Гордость и предубеждение и тесты
В 2025 году книжное сообщество «Смысловая 226» запустило спецпроект к 250-летию Джейн Остен (посмотреть на него можно здесь). Создатели проекта хотели взглянуть на творчество писательницы с разных сторон: рассказать о биографии, показать, интересно ли её творчество читателям-мужчинам, проанализировать, как книги Остен повлияли на будущие поколения авторов романтических сюжетов.
Помимо классических литературоведческих статей, в проект решили добавить и другие форматы — например, на сайте можно посмотреть видео “Мужчины пересказывают «Гордость и предубеждение»”. Нужен был и игровой материал — и его предложили сделать автору этой статьи — проанализировать книги Остен при помощи цифровых гуманитарных методов и подготовить тест на основе этого анализа.

На начальном этапе я перечитала пару романов Остен, просмотрела немалое количество развлекательных материалов про книги писательницы на английском («Кто вы из Нортенгерского аббатства?», «Расположите события романов на временной шкале», «Знаете ли вы значения этих слов?») и показала редакторам проекта, что можно исследовать с помощью популярных DH-инструментов (например, сделать облако слов, по которому можно угадать роман, или посмотреть в каких главах «Гордости и предубеждения» есть слова «гордость» и «предубеждение»). К сожалению, тесты-референсы часто либо требовали прямого знания романов Остен, либо превращались в чистую угадайку.
Конечно, всё ещё можно было поиграть в «угадай по ключевым словам» или «сравниваем слова мистера Дарси и Генри Тилни», но эти идеи казались довольно скучными… И тут главный редактор онлайн-журнала «Смысловая 226» Анастасия Завозова предложила сравнивать книги Остен с книгами Джулии Куин о Бриджертонах — и идея теста заиграла по-новому.
Как сравнить Бриджертонов и Остен?
Идея сравнить Бриджертонов и Остен показалась мне блестящей. Во-первых, вышедший в 2020 году сериал (в 2026-м Netflix выпустил уже четвёртый сезон) вдохнул в книги нулевых новую жизнь — и привлёк внимание огромной аудитории зрительниц. Во-вторых, на известные современные романы про эпоху Регентства Остен не могла не повлиять, и при желании в книгах писательниц можно было найти как сходства, так и различия.
Правда, для того, чтобы тест был интересен читателям, нужно было сделать так, чтобы они могли действительно логически думать во время его прохождения, а не нажимать на случайный вариант.
А значит, нужно было пройти между двумя вариантами, которые я условно назову здесь «Сцилла стилометрии» и «Харибда очевидности».
Сцилла стилометрии
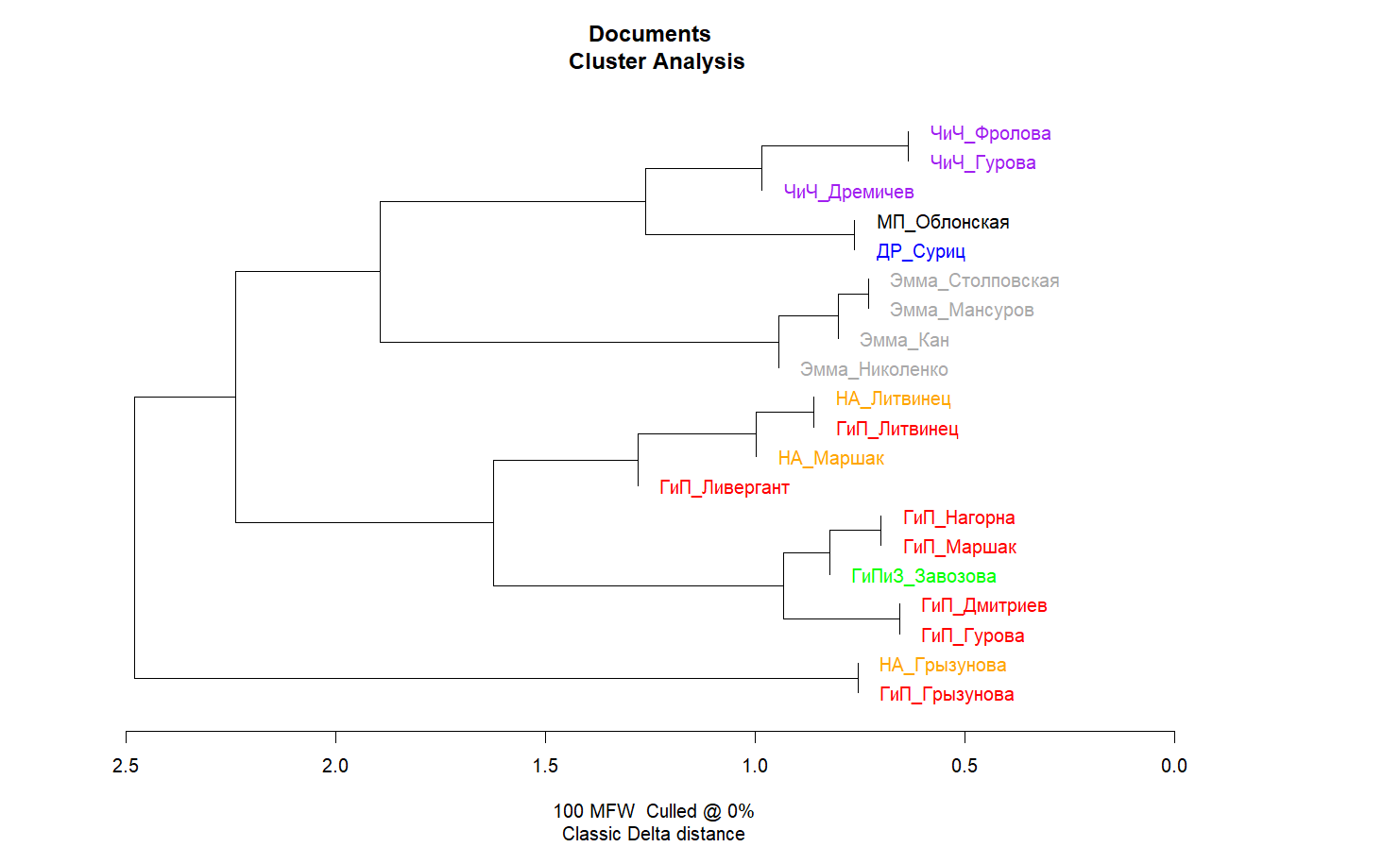
Любой человек, так или иначе имевший дело с цифровой филологией, узнает про стилометрию довольно быстро — слишком знаменит метод, с помощью которого, например, доказывают, что «Тихий Дон» действительно написал Шолохов, а под псевдонимом Роберта Гэлбрейта скрывается Джоан Роулинг.
Знаменит, и, увы, практически бесполезен для сравнения Бриджертонов и Остен. Если посмотреть на то, какие различия стилометрия анализирует в первую очередь, мы увидим мелочи, невидимые человеческому глазу. Глазами мы замечаем злоупотребление словами «восхитительный» или «промолвил», а вот понять, что один автор чаще использует слова «чтобы», «но» или «про», чем другой, не так-то просто. На стилометрический анализ влияет именно это.
Стилометрия в её классическом виде при анализе книг Остен и Куин, конечно, сработает и позволит легко отличить одну писательницу от другой (а для Остен — даже переводчиков).
Но только представьте вопросы для теста.
Какая писательница в своих книгах чаще использовала предлог «на»?
Не очень увлекательно, если честно. Да и след перевода слишком значим, чтобы совсем его не учитывать — а книги анализировались всё же на русском. Значит, нужно работать со значимыми словами — причём теми, которые как минимум не будут совсем потеряны в переводе. Например, в случае с «лошадьми» можно верить, что достаточно посчитать «лошадей» и «коней» для понимания общей картины в развлекательном формате, а вот у какого-нибудь «сказал» вариантов будет гораздо больше.
Харибда очевидности
Если взглянуть на самые «значимые» для двух текстов слова, опираясь, например, на Voyant Tools, топ-10 будет практически полностью состоять из одного и того же: имена собственные, имена собственные и ещё раз имена собственные. Вряд ли кого-то удивит, что слово «Вайолет», имя матери семейства из книг про Бриджертонов, гораздо чаще будет встречаться у Куин, чем у Остен.

К этим же словам относятся и другие, напрямую связанные с сюжетом произведения: никого не удивит частотность слова «аббатство» в романе «Нортенгерское аббатство» или слова «виконт» в романе «Виконт, который любил меня». Впрочем, какие-то из таких слов можно и оставить, например, чтобы порадовать знатоков текстов — главное, чтобы всё ещё было над чем поразмыслить.
Компромисс: ищем ключевые слова сами с TF-IDF
Таким образом, оказалось, что даже при использовании методов дальнего чтения пристальное чтение неизбежно. Понять, что действительно отличает атмосферу книг друг от друга и что из этого можно поймать, оказалось возможным только погрузившись в эту атмосферу.
Параллельно я пробовала экспериментировать и с классическими методами анализа ключевых слов — например, с TF-IDF — но анализ «руками» в Python практически ничего не поменял по сравнению с автоматикой Voyant Tools. Даже предобработка — токенизация («Виконт, который меня любил» превращается в [«виконт», «который», «меня», «любил»]), лемматизация ([«виконт», «который», «я», «любить»]), работа со стоп-словами (остаётся [«виконт», «любить»]) — изменила мало что.
Впрочем, этот этап подарил несколько забавных блуперсов: знаете, как pymorphy2 лемматизировал слово «Вайолет»? Вайогод.

Уже после того, как в стоп-слова вошли имена, топонимы и прочие приметы конкретных книг, на переднем плане оказались особенности стиля переводчика. Каждый по-своему выбирал слова, решая задачу темпоральной стилизации — то есть передачи английского языка прошлого таким образом, чтобы он казался естественным современному читателю. Если состарить Остен «под Карамзина», текст будет казаться странным, но и совсем современным перевод сделать нельзя. В текстах некоторых переводчиков чаще встречалось «ныне», кто-то заменял «мистера» на «господина», кто-то использовал «промолвил» вместо «сказал». Такие стилистические различия, конечно, интересны, но для основной задачи сравнения Остен и Куин бесполезны.


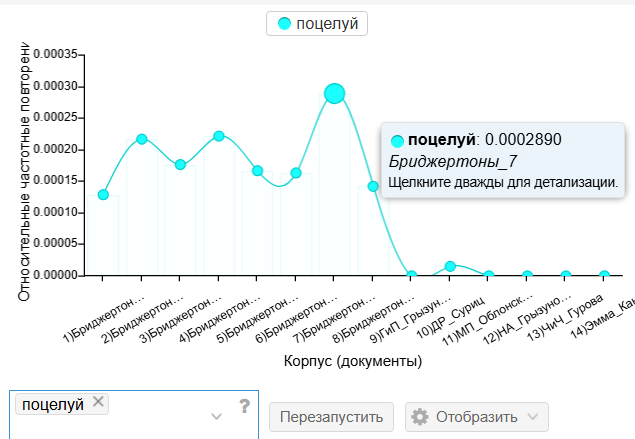
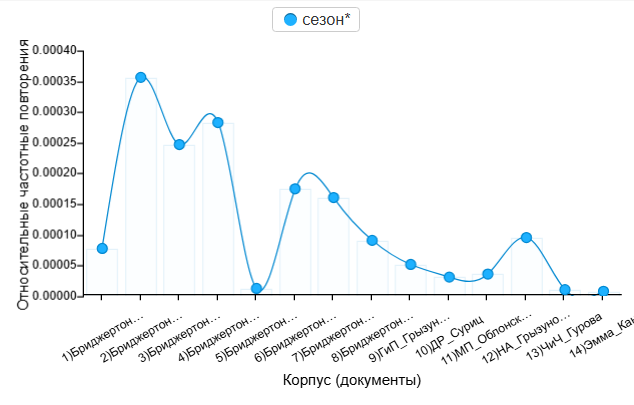
Поэтому пришлось заниматься некоторым брутфорсом: проверять список из пары десятков слов, которые, на мой взгляд, были так или иначе стереотипными и яркими. Среди них были, например, романтические клише (поцелуи, флирт, обмороки), различные жесты ухаживаний (танцы, балы, цветы), сезонные приметы (сезон, осень, зима), еда и другие «слова-хештеги», которые не столько выявляют скрытый индивидуальный стиль автора, сколько говорят о более очевидных темах произведения.
Проверить частотность тех или иных слов на этом этапе можно при помощи уже упомянутого Voyant Tools, даже не занимаясь предобработкой текста: все выглядит достаточно наглядно. Из-за того что текст не был лемматизирован, на этом этапе предварительной проверки гипотез слова проверялись по-разному: например, несклоняемые «кофе» или «корги» я не меняла вообще, а «букет*» или «осен*» проверяла по основе.
Важно отметить, что частотность считалась относительная, а не абсолютная: ведь, например, если слово встречается три раза в рассказе Чехова и пять раз в «Войне и мире» — это еще не значит, что во втором случае оно частотнее.
Если вы хотите пройти тест, не поймав больших спойлеров, самое время пройти его сейчас. Дальше могут попадаться графики и комментарии, так или иначе раскрывающие правильные ответы.
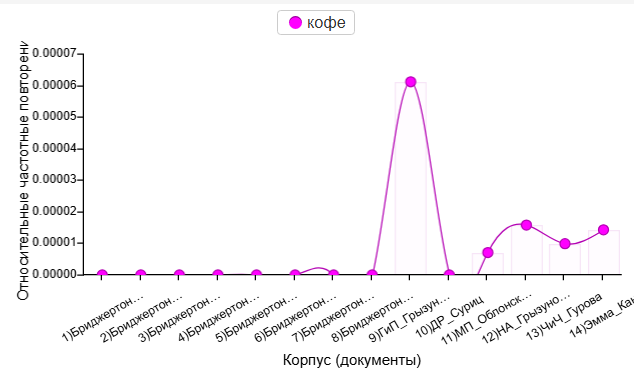
После того, как я проверила список из пары десятков «избранных» слов в Voyant Tools, я отобрала 10 слов, про которые можно было задать вопросы теста. На этом этапе можно было возвращаться к привычным библиотекам Python. Поскольку тексты уже были предобработаны, достаточно было пересчитать относительную частоту слов, в некоторых случаях добавив ещё пару слов для проверки: например, для вопроса про «цветы (цветок)» я посчитала цифры для слова «букет», а для вопроса про лошадей — для слова «конь».
Никаких неприятных новостей на этом этапе не возникло: обновленные подсчеты с помощью питоновских библиотек соответствовали предварительным подсчетам в Voyant Tools.
Блиц: топ-5 любопытных наблюдений
1. Кофе пьют чаще у Остен — для Бриджертонов, оно, возможно, показалось чересчур «хипстерским».
2. Разница в том, как часто в книгах упоминаются лошади, не так велика: но у Куин это обычно напряженные сцены погонь или падений, а у Остен — обычная часть быта: например, героиня может не выехать на прогулку из-за того, что нет спокойной, подходящей женщине лошади.
3. В книгах Куин появляются корги, хотя эта порода стала популярна только в 1930-е. Любимые собаки королевы вписались в мир Бриджертонов хоть анахронично, но органично.

4. Цветы чаще появляются у Куин — возможно, во времена Остен букет цветов не был настолько распространенным романтическим жестом, а вот героинь книг о Бриджертонах порой осыпают цветами.
«— Цветы прислали вам, миледи.
Франческа часто-часто заморгала.
— Мне?
— Именно вам. Не желаете ли прочесть карточки? Я оставил каждую возле соответствующего букета, чтобы вы знали, кто что прислал.
— А! — Это было все, что она смогла вымолвить. Она стояла, прижав ладошку к приоткрывшемуся рту, переводила взгляд с букета на букет и чувствовала себя дурочкой».
(Дж. Куин. Когда он был порочным)
5. А вот классическую английскую овсянку чаще едят герои Остен: несмотря на всю стереотипность, Куин, возможно, сочла кашу недостаточно возвышенной для описания жизни герцогов и виконтов.
Даже шуточные форматы могут иногда указать на неочевидные вещи: если то, что у Остен нет корги, а в «Бриджертонах» есть, видно сразу, то заметить, что в книгах о Бриджертонах больше цветов, не так просто. Это небольшое исследование может стать подспорьем в будущих исследованиях того, как эпоха Регентства (дореволюционная Россия, Америка времен освоения Дикого Запада, подставить нужное) может быть по-разному отражена в книгах, современных эпохе, и исторических романах, написанных в XXI веке.
Может быть, дальнее чтение сможет получить и прикладное значение для современных авторов. Проанализировав корпус текстов прошлого, писатель сможет избегать клише, ставших популярными позже, — или же, наоборот, использовать их осознанно, зная, что описывает не настоящее прошлое, а прошлое, состоящее из стереотипов и ассоциаций современного человека, и близкое именно ему.
Меня же это исследование научило тому, что иногда работа — это на 1% удар молотком (2–3 часа анализа данных) и на 99% — поиск, куда этим молотком бить (пристальное чтение романов о любви и мысли о словах). Но молоток из Voyant Tools и связки nltk+pymorphy, несомненно, вышел неплохой.
Напоследок хочу поблагодарить команду журнала «Смысловая 226» за прекрасную огранку материала: я никогда не смогла бы так красноречиво написать о том, что набравший 10/10 на тесте — настоящий «Бриллиант сезона».

