Первый шаг в обработке текста — это токенизация. На этом этапе происходит разделение текста на более мелкие единицы — на предложения и слова. Затем обычно создается словарь, в который заносятся уникальные лексемы, встретившиеся в корпусе или тексте. На этих этапах ученые сталкиваются с несколькими проблемами.
Проблема 1: языки с богатой морфологией
Это языки с развитыми системами склонений и спряжений слов. При работе с текстами на этих языках сложность возникает при составлении словаря, когда нужно найти и объединить все словоформы одной и той же лексемы.
Пример — русский язык, в котором есть падежи. При переводе слова в векторное пространство нужно учитывать, что стол, столу и столом — это одно слово в разных падежных формах, а не 3 уникальных лексемы. Чтобы решить эту задачу, текст можно предварительно лемматизировать, или применить стемминг (от английского stem — стебель), то есть просто отрезать у слов окончания.
Проблема 2: языки с продуктивным сложением основ
В германских языках (в английском, немецком, шведском и т.д.) очень продуктивно образуются новые сложные слова. Значения таких слов выводятся из значения их элементов, их можно создавать бесконечно долго, и большинство из них не зафиксировано в «бумажном» словаре.

При работе с этими языками сложность также возникает на этапе составления словаря. При составлении словаря модели ориентируются на частотность (например, сохраняем слово, если оно встретилось чаще пяти раз), поэтому не будут запоминать такое длинное и сложное слово.
Проблема 3: определение границ слова
Современные лингвисты до сих пор не могут придумать универсальное определение понятию слово и в каждой конкретной ситуации объясняют его по-разному. Для нас, привыкших к языкам европейского типа, слово — это набор букв между пробелами и знаками препинания. По таким разделителям компьютер тоже может легко найти слово.
Но в английском языке многие сложные слова пишутся раздельно, я в японском, наоборот, между словами вообще нет пробелов. Поэтому универсальный токенизатор создать было нелегко.
Решение — Byte Pair Encoding
Первый настоящий прорыв в этом направлении был сделан исследователями из Эдинбургского университета. Они создали подслова в нейронном машинном переводе, используя алгоритм BPE — Byte Pair Encoding.
Изначально BPE был представлен как простой алгоритм сжатия данных без потерь. В феврале 1994 года Филипп Гейдж в статье «Новый алгоритм сжатия данных» описал метод, который работает так: самые частотные пары символов заменяются на другой символ, который не встречается в данных, при этом объем используемой памяти снижается с двух байт до одного.
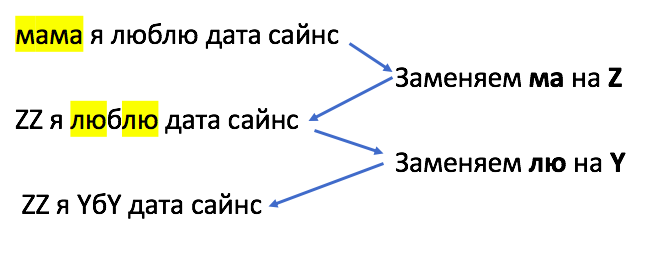
Для задач NLP алгоритм BPE был немного изменен: часто встречающиеся группы символов не заменяются на другой символ, а объединяются в токен и добавляются в словарь. Алгоритм токенизации на основе BPE позволяет моделям узнавать как можно больше слов при ограниченном объеме словаря и выглядит так:
Шаг 0. Создаем словарь.
Шаг 1. Представляем слова из текста как списки букв.
Шаг 2. Считаем количество вхождений каждой пары букв.
Шаг 3. Объединяем самые частотные в токен и добавляем в словарь.
Шаг 4. Повторяем шаг 3 до тех пор, пока не получим словарь заданного размера.
Сегодня схемы токенизации подслов стали нормой в самых продвинутых моделях, включая очень популярное семейство контекстных моделей, таких как BERT, GPT-2, RoBERTa и т. д.
Модификации BPE
Чтобы решить задачи голосового поиска на японском и корейском языках сотрудниками Google модифицировали Byte Pair Encoding и создали токенизатор WordPiece. Основная идея остается прежней: мы разбиваем слова на буквы и объединяем символы попарно. Однако в словарь добавляются не самые частотные пары, а пары, максимально увеличивающие вероятность на данных для обучения.
Продолжением работы в этом направлении стал токенизатор SentencePiece, который, помимо BPE, использует алгоритм Unigram Language Model.
Источники
- Статья на Медиуме, которая легла в основу нашей статьи
- Статья создателей WordPiece
- GitHub создателей SentencePiece



