Языковая модель: от Т9 до GPT
Необязательно заходить на сайт OpenAI, чтобы понять на практике, что такое языковая модель — на самом деле, мы сталкиваемся с ее работой каждый день. Каждый раз, когда мы вводим что-то с помощью клавиатуры смартфона, языковая модель предлагает нам следующее слово или, говоря научно, моделирует наш язык.
Большие нейросети вроде GPT, умеющие поддерживать диалог, решать математические и логические задачи, писать код и многое другое, не так уж сильно отличаются от обычной телефонной клавиатуры: они также предсказывают наиболее вероятное слово на основе предыдущих. Главное отличие — они делает это намного точнее.
Задача предсказания следующего слова не так проста, как кажется. Для того, чтобы научить компьютер решать эту задачу, нужно понять, какие предсказания мы хотели бы получать от него.
Например, если попросить завершить известную фразу «Мама мыла …», то наверняка многие ответят — «раму». То есть для большой группы людей правильным продолжением фразы является именно слово «рама» Возможно, они часто слышали эту фразу в детстве и поэтому ответили именно так, но совершенно точно найдутся люди, которым такое продолжение не покажется «естественным» и которые предпочтут другие варианты. В этом и заключается одна из сложностей задачи предсказания слова по контексту (задачи моделирования языка): нет единого правильного ответа (предсказания) для конкретного контекста. Однако есть более вероятные и менее вероятные ответы.
Допустим, мы соберем все тексты, написанные на русском языке, в которых есть фраза «Мама мыла», затем посчитаем, сколько раз слово «раму» встречается после неё и сделаем аналогичные подсчеты для слова «малыша», — если окажется, что слово «раму» встречается чаще (к примеру, в 40% текстах, а слово «малыш» — в 25%), то это и будет означать, что оно более вероятно, чем продолжение «малыша».
Значит, мы хотим, чтобы компьютер всегда продолжат фразу наиболее вероятным вариантом? Скорее всего, нет. Представим, что компьютер умеет это делать — тогда мы можем попробовать сгенерировать текст с началом «Мама мыла» словом за слово: подать наше начало, попросить предсказать следующее слово, затем уже по трём словам предсказать следующее и так далее. Поскольку компьютер выдаёт всегда наиболее вероятное слово, то наш сгенерированный текст всегда будет начинаться со слов «Мама мыла раму». Другими словами, компьютер будет генерировать однообразные тексты. Более корректно было бы получать в 40% от компьютера тексты, начинающиеся с «Мама мыла раму», в 25% — с «Мама мыла малыша», в n% — c «Мама мыла посуду» и так далее. То есть хочется, чтобы компьютер выдавал конкретное слово в качестве предсказания с той же частотой, с какой это слово встречается в данном контексте в языке.
Подытожим: языковая модель — это компьютерная программа, которая по контексту вычисляет для каждого слова языка вероятность того, что это слово встретится в этом контексте. Поскольку слов в языке может быть очень много, то модель учат вычислять вероятности только для слов словаря — относительно небольшого набора слов или частей слов в языке.
Чем отличаются разные языковые модели: примеры
Учиться моделировать язык можно разными способами. Существует два принципиально разных подхода:
- каузальное моделирование (Causal Language Modeling),
- моделирование путем восстановления исходного текста по его «искаженной» версии (Masked Language Modeling и UL2).
В первом подходе модель должна предсказать следующее слово по предыдущим — то есть текст моделируется последовательно, слово за словом. К таким моделям, например, относятся все модели семейства GPT, а также модель PaLM. Модели, обученные решать такую задачу, способны генерировать тексты.
Во втором подходе исходный текст модифицируется определённым образом — например, часть слов заменяется на специальное слово «[MASK]». Задача модели предсказать, какие слова были заменены на «[MASK]». Модели, обученные под эту задачу, не подходят для генерации текстов, однако способны извлекать качественные векторные представления текстов и слов. Примеры таких моделей: BERT, T5.
Задача первого подхода сложнее задачи второго, поэтому для обучения модели необходимо больше данных.
Многофункциональность языковых моделей: текст как универсальный интерфейс
Почему именно языковые модели стали главными претендентами на роль сильного искусственного интеллекта (ИИ как в научно-фантастических фильмах и рассказах)? Всё дело в универсальности текстового представления информации. Текстом можно описать широкий спектр задач.
Вот несколько примеров пар «задача — ее текстовое описание», чтобы это увидеть:
| Задача | Текстовое описание | Пример |
| Перевод с одного языка на другой | Слово X на языке L будет … | Слово любовь на французском будет … |
| Математическая/логическая задача | Условие задачи: X. Ответ: | Условие задачи: у Пети было 4 яблока, у Андрея — 3 груши. Сколько было овощей у мальчиков? Ответ: … |
| Написание кода | Код программы X на языке L | Код программы, проверяющей чётность числа, на языке Python |
| Ответы на фактологические вопросы | Текст с началом факта | Алан Тьюринг был … |
Поскольку языковая модель обучалась предсказывать продолжение по контексту, то можно попробовать подать ей на вход задачу в текстовом виде с расчетом, что она выдаст правильный ответ в качестве продолжения.
В исследовании 2020 года было показано, что, если обучить большую языковую модель на большом корпусе текстов, то модель приобретает способность решать самые разные задачи, включая приведенные выше.
- Постановка, в которой модель решает задачу, на которую она не обучалась, называется Zero-Shot Learning.
- Есть и постановка Few-Shot (in-context) Learning, при которой модели «показывают» всего несколько обучающих примеров. При такой постановке запрос на перевод «Слово X на языке L будет …» преобразуется в запрос вида: «Слово s1 на языке L будет t1, s2 — t2, а слово X будет». Например, «Слово собака на французском языке будет chien, птица — oiseau, а слово кошка будет …». Почти всегда демонстрация модели нескольких обучающих примеров повышает качество ее ответа.
- Помимо этого модель можно «заставить» использовать свои же промежуточные размышления при решении задачи. Мы подробно рассказывали про механизм «рассуждений» у языковых моделей в нашем материале.
Как получить оптимальную языковую модель: Scaling Laws
Качество языковой модели зависит от нескольких факторов:
- размера модели
- размера обучающей выборки
- количества вычислительных ресурсов, доступных для обучения модели
Про размер модели и обучающую выборку мы рассказывали в наших материалах про машинное и глубинное обучение.
Допустим, перед нами стоит задача обучить языковую модель размера с GPT-1 — это примерно 117 миллионов параметров. Сколько нужно текстов в обучающей выборке, чтобы получить модель с определенным уровнем ошибки? Несколько сотен тысяч, миллион, миллиард?
Самый наивный ответ — попробовать все варианты и посмотреть на результаты. Обучение языковой модели, как и других нейросетевых моделей, ресурсозатратно и требует времени, поэтому простой перебор всех вариантов нерационален.
Другой возможный ответ — чем больше обучающих данных, тем лучше. Этот ответ неверен, поскольку модель определённого размера может «извлечь пользу» из выборки ограниченного размера. Может получиться, что увеличение выборки не даст никакого прироста в качестве модели. Поэтому увеличение выборки с какого-то момента приведет лишь к бесполезной трате ресурсов на обучение.
Теперь обратная задача: предположим, что у нас есть выборка фиксированного размера. Какого размера должны быть языковая модель, чтобы она смогла, обучаясь на этой выборке, достичь определенного качества предсказаний?
Диапазон размеров модели огромен, поэтому перебор опять не решает проблему. Брать самую большую модель не всегда правильно. Это может привести к ситуации, когда модель идеально работает с примерами из обучающей выборки, но плохо — с остальными данными. Такое явление называется «переобучением».
Для того, чтобы не тратить огромное количество времени на перебор возможных комбинаций, исследователи изучили зависимость качества моделей (это были языковые модели с архитектурой Transformer) от:
- размера модели
- размера обучающей выборки
- количества доступных вычислительных ресурсов
Для этого фиксировались два из трёх перечисленных параметров, но варьировался третий. Таким образом исследователи получали множество комбинаций, зависящих только от одного параметра. Далее для каждой такой комбинации обучалась модель, и в конце обучения каждой модели производился замер её ошибки. В этом случае получалась выборка из пар вида «значение варьируемого параметра; ошибка модели, которая обучалась с такой комбинацией параметров». Вот как это выглядит на примере (далее K — тысяча, M — миллион):
- Из трех параметров мы зафиксируем размер выборки (она состоит из 1M текстов небольшой длины) и количество ресурсов для обучения (2 дня обучения на относительно мощном компьютере), а варьировать будем размер модели.
- В этом случае выявляем, как размер модели влияет на ее качество — при фиксированном размере выборки и фиксированном количество доступных ресурсов. В качестве размера модели будем перебирать следующие значения: 100K, 1M, 10M и 100M параметров, то есть будем обучать 4 разных по размеру модели на одной и той же выборке в течение одного и того же времени.
- В конце обучения каждой модели произведем замер её ошибки.
Как итог получаем четыре пары:
- 100K, ошибка модели размера 100K,
- 1M, ошибка модели размера 1M,
- 10M, ошибка модели размера 10M,
- 100M, ошибка модели размера 100M.
Получив эти результаты, нужно понять общую зависимость. Зависимость в математике выражается с помощью понятия функции — уравнения, в котором один показатель выражается через один или несколько других показателей. По графику функции можно часто угадать тип зависимости.
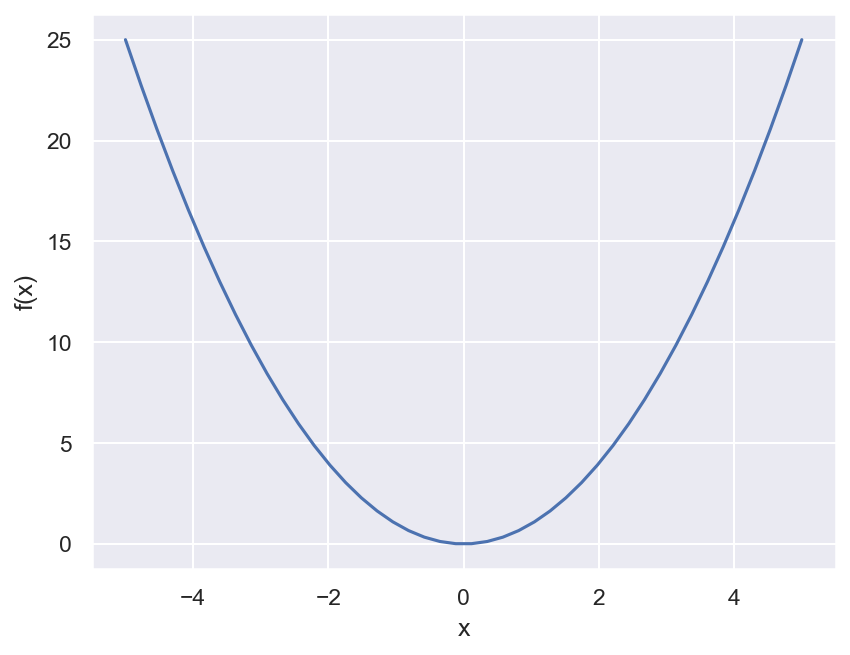
Оказывается, что если изобразить на графике пары значений, полученные в результате обучений моделей, то получится график степенной функции — функции вида f(x) = kxa, где k и a — параметры функции.
Например, зависимость ошибки модели (L) от ее размера выражается функцией L(N) = (Nc / N)aN, где Nc, aN — конкретные числа.
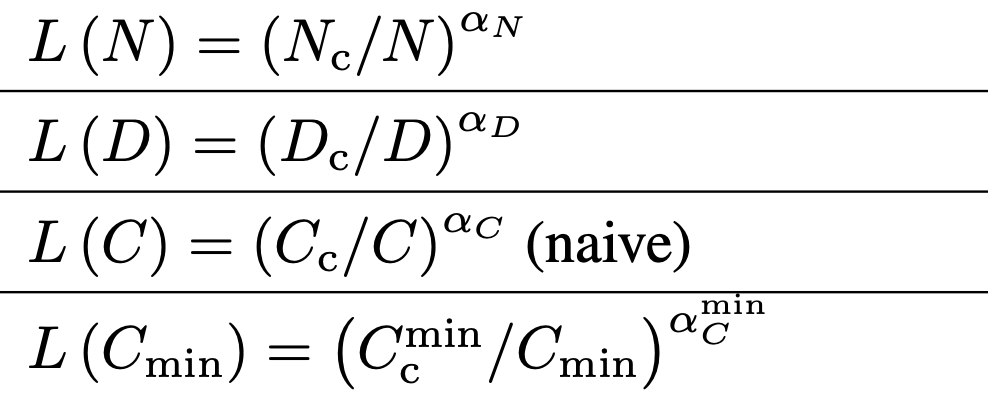
Зависимость ошибки модели (L) от размера модели (N), от размера обучающей выборки (D) и от количества вычислений (C и Cmin).
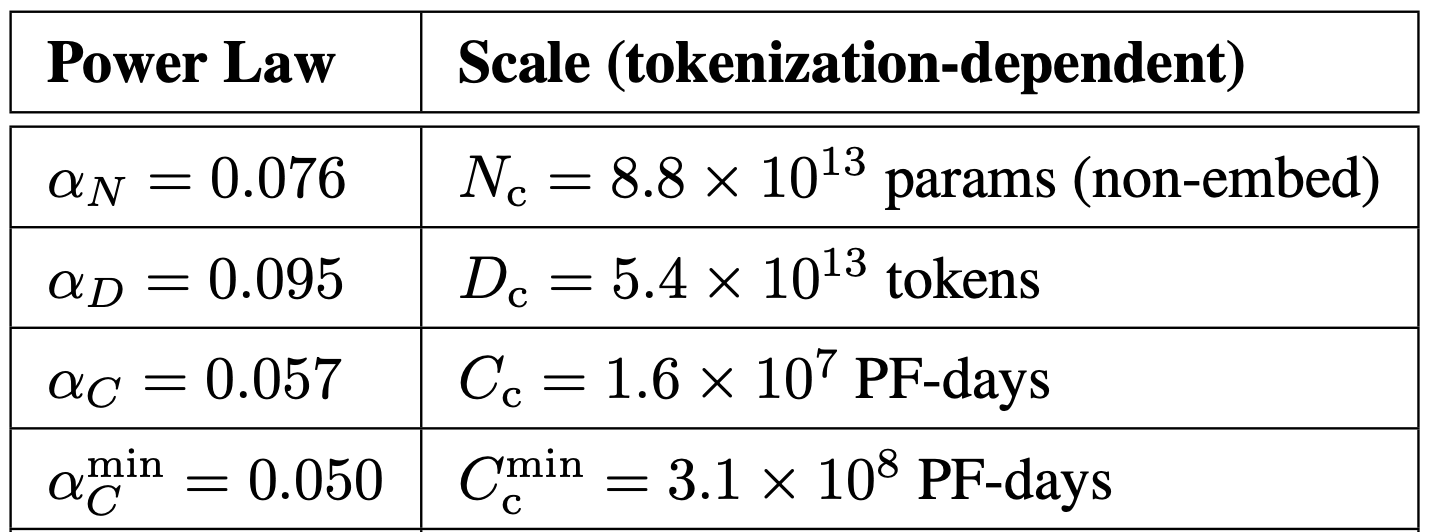
Конкретные параметры функций L(N), L(D), L(C), L(C_min). Они были подобраны таким образом, чтобы лучше всего моделировать результаты обучения моделей
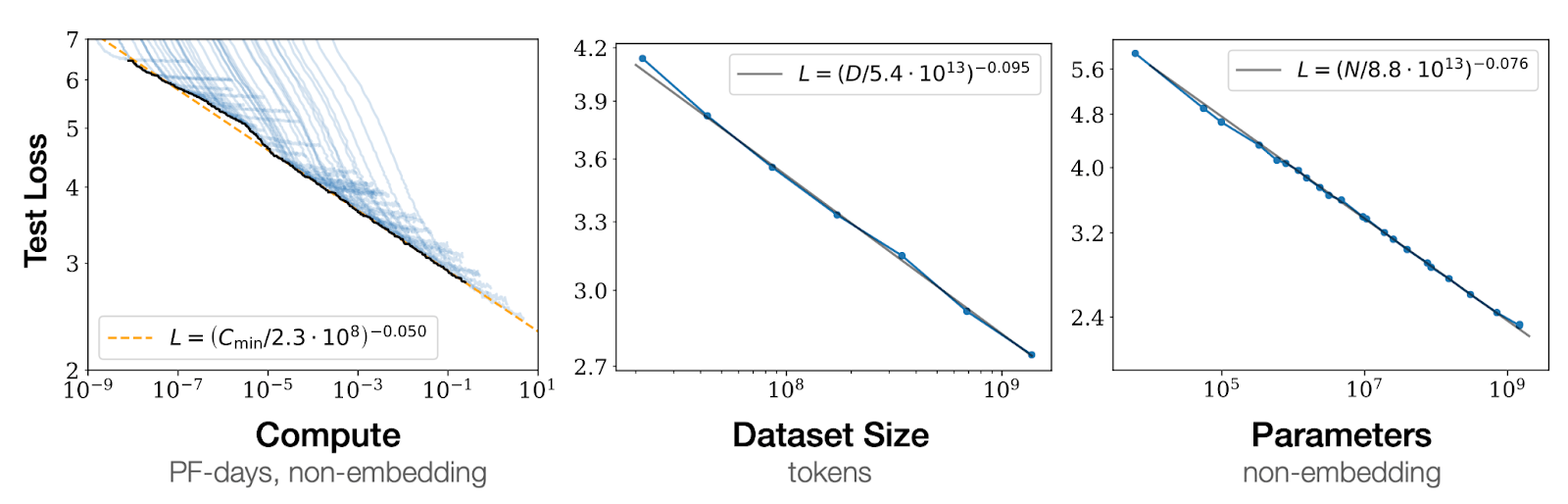
Все эти функции называются «Scaling Laws» — законы по которым меняется качество (ошибка) модели в зависимости от масштабирования разных факторов обучения. Зная конкретный вид зависимости ошибки от каждого из трех параметров, можно без обучения предсказать ошибку, которая будет достигнута после обучения модели с конкретным значением параметра.
Это существенно сокращает время на эксперименты и позволяет разумно тратить ресурсы. Еще несколько важных выводов из этого исследования:
- Большие модели более эффективны с точки зрения данных: для достижения определённого уровня ошибки большой модели потребуется меньше данных и меньше шагов обучения, чем маленькой.
- Если масштабировать и размер модели, и количество обучающих данных, то можно увидеть предсказуемый рост качества модели. Если зафиксировать один из этих параметров, то качество модели с какого-то момента перестает расти.
- Качество модели при фиксированном количестве параметров практически не зависит от ее глубины и ширины.
Источники
Kaplan, J., McCandlish, S., Henighan, T., Brown, T. B., Chess, B., Child, R., … & Amodei, D. (2020). Scaling laws for neural language models. arXiv preprint arXiv:2001.08361.
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., … & Amodei, D. (2020). Language models are few-shot learners. Advances in neural information processing systems, 33, 1877-1901.