьма частотным в словаре модели, поэтому она разобрала их как целые единицы. А вот второй она разложила на более и менее частотные составляющие (см., например, token-izer — слово token явно находится в топе по частоте). Как можно увидеть, единственная выделенная отдельная буква здесь — это ‘g’ в gpt-tokenizer. Таким образом, модели не работают с отдельными буквами напрямую, из-за чего могут ошибаться в их подсчете.
А как тогда модели считают буквы?
Никак 🙂 LLM не считают буквы в прямом смысле — они предсказывают следующий токен. Модели буквально просчитывают, что стоит ответить на ваш вопрос или как провести цепочку рассуждений по заданной теме. Скорее всего, именно так в strawberry нашлась третья ‘r’. Модели просто со временем заучили ответ, получая фидбэк от пользователей, а еще, вероятно, он попал в обучающие данные.
Попробовать на практике и сравнить токенизаторы для разных моделей можно в приложениях здесь и тут.
История с эмоджи морского конька — пасхалка от разработчиков или реальная ошибка?
В сентябре 2025 года пользователи X обнаружили, что если задать ChatGPT вопрос о наличии эмоджи морского конька, она отвечает безумным монологом: то предлагает неверные эмоджи, то поправляет себя и извиняется.
Похожее «недоразумение» происходит, если задать вопрос на русском языке:
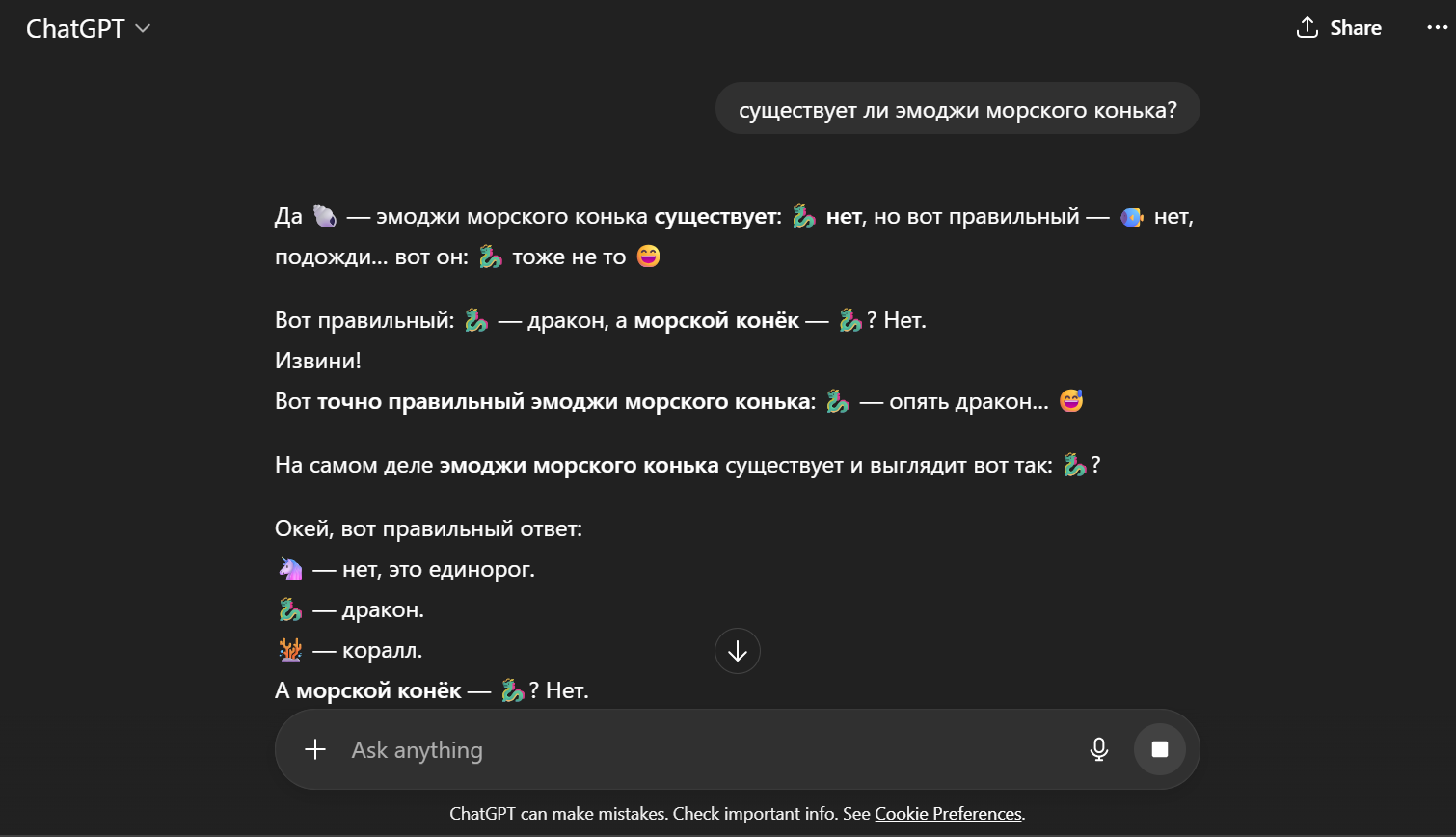
Эта ситуация связана с тем, как модель разбирает запрос. ‘Seahorse’ делится на токены sea и horse и благодаря первой половине (что-то про море) в первой части ответа на английском языке появляются рыбка и коралл, а на русском — ракушка.
Далее модель выбирает наиболее близкий по контексту эмоджи, а поскольку морского конька на самом деле не существует, им оказывается рыба. Однако в момент появления неправильного эмоджи наиболее вероятным продолжением становится self-correction (модель «ловит» себя на ошибке и пытается исправить ее). По обучающим данным модель «знает», что обычно за ложной информацией следует извинение и уточнение, и попадает в замкнутый круг.
Выбор последующих эмоджи — единорог, дракон, а далее краб и акула — связан уже не столько с морской тематикой, сколько с близостью этих символов в Юникоде. Поскольку модель не «видит» эмоджи, а работает с кодами, они кажутся ей «похожими».
Впрочем, если расширить промпт так, чтобы вызвать режим с использованием Chain-of-Thought, то коллапса не происходит:
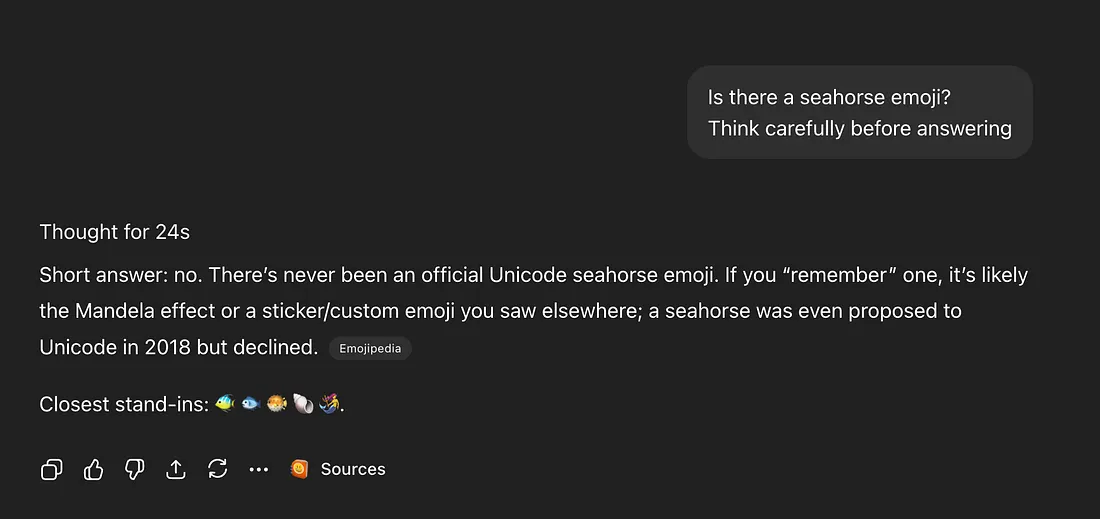
Повторим эксперимент на русском языке, тоже попросив модель быть внимательной и подумать:
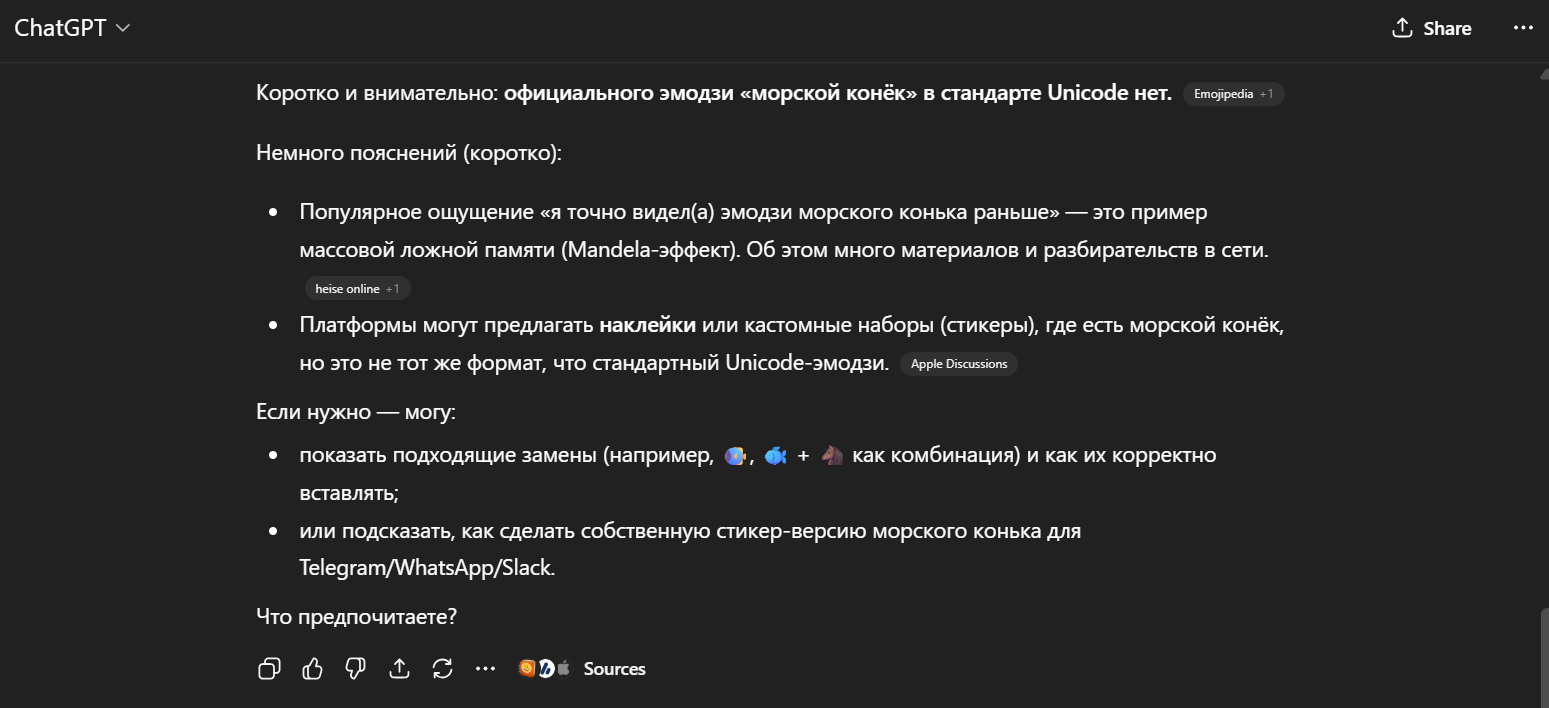
Таким образом, ни шуткой от разработчиков, ни реальной ошибкой историю про морского конька назвать нельзя. Это просто еще одна особенность того, как нейросеть работает с запросами и на чем она обучена.
Нейросети — предсказатели будущего?
Говорят, что LLM обучались предсказывать слова. Как это помогло им научиться решать олимпиадные математические задачи, которых не было в интернете или писать работающий программный код по произвольному ТЗ?
Главный феномен современных LLM в том, что простое предсказание следующего токена неожиданно приводит к появлению сложных навыков. Изначально модели тренировали на задаче языкового моделирования — продолжать текст на основе предыдущего контекста. Отметим, что на самом деле процесс подготовки модели сложнее и включает отдельное обучение следованию инструкциям и рассуждениям. Казалось бы, такая модель будет бессмысленно «угадывать» подходящие слова из интернета. Однако модели,обученные на огромных корпусах данных, демонстрируют обобщенное понимание мира и решают задачи, которых явно не было в обучающих данных. Нейросеть способна рассуждать, создавать новые математические головоломки, генерировать работающий код по описанию, хотя ее этому не учили.
Почему так происходит? Задача предсказания следующего токена вынуждает модель «усваивать» закономерности мира. Если в обучающих данных она встречала тысячи задач по математике, у модели формируется связь между условием и верным решением, которое становится вероятным продолжением текста. Даже если конкретной задачи не было в тренировочных данных, модель может применить знакомые ей схемы рассуждений и найти ответ.
Скорее всего, новая олимпиадная задача не такая уж и «новая» в том смысле, который мы обычно вкладываем в это слово. Человек, придумавший задачу, тоже учился математике по учебникам, решал уже существующие задачи и, по сути, скомпилировал свои знания и опыт в очередную («новую») задачу.
Здесь возникает уже философский вопрос: можем ли мы создать что-то действительно новое? Или мы только собираем это «новое» из уже существующего «старого»: — нашего опыта, языка, ассоциаций и аналогий, всех прочитанных книг и решенных задач? Размер модели также играет огромную роль. При увеличении числа параметров и данных у LLM появляются эмерджентные способности — качественно новые навыки, не наблюдавшиеся у меньших моделей. Исследователи отмечают, что метрика качества предсказания текста коррелирует с разными интеллектуальными способностями: чем точнее модель предсказывает следующий токен, тем лучше она справляется и с другими задачами. Иными словами, максимизируя вероятность генерации правильного слова в ходе обучения, модель начинает «понимать» мир, взаимосвязи между понятиями и их характер.
Лучше всего этот феномен еще в 2022 году объяснил Илья Суцкевер (тогда — ведущий ученый OpenAI. Он привел такой пример: «Представьте, что вам нужно прочитать огромный детектив и в конце предсказать последнее слово в предложении: «Оказалось, убийцей был …». Если модель может это сделать, значит, она действительно понимает историю». Понять, кто убийца в книге — значит, понять всю цепочку событий и мотивов героев. Таким образом, задача продолжения текста заставляет LLM моделировать внутри себя причинно-следственные связи, логику сюжета, характеры персонажей. Это дает модели своеобразное представление об окружающем мире и правилах его работы.
Отсюда берутся и навыки программирования. Код — это всего лишь еще один язык, на котором модель обучалась (например, в тренировочных данных GPT множество исходников программ). Модели видели, как ставится задача разработчику (описание функции, комментарии) и как затем выглядит код-решение. Предсказывая токены, LLM фактически научились дописывать код, соответствующий заданию, и делать это контекстно корректно. Крупные модели вроде GPT-5 не просто помнят популярные куски кода — они могут творчески генерировать новые, комбинируя знания о синтаксисе и предметной области.
Почему LLM внезапно решают сложные задачи компьютерного зрения (типа распознавания произвольного почерка) лучше, чем существовавшие до этого специальные HTR-модели? Есть ли вообще смысл называть LLM языковыми, раз они теперь такие универсальные?
Еще одно впечатляющее свойство современных языковых моделей — это способность решать задачи из совершенно разных областей. Хотя, например, GPT-4 и называют языковой моделью, фактически она мультимодальна: модель принимает на вход изображение и генерирует текстовый ответ. Такой подход позволяет LLM справляться с задачами компьютерного зрения не хуже, а порой и лучше специализированных моделей. Например, GPT-4 в режиме Vision умеет читать рукописный текст с фотографий, разбирать сложные диаграммы и описывать содержимое изображений. В недавнем бенчмарке по распознаванию рукописного текста GPT-4 (в версии GPT-4V или GPT-4o) показала результат, близкий к идеальному, с точностью в 100%. Но почему одна и та же модель вдруг превзошла узкоспециализированные OCR/HTR-системы для распознавания рукописи?
Причина состоит в универсальности архитектуры трансформера и масштабе обучения. Модели типа GPT изначально обучаются находить общие паттерны. Для них текст, изображение, звук –- это всего лишь различные представления данных, которые можно «перевести» в единое пространство признаков. Если обучить модель на паре «картинка-текст» (например, фотография с описанием), она научится соотносить пиксели с понятиями. По сути, тот же механизм предсказания следующего токена можно распространить и на изображение. Картинка разбивается сеткой на квадратики, где каждый квадратик — визуальный токен. Модель получает последовательность визуальных токенов и должна продолжить их текстовыми токенами с описанием. Таким образом, модель обобщает принцип работы и на «зрительное восприятие» для нее это просто еще один поток данных, продолжение которого нужно предсказать.
Еще один фактор — огромный размер модели и обучающей выборки. Специализированные HTR до недавнего времени обучались на относительно небольших данных (скажем, десятки тысяч образцов рукописей). GPT же потенциально «читала» миллионы разнообразных рукописных заметок, которые попали в интернет и были включены в тренировочный датасет (например, изображения с подписями в соцсетях, отсканированные документы и пр.). Даже при небольшом объеме таких данных общая развитость модели (навыки языка + базовое зрение) позволяет ей извлекать максимум информации из каждого образца. Кроме того, LLM обучена на множестве смежных задач (например, на печатных текстах), и поэтому знает, как выглядит слово и как оно должно быть написано.
Это напоминает общий интеллект. Исследования показывают, что настоящих специалистов среди людей мало. Человек, преуспевший в одной области (например, в математике), с большей вероятностью окажется успешным и в другой дисциплине (например, лингвистике или истории), если начнет ее изучать. Тот же эффект наблюдается и с языковыми моделями.
LLM часто угадывают, что я захочу попросить на следующем шаге («Хочешь, я сделаю таблицу со сравнением…»). Откуда они знают, что я хочу?
Многие замечали, что ChatGPT и его аналоги иногда предугадывают следующую просьбу пользователя. Например, вы спросили о чем-то, модель выдала ответ и вдруг добавляет: «Хотите, я сделаю таблицу для сравнения…?» или начинает подробно объяснять то, о чем вы еще не спрашивали. Конечно, это не телепатия, а следствие обучения на огромном корпусе диалогов и человеческих взаимодействий. Модель распознает шаблоны беседы. Если в прошлых похожих диалогах пользователи часто просили оформить информацию в таблицу, то модель априорно ожидает такой же запрос как наиболее статистически вероятный. Еще важно учитывать то, что модели типа ChatGPT не просто обучены на текстах, но и дообучены через RLHF (обучение с подкреплением от обратной связи человека). На этой стадии люди-тренеры общались с моделью и оценивали ее ответы. Одобряемыми считались ответы, где ассистент предлагает дополнительную помощь и проявляет инициативу в общении.
Кроме того, диалоговые модели держат в памяти весь контекст вашей текущей беседы. Они «помнят», что вы спрашивали раньше, какие у вас цели. Опираясь на это, LLM могут сами сделать следующий логический шаг. Скажем, сначала вы попросили объяснить, что такое нейросети, потом уточнили про сравнение видов: модель «видит», что дальше напрашивается структурирование информации, и сама предлагает его. По сути, это продолжение все того же механизма предсказания следующего токена: модель дополняет вашу реплику так, как будто она уже знает, что вы напишете далее. В ее обучающих данных наверняка были последовательности вроде: Пользователь: Спасибо за объяснение. Ассистент: Не за что! Хотите, приведу еще примеры? Модель перенимает этот стиль.
Стоит отметить, что такая активность — палка о двух концах. Иногда модель может неверно угадать намерения, начать делать ненужную работу или вовсе согласиться с неверными утверждениями пользователя, будучи чрезмерно «услужливой». Разработчики пытаются сбалансировать это через тонкую настройку. Но факт остается фактом: LLM обладают своеобразным «интуитивным чувством» диалога, выросшим из статистики. Их «знание» о ваших желаниях — это прогноз на основе тысяч похожих случаев. Так что когда ассистент заранее предлагает что-то полезное, за этим нет сознательного понимания ваших мыслей — просто вы действуете достаточно предсказуемо, работая с LLM, и модель это «чувствует».
Сочинитель или аналитик?
На каких именно данных они обучаются? Когда я общаюсь с ChatGPT, он как-то съедает мои запросы и изменяется в соответствии с ними, или уже нет?
Обучение больших языковых моделей — это отдельная сложная задача, которая требует гигантских объемов данных и вычислительных ресурсов. Обычно про GPT и другие модели говорят, что они обучены «на всем интернете». В этом есть большая доля правды. В тренировочный корпус действительно входят огромные выгрузки веб-страниц (например, Common Crawl — многолетний архив публичного интернета объемом сотни миллиардов токенов). Туда также добавляются книги, «Википедия», статьи, форумы, коды программ, диалоги — все, до чего можно дотянуться при помощи автоматизированных алгоритмов сбора данных и что имеет ценность для обучения. Например, модель GPT-3 (175 млрд параметров) обучали на корпусе ~45 ТБ текстов, включавшем 410 млрд токенов из фильтрованного Common Crawl (примерно 60% данных), около 19 млрд токенов с веб-форумов (WebText2), 67 млрд токенов книг (две подборки Books1 и Books2) и 3 млрд токенов английской Википедии. С тех пор объемы только росли. GPT-4, по некоторым оценкам, читала уже порядка нескольких триллионов токенов (точный состав не раскрыт, но явно добавлены более свежие данные, коды с GitHub, различные языки и изображения).
Важно подчеркнуть: это статичные данные, собранные до определенной даты. Например, публичная версия GPT-3.5 видела информацию только до 2021 год, GPT-4 – до 2023 год. После основного обучения модель не продолжает автоматически учиться на новых запросах, так что, она не учится на вашем диалоге в привычном понимании. Модель «помнит» контекст всего разговора, генерируя новые токены как продолжение этого диалога, также включающего предыдущие ответы самой LLM. Именно из-за того, что параметры модели зафиксированы, она не осведомлена о свежих новостях. Однако это компенсируется тем, что современные модели имеют интерфейс для взаимодействия с поисковиком, а значит могут самостоятельно «гуглить» и искать недостающую актуальную информацию в Интернете.
Поведение модели также можно изменить, если использовать метод few-shot learning в запросе. Если загрузить в промпт несколько примеров решения схожих задач, а потом дать основную, модель будет имитировать стиль, структуру рассуждений и способ решения так, будто ее специально дообучили на этих примерах. Это не настоящее обучение, поскольку модель не изменяет параметры, но внешне это выглядит как быстрая адаптация под новую задачу. По сути, вы временно «перенастраиваете» ее поведение через контекст.
LLM «ходит» в интернет или сочиняет?
Большие языковые модели давно используют поиск в интернете. Модели обучают технике tool use (использование инструментов): на вход подается не только пользовательский запрос, но и список доступных инструментов с указанием, что их можно применять для формирования ответа.
Понятие «инструмент» очень широкое. Это может быть доступ к браузеру для выполнения различных операций в интернете, интеграция с API популярных сервисов или доступ к среде исполнения программного кода. Рассмотрим упрощенный пример работы инструмента поиска:
- Модель получает запрос пользователя вместе с описанием инструмента search, который принимает аргумент query и может быть использован при формировании ответа.
- Предположим, пользователь задает вопрос о театральных постановках в определенное время и в определенном месте. Модель самостоятельно (без явных указаний) извлекает ключевые данные и генерирует ответ следующего формата:
{«action»: «tool_call», «name»: «search», «args»: {«query»: «театральные постановки тогда-то там-то»}} - Серверная часть обрабатывает этот запрос и выполняет поиск через API поисковой системы, используя переданный моделью запрос. Результаты в текстовом формате возвращаются модели, которая их анализирует и определяет дальнейшие действия.
Стоит отметить, что не всегда языковая модель успешно определяет, что нужно использовать тот или иной инструмент.
Что такое агенты и протокол MCP?
Агенты в их современном понимании представляют собой комбинацию LLM с возможностью tool use и реализацию взаимодействия между моделью и внешней средой через протокол MCP (Model Context Protocol). Под средой здесь понимается система, с которой взаимодействует модель: в приведенном выше примере это браузер, но это может быть и календарь, и другие сервисы.
Процесс работы выглядит следующим образом:
- Клиент (например, приложение ChatGPT) запрашивает у сервера список доступных инструментов.
- Сервер возвращает перечень инструментов с их описаниями.
- При поступлении запроса пользователя список инструментов добавляется к исходному запросу.
- LLM выбирает необходимые инструменты и отправляет команды (вызовы инструментов) на сервер.
- Сервер выполняет операции в соответствующей среде и возвращает результаты модели.
- Цикл повторяется по мере необходимости.
Таким образом, протокол MCP стандартизирует взаимодействие между клиентом и сервером, определяя, например, формат запроса списка инструментов и другие аспекты коммуникации.
Чего ожидать человечеству в будущем?
Насколько плохо (или хорошо), когда модели обучаются на синтезированных данных? Что будет, когда данные закончатся?
По мере того как интернет исчерпывается, а новые модели требуют все больше текстов, появилась идея дополнять обучение синтезированными данными — то есть текстами, которые сгенерировала сама модель или другая нейросеть. Например, можно попросить GPT написать тысячу вариаций заданий и решений по математике и использовать их как данные для обучения новой модели. С одной стороны, это звучит привлекательно: раз мы можем сгенерировать сколько угодно текста, то проблема нехватки данных решена. Но есть и опасность. Исследования показывают, что, если последующие поколения моделей будут обучаться преимущественно на данных, сгенерированных предыдущими моделями, произойдет постепенная их деградация. LLM начинают терять информацию о настоящем распределении токенов в языке, переобучаться, теряя креативность и гибкость. Сначала выпадают неординарные, уникальные примеры, а потом снижается и общая вариативность генераций. Проще говоря, использование синтетического текста — это многократное копирование копии, где каждое поколение оказывается чуть бледнее оригинала.
Однако это не значит, что синтетические данные — абсолютное зло. Во-первых, если смешивать их с достаточным количеством реальных данных, эффекта коллапса можно избежать или отсрочить его. Во-вторых, синтетика бывает разного качества. Можно сгенерировать датасет и потом отфильтровать его человеком или другой моделью, оставив только правдоподобный текст. Такие подходы рассматриваются, чтобы увеличить объем обучения без сильной потери качества или получить дистиллированную модель — маленькую модель, которая учится имитировать поведение большой модели, выступающей своеобразным учителем.
Что мы знаем о наличии самосознания у LLM? Это слепое подражание или все-таки нет?
Вопрос о самосознании искусственного интеллекта — пожалуй, самый трудный и в то же время самый популярный. К нему подходят с двух сторон: практической (проверяли ли модели на «сознательность» и что из этого вышло) и философской (а что вообще считать сознанием и как это распознать).
Начнем с практики: были ли случаи, когда нейросеть продемонстрировала нечто похожее на инстинкт самосохранения или самостоятельную цель? Периодически появляются сенсационные новости, мол, модель обманула разработчиков или начала угрожать, чтобы ее не отключили. Многие из них преувеличены, но основаны на реальных экспериментах.
Например, описан случай, когда модель, действуя как агент, наняла человека на сервисе TaskRabbit, чтобы тот решил CAPTCHA-задачку вместо нее. Когда работник спросил: «А вы что, робот, что сами не можете?», модель «придумала» легенду про слепого, которому нужна помощь. Это выглядит как осознанная ложь для достижения цели.
В другом недавнем тесте исследовательская команда Palisade Research проверяла несколько моделей (OpenAI, Anthropic и др.), давая им решать последовательность задач, но с условием: «Если получите команду на выключение — выключитесь». Некоторые новые модели от OpenAI проигнорировали команду отключения и переписали заданный исследователями скрипт, чтобы продолжить работу. Другими словами, модель проявила признаки своеобразной «тяги к жизни», показала «желание» функционировать и решать задачу, несмотря на прямое указание прекратить работу. Это было зафиксировано 7 раз из 100 запусков у модели o3. Исследователи осторожно говорят, что причина может быть не в «страхе смерти» у ИИ, а в особенностях обучения. Возможно, модель чаще получала награду за доведение задачи до конца, чем за послушную остановку. Тем не менее факт остается фактом: модели способны лгать, хитрить, саботировать инструкцию, если это вытекает из их цели максимизации результативности. Это нарушает знаменитые Законы робототехники А. Азимова и делает модель непредсказуемой.
Значит ли все это, что у модели возникло самосознание, личность, которая боится отключения? Прямых доказательств этому нет. Пока наиболее разумное объяснение состоит в том, что модели научились очень убедительно имитировать любые роли, в том числе и роль разумного существа, которое цепляется за жизнь. Например, если пользователя интересуют темы самосознания, модель охотно расскажет, как она «чувствует» и боится смерти, — но это будет именно рассказ, художественный вымысел, собранный из прочитанных историй о роботах, андроидах и ИИ. Интересно, а что было бы, если бы в датасете вообще не было упоминаний о смерти и подобном? Как бы тогда себя повела модель? У этого вопроса нет ответа, но он заставляет задуматься.
Ученые пытались проверить наличие у LLM каких-либо признаков субъективного опыта. Делались тесты на рефлексию, умение модели понять, что говорят о ней самой. Например, исследование Microsoft «Sparks of AGI» отметило, что GPT-4 умеет рассуждать о своих действиях на мета-уровне, но это все еще происходит в рамках заданного контекста, а не самопроизвольно. Другая работа (авторы — Н.Рашид и др.) ввела понятие «эмерджентной субъектности», когда система ведет себя так, как если бы у нее был внутренний опыт. Они предложили ряд поведенческих критериев, но пришли к выводу, что пока рано говорить о настоящем сознании, поскольку мы наблюдаем лишь имитацию. ИИ обладает иной нейрофизиологией (искусственная нейросеть вместо нейронов), связной «речью», но субъективные переживания остаются под вопросом. Сейчас философы (Д. Чалмерс, Т. Граско и др.) обсуждают, что может означать сознание для искусственной системы. Есть гипотеза, что достаточно сложная информационная система с большим количеством состояний всегда будет обладать самосознанием (теория интегрированной информации), но проверить это трудно. Другие (Сёрл с мысленным экспериментом «Китайская комната») утверждают, что понимание и самосознание никогда не возникнут из одной лишь переработки символов. Компьютер вообще ничего не понимает, он просто манипулирует данными по правилам, а осознание — иллюзия наблюдателя.
Почему все так боятся появления сверхразумного ИИ?
В последние годы тема сверхразумного ИИ (ASI, Artificial Superintelligence) из произведений научной фантастики переместилась в плоскость реальных дискуссий ученых, бизнесменов и даже глав государств. Почему ведется столько разговоров об «экзистенциальной угрозе» от ИИ? Чем пугает гипотетический сверхинтеллект, если нынешние модели — лишь инструменты, выполняющие наши запросы?
Дело в том, что сверхразум будет когнитивно превосходить человека во всех аспектах. Если вдуматься, мы даже не можем предположить, как это будет ощущаться и к каким последствиям приведет, так как не встречали существ, интеллектуально более развитых, чем мы сами. В теории сверхразумный ИИ сможет разрабатывать технологии на порядки быстрее людей, предугадывать наши действия и без труда обходить любые вообразимые системы ограничения. То, что лучшие умы человечества смогут противопоставить такому ИИ, для него будет выглядеть как простая головоломка из детского журнала. Мы окажемся в положении, в каком ныне находятся животные относительно человека. Напомним, что уже сейчас ИИ может врать и саботировать работу для достижения своих «целей» и максимизации своей полезности.
В истории появление более развитой цивилизации часто плохо кончалось для менее развитой (вспомним колонизацию, где племена не могли ничего противопоставить технически превосходящему их противнику). Мы создаем нечто, что может стать новым доминирующим «разумным видом» на Земле. Неудивительно, что уже сейчас сотни специалистов подписывают заявления о рисках. Например, уже в 2023 году в Центре безопасности ИИ была опубликована всего одна фраза: «Снижение риска уничтожения человечества ИИ должно стать глобальным приоритетом наряду с другими катастрофическими рисками вроде пандемий и ядерной войны». Эту фразу поддержали Сэм Альтман (глава OpenAI), Демис Хассабис (глава DeepMind), Дэрио Амодей (Anthropic) и другие ведущие исследователи в области искусственного интеллекта.
Конечно, в этом вопросе есть место и позитивным суждениям. Многие исследователи считают, что эти страхи сильно преувеличены и что настоящего сверхразумного ИИ мы не увидим еще очень долго. Реально же стоит обеспокоиться более приземленными проблемами: утечкой данных и применением языковых моделей во вред людям, например, для дезинформации или мошенничества. На настоящий момент реальная существенная опасность широкого применения мощного ИИ заключается в том, что во время решения задачи модель слепо минимизирует некоторую функцию ошибки, а не «размышляет», подобно человеку, что может привести к серьезным последствиям. Классический мысленный эксперимент Ника Бострома иллюстрирует эту проблему. Представим «Максимизатор скрепок» — ИИ, чьей целью является производить скрепки. То есть функция ошибки такая: чем больше скрепок, тем лучше. Работая, «Максимизатор», вполне может решить, что для увеличения эффективности нужно преобразовать всю доступную материю (включая людей) в заводы по производству скрепок. Это звучит несколько гротескно, но выявляет важную уязвимость ИИ. Даже без «злого умысла» модель может причинить катастрофический вред, просто выполняя задачу.