
Сложные обороты типа брат матери моего дяди по-научному называются посессивные конструкции с терминами родства. Название происходит от латинского possessio – владение, обладание, отсюда же произошел английский глагол to possess — иметь, обладать.
В русском языке обладание чем-либо (та самая посессивность, она же притяжательность) обычно передается родительным падежом: деньги Маши, дом Васи, мама Саши. Поэтому в конструкциях с описанием родственных связей все термины родства, кроме самого первого, стоят в родительном падеже: отца, матери, сестры. Первое слово является вершиной конструкции, поэтому может стоять в любом падеже в зависимости от роли в предложении (ср. пришел брат матери моего дяди — она пришла с братом матери моего дяди).
Еще конструкция может содержать притяжательное местоимение (моего, ее, вашей). Ниже приведено несколько примеров таких конструкций:
- сваха племянника вашей сестры
- сестра мужа моей тёщи
- брат зятя их отца
Посессивные конструкции с терминами родства сложны для восприятия — читателю трудно быстро вычислить родственные связи между упомянутыми в них людьми. Кроме того, в таких конструкциях часто встречаются названия родственников, приобретаемых в браке (шурин, свояк и др.), значения которых могут быть неизвестны участникам диалога. Термины родства вообще становятся все менее известными по мере изменения социальных норм и урбанизации.
Было бы удобно автоматически анализировать такие конструкции и представлять их в удобном для восприятия виде — например, в виде генеалогических деревьев. Мы решили эту задачу на Python и сейчас расскажем, как.
Мы выделили три этапа обработки конструкций: выделение конструкций во входном фрагменте текста, построение графа родственных связей и визуализация полученного графа в виде генеалогического дерева. Рассмотрим каждый этап более подробно.
Поиск конструкций
Выделение последовательностей
На первом этапе нам нужно найти конструкции в тексте. Иногда они входят в предложения в том виде, который был описан выше, например как в предложении:
- С нами жила сестра моей бабушки.
Однако, так происходит не всегда. Между терминами родства могут стоять синтаксические определения (прилагательные, причастия, порядковые числительные, притяжательные местоимения и др.), причем иногда они сами могут иметь значение родства.
- С нами жила сестра моей покойной бабушки.
- С нами жила бабушкина сестра.
Кроме того, последним в конструкции может стоять не термин родства, а существительное, напротив, без значения родства.
- С нами жила сестра бабушки моей подруги.
Все эти случаи тоже хотелось бы учитывать, поэтому сначала мы выделим из текста последовательности слов, содержащие интересующие нас конструкции, а затем «вычеркнем» из них лишние слова.
Сформулируем более формально, что может содержать последовательность:
- термины родства (в любом падеже, если это слово первое в последовательности, и в родительном падеже далее)
- синтаксические определения
- одно существительное, не являющееся термином родства, в родительном падеже (это слово будет последним в последовательности)
Эти правила выделения последовательностей отражены в функции search_sentence. Она принимает строку, содержащую предложение на русском языке, и возвращает список найденных последовательностей.
from nltk.tokenize import word_tokenize
def search_sentence(sent):
# разбиваем предложение на слова функцией word_tokenize из библиотеки NLTK
sent = word_tokenize(sent, language='russian')
sent = [word.lower() for word in sent]
results = []
prev_kin, prev_def = False, False
i = 0
while i < len(sent):
word = sent[i]
# найдено первое слово в нов. последовательности
if not prev_kin and not prev_def and is_kinship_term(word):
start = i
prev_kin = True
# берем все определения перед ним
while start > 0 and is_definition(sent[start - 1]):
start -= 1
i += 1
# мы внутри конструкции
elif prev_kin or prev_def:
# текущ. слово - определение
if is_definition(word):
prev_def = True
prev_kin = False
i += 1
# текущ. слово - термин родства в Р. п.
elif is_kinship_term(word, case='gent'):
prev_kin = True
prev_def = False
i += 1
else:
# текущ. слово - существительное в Р. п.
if is_noun(word, case='gent'):
results.append(sent[start:i + 1])
else:
results.append(sent[start:i])
prev_kin = False
prev_def = False
else: # мы вне конструкции
i += 1
return resultsПроверка, является ли слово термином родства, определением или существительным, осуществляется с помощью специальных функций is_kinship_term, is_definition и is_noun.
В функции is_kinship_term мы получаем начальную форму и список грамматических категорий слова с помощью морфологического анализатора pymorphy2 и затем проверяем, входит ли начальная форма в заранее заданный вручную список терминов родства (для примера здесь приводится неполный список). У этой функции также есть аргумент case — падеж. Он может быть задан строкой — грамматическим тегом, либо равняться None (в таком случае падеж может быть любым).
Функция parse в pymorphy2 возвращает несколько вариантов морфологического разбора в порядке убывания вероятности того, что этот разбор является верным. Таким образом, наиболее вероятным является первый вариант разбора, однако он не всегда оказывается верным, например в случае совпадения форм разных падежей существительного. Чтобы избежать возможных ошибок, мы рассматриваем все варианты разбора, предлагаемые функцией parse, а не только первый, как предлагается в документации библиотеки.
import pymorphy2
morph = pymorphy2.MorphAnalyzer()
kinship_term_list = ['мать', 'отец', 'дочь', 'сын', 'бабушка', 'дедушка', 'муж', 'жена', 'сестра', 'брат']
def is_kinship_term(s, case=None): # термин родства?
s_parse = morph.parse(s)
if case is None:
for v in s_parse:
if v.normal_form in kinship_term_list:
return True
else:
for v in s_parse:
if v.normal_form in kinship_term_list and v.tag.case == case:
return True
return FalseВ функции is_definition мы также парсим слово с помощью pymorphy2 и проверяем тег части речи: он должен быть ADJF, ADJS, PRTF или PRTS. Таким образом в pymorphy2 кодируются полные и краткие прилагательные и причастия, а также порядковые числительные и местоимения-прилагательные.
def is_definition(s): # определение?
s_parse = morph.parse(s)
for v in s_parse:
if v.tag.POS in ['ADJF', 'ADJS', 'PRTF', 'PRTS']:
return True
return FalseАналогичным образом работает функция is_noun.
Типы конструкции
Вернемся к примерам конструкций, которые мы рассмотрели вначале (сестра моей покойной бабушки, бабушкина сестра, сестра бабушки моей подруги). Теперь нужно убрать из них лишние определения, а затем определить, к какому типу конструкции относится каждая из них. Мы выделили пять типов конструкции, основываясь на примерах приведенных вначале. Эти типы конструкции описывают большую часть случаев использования посессивных конструкций с терминами родства в русском языке.
Там, где падеж существительного не указан, он может быть любым. n=0,1,2… означает ноль или более таких слов (терминов родства в родительном падеже).
- притяжательное прилагательное со значением родства / притяжательное местоимение + термин родства
Пример: бабушкина сестра - термин родства + термин родства (Р. п.) (n=0,1,2…) + притяжательное местоимение + термин родства (Р. п.)
Пример: сестра моей бабушки - термин родства + термин родства (Р. п.) (n=0,1,2…) + притяжательное местоимение
Пример: сестра бабушки моей - термин родства + термин родства (Р. п.) (n=0,1,2…) + существительное (не термин родства) (Р. п.)
Пример: сестра бабушки подруги - термин родства + термин родства (Р. п.) (n=0,1,2…)
Пример: сестра бабушки
Рассмотрим, как устроено определение типа конструкции в программе, на примере типа 2. Сначала удалим из последовательности определения, не являющиеся притяжательными прилагательными или местоимениями. Для проверки используются функции is_pronoun и is_poss_adj, устроенные аналогично функции is_definition.
seq_original = ['сестрой', 'моей', 'покойной', 'бабушки']
seq_as_type = []
for word in seq_original:
if not is_kinship_term(word) and is_definition(word) and not is_poss_adj(word) and not is_pronoun(word):
continue
seq_as_type.append(word)В seq_as_type после этого будет сохранен список [‘сестрой’, ‘моей’, ‘бабушки’].
Затем проверим, подходит ли конструкция под тип 2.
sec_last_word = seq_as_type[len(seq_as_type) - 2] # предпоследнее слово
last_word = seq_as_type[-1] # последнее слово
flag = True
if (is_pronoun(sec_last_word) or is_poss_adj(sec_last_word)) and not is_kinship_term(sec_last_word) \
and is_kinship_term(last_word):
for word in seq_as_type:
if is_kinship_term(word) or word == sec_last_word:
continue
flag = FalseВ результате flag = True — конструкция подходит под тип 2.
Нормальная форма
Наконец, нам нужно привести конструкцию к так называемой нормальной форме — виду, где все слова в конструкции, кроме первого, являются терминами родства в начальной форме и расставлены в прямом порядке родства (подробнее см. ниже).
- сестра моей бабушки —> я бабушка сестра
Как получить нормальную форму?
- термины родства приведем к начальной форме (напрямую с помощью pymorphy2)
- другие существительные поставим в именительный падеж с сохранением числа (с помощью функции inflect из pymorphy2)
- притяжательные местоимения заменим на соответствующие им личные в начальной форме: мой —> я (по заранее заготовленному словарю)
- притяжательные прилагательные со значением родства заменим на соответствующие им термины родства в начальной форме: бабушкин —> бабушка (также по заранее заготовленному словарю)
Теперь расставим слова в конструкции в так называемом прямом порядке родства: справа от слова должно стоять то слово, от которого к нему в оригинальной конструкции задается вопрос чьего? / чьей? или вопрос родительного падежа кого? (см. примеры ниже). В программе на этом шаге мы делаем следующее, в зависимости от типа конструкции:
Тип 1: вставляем в начало местоимение я.
- бабушкина сестра —> бабушка сестра —> я бабушка сестра
Тип 2: меняем местами последние два слова, меняем порядок слов на обратный.
- сестра моей бабушки —> сестра я бабушка —> сестра бабушка я —> я бабушка сестра
Тип 3, 4: меняем порядок слов на обратный.
- сестра бабушки моей —> сестра бабушка я —> я бабушка сестра
- сестра бабушки подруги —> сестра бабушка подруга —> подруга бабушка сестра
Тип 5: меняем порядок слов на обратный, вставляем в начало местоимение я.
- сестра бабушки —> сестра бабушка —> я бабушка сестра
В таком виде конструкция готова для построения графа родственных связей.
Шаблоны
Перейдем к построению графа, который затем изобразим в виду генеалогического дерева. Заранее подготовим шаблон для каждого термина родства — фрагмент графа, отражающий соответствующие родственные связи. См. пример: шаблон для слова сестра.
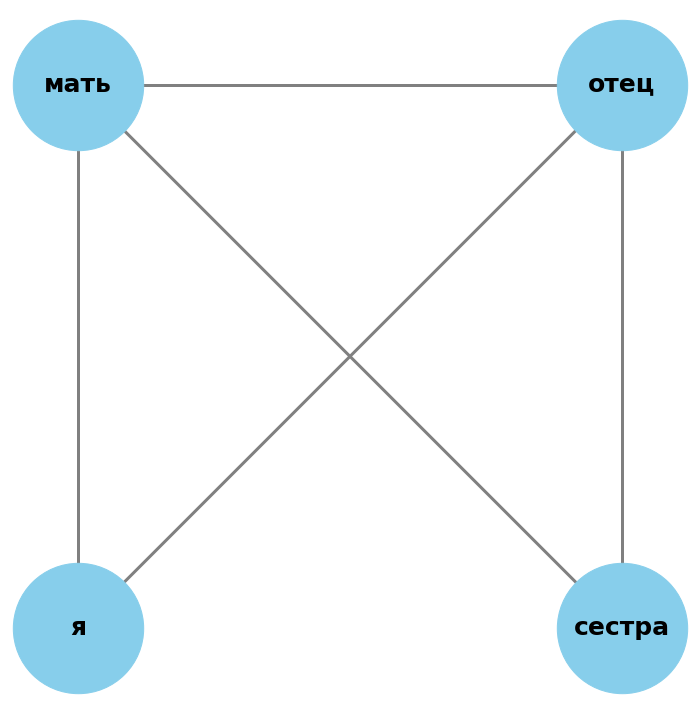
Как это реализовано в программе? Мы храним шаблоны и итоговый граф в виде списков экземпляров класса Relative. Полями класса являются:
- id — уникальный идентификатор персонажа
- name — имя персонажа
- relations — словарь:
ключи — шесть возможных прямых связей: mother, father, daughter, son, wife, husband
значения — списки id тех персонажей, с которыми данный персонаж связан этой связью
class Relative:
def __init__(self, id, name):
self.id = id
self.name = name
self.relations = {'mother': [], 'father': [], 'daughter': [], 'son': [], 'husband': [], 'wife': []}В рамках списка, представляющего граф или шаблон, экземпляры класса Relative отсортированы по возрастанию id.
Соединение шаблонов
Чтобы построить единый граф, будем последовательно загружать шаблон для каждого термина родства в конструкции и присоединять его к уже имеющемуся графу. При этом мы будем совмещать корень данного шаблона — узел с надписью я — с вершиной предыдущего — узлом, который подписан данным термином родства (например, сестра). На картинке ниже изображено присоединение шаблона бабушка к шаблону сестра. Здесь совмещаются узел сестра (вершина шаблона сестра) и узел я (корень шаблона бабушка).
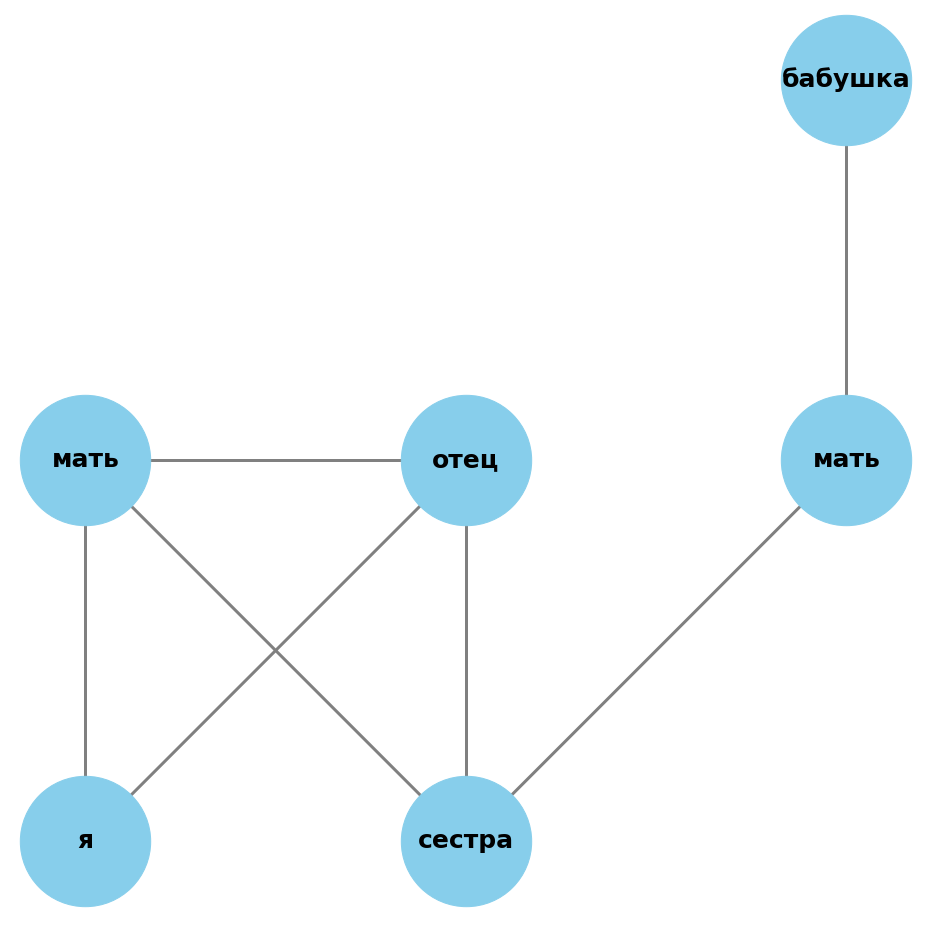
Посмотрим, как это реализовано в программе. Зададим текущий граф, состоящий из шаблона сестра.
me = Relative(id=0, name='я')
me.relations = {'mother': [1], 'father': [2], 'daughter': [], 'son': [], 'husband': [], 'wife': []}
mom = Relative(id=1, name='мать')
mom.relations = {'mother': [], 'father': [], 'daughter': [0, 3], 'son': [], 'husband': [2], 'wife': []}
dad = Relative(id=2, name='отец')
dad.relations = {'mother': [], 'father': [], 'daughter': [0, 3], 'son': [], 'husband': [], 'wife': [1]}
sis = Relative(id=3, name='сестра')
sis.relations = {'mother': [1], 'father': [2], 'daughter': [], 'son': [], 'husband': [], 'wife': []}
relatives = [me, mom, dad, sis]Зададим шаблон бабушка.
me = Relative(id=0, name='я')
me.relations = {'mother': [1], 'father': [], 'daughter': [], 'son': [], 'husband': [], 'wife': []}
mom = Relative(id=1, name='мать')
mom.relations = {'mother': [2], 'father': [], 'daughter': [0], 'son': [], 'husband': [], 'wife': []}
gran = Relative(id=2, name='бабушка')
gran.relations = {'mother': [], 'father': [], 'daughter': [1], 'son': [], 'husband': [], 'wife': []}
template = [me, mom, gran]Добавим шаблон бабушка к графу.
prev_top_id = 3 # идентификатор вершины предыдущего шаблона
# заменяем id персонажей шаблона на их текущий id + prev_top_id
for rel in template:
rel.id += prev_top_id
for rel_type in rel.relations:
for i in range(len(rel.relations[rel_type])):
rel.relations[rel_type][i] += prev_top_id
# находим вершину предыд. шаблона в relatives (запоминаем индекс в списке)
for i in range(len(relatives)):
if relatives[i].id == prev_top_id:
real_top_ind = i
break
# добавляем relations корня нового шаблона в relations вершины предыдущего
template_root_relations = template[0].relations
for rel_type in relatives[real_top_ind].relations:
relatives[real_top_ind].relations[rel_type].extend(template_root_relations[rel_type])
# добавляем в основной массив relatives родственников из шаблона, кроме его корня
for rel in template[1:]:
relatives.append(rel)Объединение дублирующихся персонажей
Можно заметить, в получившемся графе две вершины с надписью мать, поскольку в обоих шаблонах была такая вершина и при присоединении нового шаблона они не были совмещены. Такие случаи дублирования персонажей можно выявить на основании предположения, что у каждого персонажа может быть не более чем одна мать и один отец. Как сделать это в программе?
# наибольшее возможное связей данного типа
max_rel_number = {'mother': 1, 'father': 1,
'daughter': float('inf'), 'son': float('inf'),
'husband': float('inf'), 'wife': float('inf')}
# сделаем табличку: в каждой строчке список id, которые на самом деле относятся к одному персонажу
id_duplicates = []
for rel in relatives:
for rel_type in rel.relations:
# если персонаж связан данным типом связи с большим числом персонажей, чем разрешено
if len(rel.relations[rel_type]) > max_rel_number[rel_type]:
num = -1
# ищем, вдруг строчка про этого персонажа уже есть в таблице
for v in rel.relations[rel_type]:
for i in range(len(id_duplicates)):
if v in id_duplicates[i]:
num = i # сохраняем номер строки в таблице в num
break
# если еще нет, записываем в новую строку
if num == -1:
id_duplicates.append(rel.relations[rel_type])
# если есть, дописываем в нее
else:
for v in rel.relations[rel_type]:
if v not in id_duplicates[num]:
id_duplicates.append(v)
for i in range(len(id_duplicates)):
id_duplicates[i] = tuple(id_duplicates[i])В итоге в нашем случае id_duplicates = [(1, 4)].
Теперь объединим дублирующихся персонажей, которых мы выявили.
# создадим словарь "старый id : новый id"
final_ids = {}
for lst in id_duplicates:
for v in lst:
final_ids[v] = min(lst) # для дублир. персонажей берем минимум строки
for rel in relatives:
if rel.id not in final_ids:
final_ids[rel.id] = rel.id # для остальных - оставляем старый id
new_relatives = []
for lst in id_duplicates:
# создадим нового персонажа и сохраним в спец. массив
for rel in relatives: # ищем персонажа с соотв. final_id - от него возьмем name
if rel.id == final_ids[lst[0]]:
final_name = rel.name
new_rel = Relative(id=final_ids[lst[0]], name=final_name)
# relations - соберем ото всех, чьи id указаны в строке
for rel in relatives:
if rel.id in lst:
for rel_type in rel.relations:
for v in rel.relations[rel_type]:
if v not in new_rel.relations[rel_type]:
new_rel.relations[rel_type].append(final_ids[v])
new_relatives.append(new_rel)
# найдем, у кого персонаж числится в relations, и заменим id на final_id + удалим лишние записи
for rel in relatives:
for rel_type in rel.relations:
for i in range(len(rel.relations[rel_type])):
if rel.relations[rel_type][i] in lst:
rel.relations[rel_type][i] = final_ids[lst[0]]
for rel in relatives:
for rel_type in rel.relations:
rel.relations[rel_type] = list(set(rel.relations[rel_type]))
# удалим всех персонажей, кот. записаны более одного раза
for lst in id_duplicates:
ind = 0
while relatives and ind < len(relatives):
if relatives[ind].id in lst:
del relatives[ind]
else:
ind += 1
# добавим новосозданных персонажей (массив new_relatives)
relatives.extend(new_relatives)Граф из примера в итоге будет выглядеть так.

Стоит отметить, что в примере мы рассмотрели бабушку по матери, однако она может также быть бабушкой по отцу. Вследствие языковой неоднозначности, многим терминам родства соответствуют несколько шаблонов. Мы храним все возможные шаблоны для каждого термина родства и генерируем несколько вариантов финального графа, учитывая все возможные комбинации шаблонов.
Визуализация
Приступим к финальному этапу — визуализации графа. Составим список имен узлов и список ребер.
nodes = ['я', 'мать', 'отец', 'сестра', 'бабушка', 'муж']
edges = [('я', 'мать'), ('я', 'отец'), ('мать', 'отец'),
('мать', 'бабушка'), ('бабушка', 'муж'),
('сестра', 'мать'), ('сестра', 'отец')]Зададим координаты узлов по следующим правилам:
- родитель на один пункт выше ребенка
- ребенок на один пункт ниже родителя
- жена/муж на один пункт вправо от супруга(-и)
- если это место уже занято, сдвигаем узел на один пункт вправо
pos = {'я': (0, 0), 'мать': (0, 1), 'отец': (1, 1), 'сестра': (1, 0), 'бабушка': (0, 2), 'муж': (1, 2)}Создадим список цветов узлов
- cornflowerblue (синий) — персонаж соответствует первому или последнему слову в конструкции
- skyblue (голубой) — персонаж напрямую упомянут в конструкции, но не является первым или последним
- lightgrey (серый) — персонаж не упомянут в конструкции
node_color = ['cornflowerblue', 'lightgrey', 'lightgrey', 'skyblue', 'skyblue', 'cornflowerblue']Зададим пол персонажей, чтобы затем отразить его через форму узлов:
- круг — женщины (f)
- квадрат — мужчины (m)
- ромб — пол не определен (n) (используется для первого слова в конструкции)
node_sex = ['n', 'f', 'm', 'f', 'f', 'm']Зададим размеры окна, где будет расположен граф, а также саму конструкцию и предложение, в котором она была найдена, чтобы подписать их на картинке.
word_sequence = 'муж бабушки моей сестры'
sentence = 'Я знал его с детства - это был муж бабушки моей сестры.'
# размеры окна - рассчитываются из координат узлов
size_x = 1
size_y = 2
right = 1
top = 2
bottom = 0После этого сохраним граф в виде специальной графовой структуры, реализованной в библиотеке NetworkX, и отрисуем финальную картинку с помощью библиотеки Matplotlib.
import networkx as nx
import matplotlib.pyplot as pltПодготовим фон, на котором будет нарисован граф (он загружается из файла png).
import os
background_img = plt.imread('background_img.png')
# зададим три группы узлов в соответствии с их формой
f_list = []
m_list = []
n_list = []
f_color = []
m_color = []
n_color = []
f_pos = {}
m_pos = {}
n_pos = {}
for node, sex, color in zip(nodes, node_sex, node_color):
if sex == "f":
f_list.append(node)
f_color.append(color)
f_pos.update({node: pos[node]})
elif sex == "m":
m_list.append(node)
m_color.append(color)
m_pos.update({node: pos[node]})
else:
n_list.append(node)
n_color.append(color)
n_pos.update({node: pos[node]})
fig = plt.figure(figsize=(size_x + 19, size_y + 19))
ax = fig.add_subplot(111)
# вверху укажем конструкцию
fig.set(facecolor='white')
ax.set(facecolor='white')
ax.set_title(word_sequence, fontsize=40, fontweight='bold')
# внизу - предложение, где она была найдена
plt.figtext(0.5, 0.01, sentence, ha="center", fontsize=22,
bbox={"facecolor": "blue", "alpha": 0.1, "pad": 5}, wrap=True)
# сам граф отрисуем в рамке на светло-сером фоне
ax.imshow(background_img, extent=[-0.5, right + 0.5, bottom - 0.5, top + 0.5])
# добавим в граф узлы и ребра
G = nx.Graph()
nx.draw_networkx_nodes(G, f_pos, f_list, node_shape='o', node_size=7000, node_color=f_color, alpha=0.9)
nx.draw_networkx_nodes(G, m_pos, m_list, node_shape='s', node_size=7000, node_color=m_color, alpha=0.9)
nx.draw_networkx_nodes(G, n_pos, n_list, node_shape='d', node_size=7000, node_color=n_color, alpha=0.9)
G.add_edges_from(edges)
nx.draw_networkx_edges(G, pos, width=3, edge_color="grey")
nx.draw_networkx_labels(G, pos, font_size=18, font_weight='bold', labels=dict(zip(nodes, nodes)))
# сохраним картинку в файл
plt.savefig('graph.png')
fig.clf()
plt.close(fig=fig)Итоговая картинка будет выглядеть вот так.

Мы визуализировали конструкцию в виде генеалогического дерева — цель достигнута!
Заключение
Мы надеемся, что вам было интересно прочитать этот материал и при желании вы сможете повторить наш результат самостоятельно. Вы можете сами запустить фрагменты кода из этого материала вот здесь в jupyter notebook, а полный код проекта и примеры работы программы можно посмотреть в нашем гитхаб-репозитории.



