
Мы уже писали о такой популярной задаче машинного обучения, как определение сложности текстов. Такой алгоритм необходим для поиска подходящих текстов на русском языке для студентов-иностранцев, при проверке на читабельность законов и государственных документов, медицинских текстов и много где ещё.

Но для обучения и проверки качества работы такой модели необходимо иметь «золотой стандарт» — коллекцию текстов, уже размеченных по сложности. И тут много вопросов: где взять такую коллекцию? По какой шкале измерять сложность? Как избежать субъективности в разметке — для кого-то этот текст сложен, а для кого-то нет
Поскольку наше исследование касается текстов для студентов-иностранцев, идея источника золотого стандарта и шкалы сложности лежала на поверхности: взять за основу международную шкалу владения иностранными языками CEFR (Beginner, Intermediate и т.д., всего 6 уровней) и найти тексты из учебников, помеченных соответствующим уровнем.
Например, все тексты учебника «Дорога в Россию» уровня А1 пометить уровнем 1, уровня А2 — 2 и т.д. Но тут возникли проблемы:
- стало очевидным, что сложность логичнее представлять в виде постоянно возрастающей дробной величины, а не шести закрытых уровней, ведь тексты внутри одного учебника тоже варьируются по языковой сложности;
- оценка уровня учебника авторами субъективна и зачастую туманна: учебник «продвинутого уровня», «для второго семестра первого года обучения»;
Получается, необходимо скорректировать коллекцию текстов и получить более объективную и дробную разметку по уровням для нашего золотого стандарта. И вот тут мы и подумали про шахматы (вдохновившись постом на Хабре ребят из SkyEng про использование рейтинга Эло для поиска наиболее ценных для изучения слов английского языка).
Идея рейтинга венгерского математика Арпада Эло состоит в том, что ценность победы того или иного игрока стоит рассчитывать исходя из предсказуемости (т.е. математического ожидания) его победы. Эта мера широко применяется для расчёта относительной силы игроков в шахматы. Скажем, если гроссмейстер выиграет у новичка, это прибавит к его рейтингу совсем немного баллов, т.к. победа была вполне ожидаемой, а вот если выиграет новичок — это даст ему огромное количество баллов и значительное продвижение в турнирной таблице.
Похожий процесс можно представить, если сравнивать два текста по сложности: начальная оценка текста, данная авторами учебника — это предварительная турнирная таблица, которая подсказывает, кто тут «гроссмейстер», кто — «новичок», а кто — примерно равные игроки. Далее происходит сама «партия»: аннотатору даются 2 текста и предлагается выбрать, какой из них сложнее. В результате «партии» каждый текст получает баллы:
1 — если текст оказался сложнее
0 — если текст оказался легче
0.5 — если аннотатор затруднился ответить

Формула расчета новой оценки текста i выглядит так:
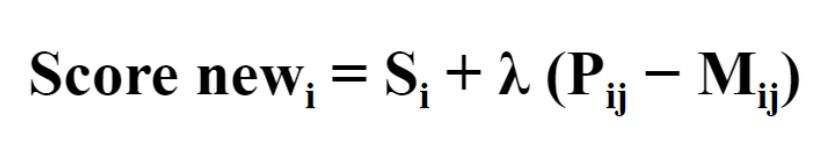
где
Si — исходная оценка текста i
Pij — набранный текстом i балл в сравнении c j
Mij — математическое ожидание, что i-тый текст окажется сложнее j-ого — вычисляемый коэффициент
λ — вычисляемый коэффициент
Например, перед нами 4 фрагмента текста и их начальные оценки, данные авторами учебника:
Чистые пруды (уровень 1.5)
Улица Чистые пруды — это старая улица в центре Москвы. Эта улица небольшая, но известная. История этой небольшой московской улицы очень интересная. Там находятся старые пруды. Раньше, три века назад, это были грязные пруды. Но в 1703 (в тысяча семьсот третьем) году Александр Меньшиков (секретарь русского царя Петра Первого) купил это место и приказал очистить пруды. После этого люди дали этой небольшой улице название Чистые пруды. Москвичи хорошо знают и любят эту красивую улицу.
Борода (уровень 1.5)
Режим талибов, который ещё недавно правил в Афганистане, приказал всем мужчинам носить бороды. Запреты (правда, неофициальные) на бороду и усы были даже в советские времена. Известный телеведущий Александр Масляков в одном из интервью рассказывал, что председатель Гостелерадио СССР Лапин «не рекомендовал» показывать на телевидении людей с усами и бородами. А один знакомый писатель рассказал мне, как в 1976-ом году он поступал в московский Литературный институт и должен был пройти специальное интервью.
Бабушка (уровень 2.5)
Бабушка — это человек, собирающий всю семью за большим столом, сохраняющий и поддерживающий традиции в семье. Итальянские семьи, с любовью сохраняющие семейные традиции, считают свой дом святым местом. Итальянцы, имеющие свой собственный дом, предпочитают современную мебель из пластика и металла. Но наряду с этим в доме бережно хранятся старинные вещи, картины и украшения, рассказывающие об истории семьи. Эти вещи передаются по наследству детям и внукам.
Флешмоб (уровень 3.5)
В начале августа благодаря Марку Цукербергу в сети распространился флешмоб под названием Ice Bucket Challenge. Звезды, успешные предприниматели и целые команды начали обливаться ведрами ледяной воды и передавать эстафету друг другу, чтобы привлечь внимание к изучению бокового амиотрофического склероза (БАС) — неизлечимого заболевания. Российские предприниматели адаптировали мировой флешмоб, добавив в него водку, виски и рекламу.
Были сыграны следующие «партии»:
- Борода VS Чистые пруды 1 — 0
- Борода VS Бабушка 1 — 0
- Борода VS Флешмоб 0.5 — 0.5
Нескольким аннотаторам текст про бороды показался сложнее других: он выиграл не только у равного по уровню текста о Чистых прудах, но и более сложного текста о Бабушке. Это привело к тому, что в новом рейтинге текст Борода поднялся, а тексты Бабушка и Флешмоб, наоборот, потеряли свои позиции, поскольку в сравнении с более простым текстом не смогли одержать победу. Однако стоит отметить, что изменения в рейтинге происходят малыми шагами: это помогает бороться с ошибками в разметке и субъективным мнением аннотаторов.

Помочь научному проекту и поучаствовать в состязании текстов, а также потестить нашу систему проверки адекватности аннотатора можно тут. Мы будем вам очень благодарны!

