Введение
В 2002 году в цифровой гуманитаристике была совершена революция: в статье Джона Бёрроуза был описан новый метод стилистического анализа текстов — Дельта.
С тех пор метод Дельта не раз показал себя как весьма точный инструмент для определения авторства, работающий на разнообразном материале и разных языках. Для языка R была создана библиотека Stylo — набор инструментов стилистического анализа, который интегрировал Дельту в ряд своих функций. С помощью Stylo мы можем самостоятельно убедиться в том, что Роберт Гэлбрейт — это псевдоним Джоан Роулинг, а «Тихий Дон» наверняка написал Шолохов (и уж точно не Федор Крюков).
Но может ли Дельта с такой же уверенностью определить переводчика? Такой вопрос задает филолог и один из ведущих современных стилометристов Дэвид Хувер в своем исследовании The Invisible Translator Revisited.
Всё ясно, автор важнее переводчика
Чтобы правильно ответить на этот вопрос, нужно задуматься уже на моменте сбора текстов, которые мы собираемся друг с другом сравнивать. Какие тексты мы хотим и сколько? Сколько авторов мы хотим в наш корпус? А переводчиков?
Для начала возьмём набор текстов Чехова, переведенных пятью переводчиками на английский язык. Прогнав наш корпус через Stylo, мы получим дерево как на рис. 1.
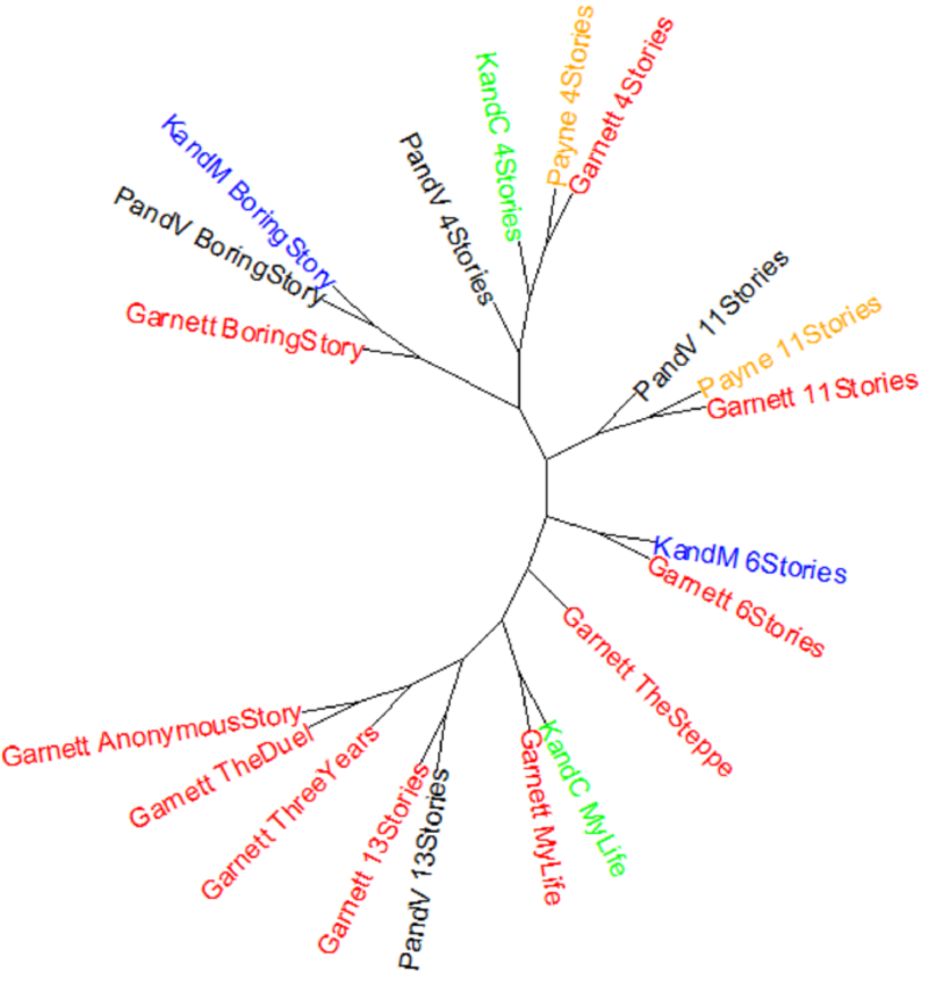
В первой части названия каждого файла указан переводчик (по этому слову, собственно, Stylo и определяет, в какой цвет окрасить строку), а во второй — имя произведения или сборника.
Как мы видим, если у текста есть несколько разных переводов, Дельта всё равно объединяет их в один «пучок». Таким образом, авторский сигнал оказывается сильнее, чем сигнал переводчика.
Однако интересно, что «Рассказ неизвестного человека», «Дуэль» и «Три года», переведенные Констанс Гарнетт и не имеющие других переводов, тоже оказались по расчётам Дельты весьма близки. Видимо, здесь стиль самой Гарнетт «пробивается» из-под стиля Чехова. Как тут не вспомнить критическое суждение о степени вольности в переводах Гарнетт от Владимира Набокова: «Причина того, что англоговорящие читатели едва ли могут объяснить разницу между Толстым и Достоевским, заключается в том, что они читают не прозу первого или второго. Они читают Констанс Гарнетт». Несмотря на это, приходится признать, что в этом эксперименте в целом авторский сигнал для Дельты важнее переводчика.
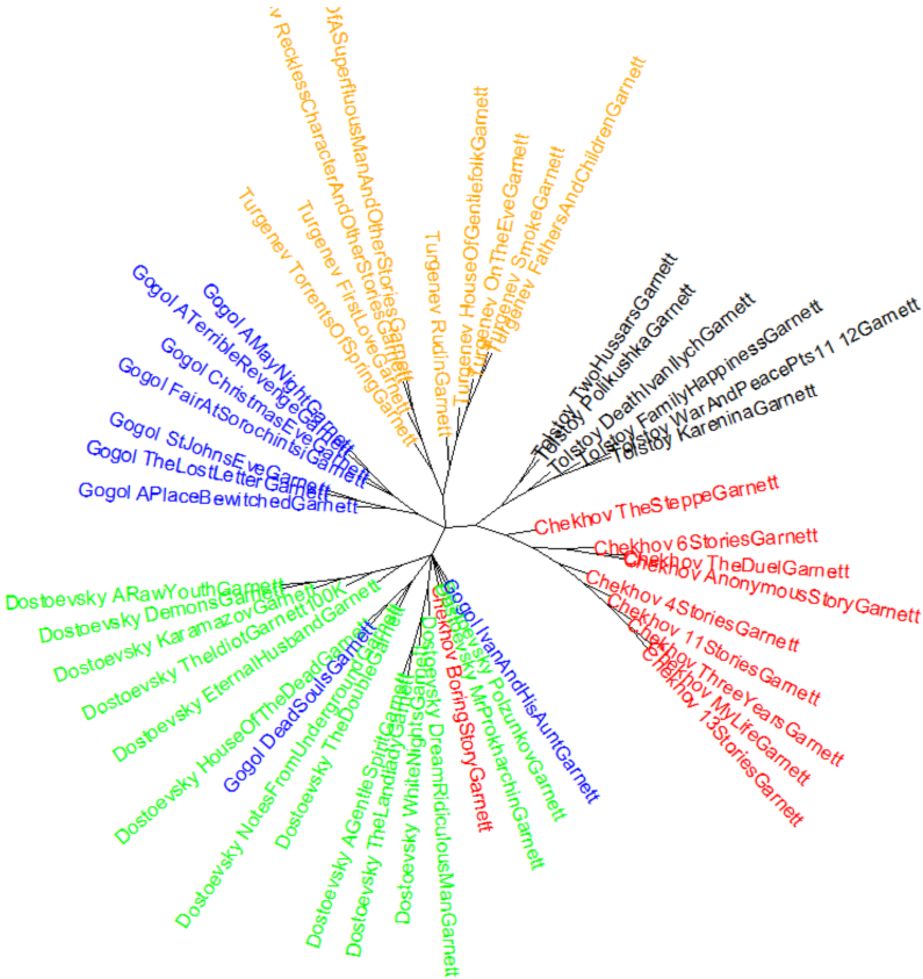
Если мы поменяем позиции переводчика и автора местами (пять русских авторов, один англоязычный переводчик), то мы увидим, что Дельта даже сквозь призму перевода может достаточно точно определить автора оригинала (рис. 2): Гоголь похож на Гоголя, Тургенев на Тургенева и т.д.
Среди функций Stylo есть функция classify — инструмент, который при помощи машинного обучения пытается определить, насколько он точно может, получив документ, угадать его «класс» на основе стилометрических признаков, т.е. той же Дельты. Классом может быть автор, переводчик, жанр, временной период, практически что угодно.
Чтобы обучить наш классификатор, нам нужны тренировочная и тестовая выборки.
В эксперименте участвуют по несколько переведенных на английских текстов Толстого, Тургенева, Чехова, Достоевского и Гоголя. Тексты каждого из них разделены между двумя выборками.
Дэвид Хувер подобрал корпус таким образом, чтобы в нем не было нескольких переводов одного текста. Обученный классификатор в итоге выдал хорошие результаты: две разные модели (NSC и SVM) угадали оригинального автора в 94,5% и 96% случаев.
Хувер провел эксперимент второй раз, усложнив условия: в корпусе у каждого оригинального автора все его тексты переведены разными переводчиками. Неудивительно, что результаты оказались хуже: точности классификаторов снизились до 85.8% и 87.6%. Таким образом, стиль автора хотя и остается основным сигналом, который улавливает стилометрия, но все-таки искажается при переводе — каждый переводчик накладывает свой стилистический отпечаток на итоговый продукт.
Что сделать, чтобы автор умер
Мы увидели, что стиль переводчика при стилометрическом анализе всё-таки имеет некоторый вес. А можем ли мы искусственно ослабить значимость автора — и научиться улавливать именно отпечаток переводчика? Какой набор текстов нам нужен, чтобы classify хорошо умел опознавать только переводчика?
Хувер решает проблему так: вместо того, чтобы каждый автор был и в тренировочной, и в тестовой выборках, нам нужно, чтобы в них авторы были разные, а переводчики — одинаковые.
В тренировочную выборку он вложил тексты Толстого, переведенного Констанс Гарнетт, и Достоевского, переведенного Ричардом Певеаром и Ларисой Волохонской. В тестовую же выборку пошли тексты других русских писателей (Чехов, Гончаров, Тургенев, Гоголь), переведенные теми же людьми.
Программе было сказано, что классы, которые она должна определить — это класс «Garnett» и класс «PandV», то есть переводчики. Таким образом, по Гарнеттовским переводам Толстого и Достоевского Stylo должен был понять, где её же переводы Чехова и Тургенева. В итоге те же две модели — NSC и SVM — угадали в 81.2% и 93.9% случаев соответственно.
Идем дальше по алфавиту
Кроме Дельты в мире современной стилеметрии используется еще множество других методов. Среди них есть и так называемый Зета-анализ, который сравнивает, насколько постоянны включение и исключение набора слов в равных по размеру сегментах текста, на которые разделены произведения.
Если мы посмотрим на тех же переводчиков и их переводы Гоголя, то мы заметим, что многие слова, которые часто встречаются у Гарнетт, избегаются Певеаром и Волохонской, и то же верно наоборот. На двумерном пространстве их различие выглядит как на рис. 3. Очень важно, что даже два перевода одного и того же текста находятся не рядом, а по разные стороны графика.
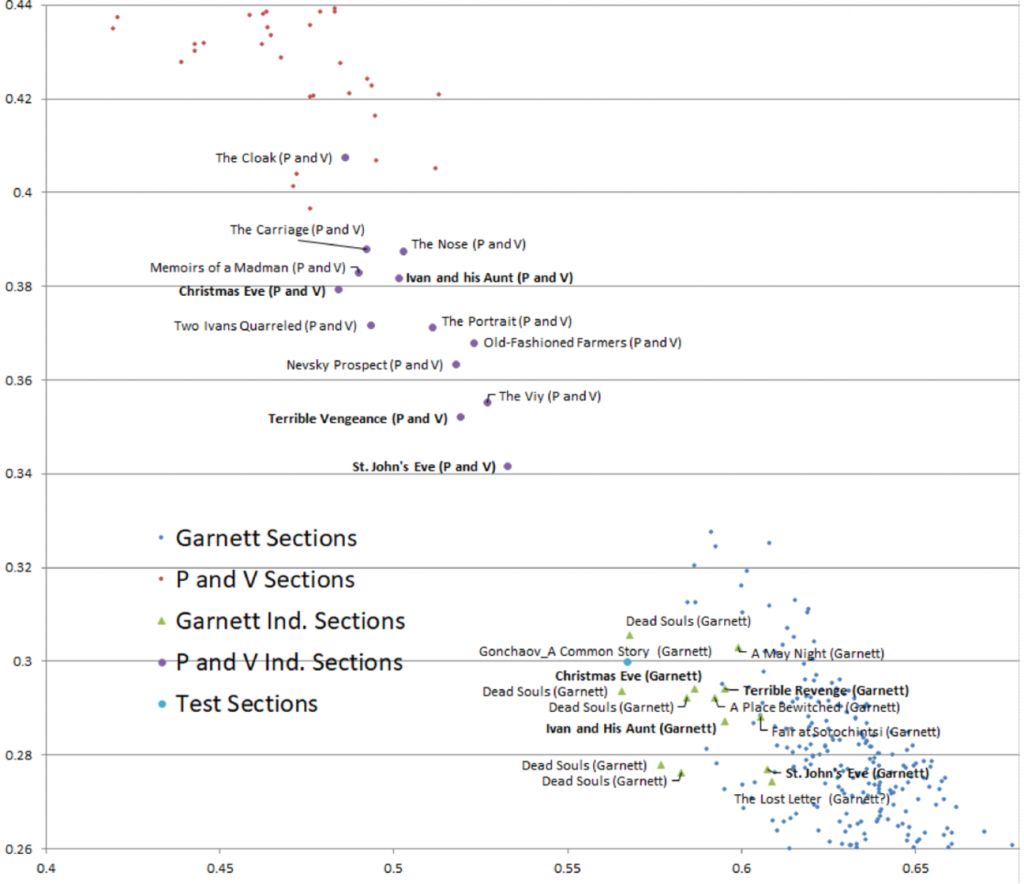
Попробуем отобразить эти различия на графике. Маленькие синие точки обозначают маленькие равные по размеру фрагменты из Гоголя, переведенные Гарнетт. Маленькие красные точки — такие же фрагменты из Гоголя, переведенные Певеаром и Волохонской. Зеленые треугольники — это уже целые произведения Гоголя, переведенные Гарнетт. Большие фиолетовые кружки — то же самое, но переводчики — Певеар и Волохонская. Единственная большая голубая точка — это тестовый файл, в котором не Гоголь, а «Обыкновенная история» Гончарова в переводе Гарнетт. Стоит отметить, что и этот файл на графике ближе к Гарнеттовскому Гоголю.
Оси отображают частотность слов, которые использует один переводчик, но не использует другой, т.е. отличительных слов.
Чем больше в конкретном переводе или его отрывке встречается таких слов, тем выше точка по вертикальной оси (если это переводы Певеара и Волохонского) или тем правее по горизонтальной (если это переводы Гарнетта). На этом графике даже два перевода одного и того же текста разными переводчиками находятся не рядом. Из-за большой частотности отличительных слов они «разводятся» по разным сторонам.
Классическая пара слов, которую выделяет Зета-анализ — это слова till и until: первое используется Гарнетт, в то время как его избегают Певеар и Волохонская, предпочитая второе.
Также интересно, что Певеар и Волохонская значительно чаще используют наречия на -ly в сравнении с Гарнетт.

Заключение
Ответ на вопрос «можно ли методами современной компьютерной филологии определить стиль переводчика?» получился очень даже в духе переводчиков: всё зависит от контекста.
Для того чтобы Дельта могла обратить внимание на переводческий стиль, а не на автора оригинала, нужно хорошо понимать, какой корпус для этого подходит, а какой — нет.
Кроме Дельты Бёрроуза существует и Зета, в некоторых случаях лучший способ распознать переводческий стиль.
У нас есть свобода выбора, когда дело доходит до сравнения переводческих стилей. Нам остается понять, какой из вариантов эксперимента лучше подходит конкретно нашей выборке и нашим целям. Поэтому несмотря на большой прогресс компьютерных методов стилометрии, решающее слово остается за компетентным исследователем-литературоведом.
Источники
Исследование Дэвида Хувера можно прочитать здесь.
Больше о Дельте Бёрроуза и Stylo можно посмотреть здесь, здесь и здесь.