Структура комиксов
Обычно комиксы публикуются в печатных журналах, газетах или в виде книг. Каждая страница комикса состоит из одного или нескольких отдельных изображений, которые расположены в макете и часто ограничены визуальными рамками (фреймами). Эти так называемые «панели» — фундаментальная структурно-смысловая единица в комиксах. Они, как правило, содержат линейные рисунки, которые изображают сцену, включая символы, объекты и фон, а также текстовые объекты: повествовательные подписи и речевые выноски. К этому добавляются и другие элементы — например, звукоподражания. К «визуальным морфемам» относятся и «живописные руны» — это специфичные для культуры маленькие символы, которые выражают чувства и ощущения персонажей — такие используются в японской манге.

Вычислительный подход
Хотя комиксы изучались в гуманитарных науках несколько десятилетий, вычислительные подходы к анализу комиксов все еще не на высоте. Существуют исследования, в основном касающиеся аспектов представления комиксов на уровне единицы, то есть графической и морфологической структуры. Концептуальная структура более высокого уровня — все еще не изученная тема в вычислительном анализе. Она требует компьютерного зрения для понимания макета страницы, визуальных сцен внутри и за пределами отдельных панелей, а также персонажей, объектов, действий и эмоциональных выражений. Обработка языка необходима для понимания истории и диалога, а также для создания и поддержки высокоуровневой повествовательной модели для захвата событий.
Наборы данных
До недавнего времени ни один корпус оцифрованных комиксов не был доступен для исследования, поэтому ранние исследования основывались на извлечении большого количества изображений с сомнительным юридическим статусом — например, с сайтов «сканирования» манги. В последние несколько лет было создано несколько исследовательских групп.
В корпусах оцифрованных комиксов содержатся либо изображения, у которых срок действия авторского права истек, либо такие, которые авторы сами предоставили для исследовательских целей, а также для составления описания и метаданных к изображениям. Но сканы не могут распространяться дальше необходимого использования, так как это выходит за рамки предоставленных прав. Очевидно, что общедоступные наборы данных более полезны, но часть этой информации в частных наборах данных уникальна.
Анализ визуальной структуры
Для анализа визуальной структуры комиксов используется компьютерное зрение, которое строится на глубоком машинном обучении. Традиционные методы компьютерного зрения требуют тщательного проектирования компонентов для получения инженерных средств извлечения данных, которые преобразуют необработанный ввод (например, пиксели изображения) в изображения более высокого уровня. Проектирование компонентов сложно и дорого, так как требует знаний в области инженерии. Кроме того, даже высокоинтегрированные признаки (в нашем случае наборы из множества пикселей) все еще являются относительно низкоуровневыми с точки зрения иерархии визуальных объектов.


Методы глубокого обучения, напротив, извлекают наиболее релевантные элементы изображения из данных, регулируя иерархию объектов. Технологии обработки изображений работают близко к тому, как устроены биологические системы зрения. Когда мы смотрим на какой-либо объект, сначала мы замечаем его общую форму и самые базовые фрагменты. Чем меньше детали, тем сложнее все их выделить и рассмотреть сразу. Объекты в комиксах на более низких уровнях (например, на уровне фреймов) относительно четкие, тогда как на высоких уровнях они становятся все более абстрактными, мелкие детали распознавать сложнее.
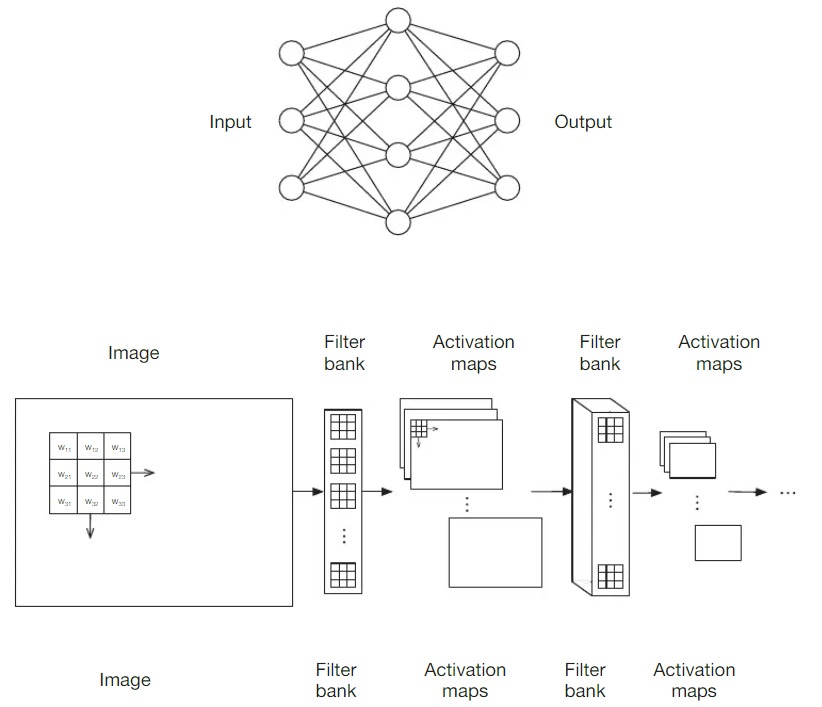
То есть компьютер видит, что на изображении есть объекты, совокупность этих объектов представляет собой слои. Эти слои объектов извлечены из имеющихся данных с использованием обратного градиентного спуска. Ниже, на рис. 2 Input, изображены так называемые «полностью соединенные сети» (CNN). Они соединяются друг с другом, образуя новые слои и на выходе, мы получаем новое изображение. По той же схеме работают «сверточные слои» в CNN (рис. 3) — это хранилища небольших фильтров для локальных фрагментов изображения. Фильтр применяется ко всему изображению независимо от местоположения объекта, что значительно сокращает количество параметров, то есть, после применения фильтра, образуются активационные карты — участки изображения, на которых компьютер распознает объект, далее, к этому же объекту применяется еще фильтр и появляется новый объект, такие слои подобны зеркальной перспективе.
Распознавание каждого объекта на изображении необходимо для его более детального представления.
Анализ текста и нарративной структуры
Большинство исследований текста до настоящего времени было сосредоточено на анализе его содержания. Для многих современных типов документов автоматическое извлечение текста стало обычным делом. Однако текст комиксов характеризуется высокой изменчивостью, как с точки зрения используемых шрифтов и типов текста, так и размещения на странице. Кроме того, шрифты оцифровываются на основе почерка художника или разрабатываются специально для конкретного комикса. Это различие усложняет вычислительное распознавание: различные углы, формы и размеры букв, разная толщина нарисованных от руки линий и вероятность наложения символов приводят к более высокой частоте ошибок при применении OCR (технологии распознавания текста) к комиксам.
Эта изменчивость находит эквивалент в разных типах текста, которые используют комиксы. Речевое представление в форме монологов или диалогов между персонажами может быть наиболее распространенным, но современные западные комиксы содержат большое количество повествовательного текста. Японская манга и ее родственные формы часто используют звукоподражания. Текст может быть разбит по всей странице комиксов, от вывесок магазинов до газетных полос. Графические границы, которые могут помочь с разметкой заголовка или надписи, не включают в себя вторичный текст (тот, что изображает вывески и другие не-речевые надписи) или звукоподражание.
Задача качественного распознавания текста для комиксов обычно решается одним из двух способов: подходы «сверху вниз» начинаются с распознавания заголовков или речевых выносок. Как правило, вторичный текст и звукоподражание игнорируются. Подход «снизу вверх» стремится обнаружить текст, отделяя его от графических объектов без предварительного анализа макета страницы. Оба подхода имеют свою слабость, состоящую в зависимости текста от эвристики или культурного феномена, который обусловлен художественным экспериментированием и отклонением от устоявшихся условностей.
В последнее время нейронные сети привели к значительным успехам в распознавании рукописных, редких или нерегулярных шрифтов. Последние версии механизмов OCR (технологии распознавания текста) основаны на нейронных сетях LSTM (сеть с долгой краткосрочной памятью) и хорошо работают с историческими документами без необходимости аннотирования данных. Однако эти предварительно обученные сети по-прежнему выдают много ошибок при применении непосредственно к комиксам.
Обучение машины простым CNN (сверточным нейронным сетям) с относительно небольшими наборами данных значительно повышает распознавание объектов. Для нарисованных от руки символов уже достигнут уровень точности 97%. Другой подход взят у исследователей Хартеля и Данста (2019). Используя программу распознавания текстов Tesseract 4, авторы показывают, что даже не идеально распознанные тексты комиксов могут использоваться для простого анализа текста на основе модели, содержащей определенный набор слов и дают результаты, аналогичные транскрибируемым вручную данным.
Повторение элементов важно при построении общей структуры событий. Отслеживая эти элементы в повествовательной части и связывая воедино информацию о них, строятся связные цепочки. Такие связи между (повторными) появлениями определяют интерпретацию читателя.
Чтение комиксов
Исследователи выделяют подход к чтению комиксов, который состоит в анализе визуального внимание и айтрекинге — то есть отслеживании взгляда человека в режиме реального времени, что позволяет выявить на каких объектах больше сосредоточено его внимание, тем самым снизить вычислительную сложность. Как правило, читатель останавливает взгляд на крупных выносках и ярких объектах, что неудивительно.

Все имеет свою глубину, и комиксы не исключение. Методы машинного обучения развиваются с каждым днем и применяются в самых разных областях науки. Теперь ML-модели добрались и до комиксов — и показали, что детали в них куда интереснее, чем кажется.