
Что случилось?
Возможно, на учебе вам дали задание, связанное с исследованием корпуса текстов, или у вас есть собственная идея такого проекта. «Системный Блокъ» отвечает на важные вопросы о том, как собрать, разметить и хранить корпус, и что с ним потом можно делать.
Но я даже не знаю, что такое корпус текстов!
Не беда! Текстовый корпус — это коллекция текстовых файлов, хранящихся на компьютере. Эти документы служат как «образец» языка, на котором удобно проверять разные гипотезы: скажем, правда ли, что в «Войне и мире» глаголов в прошедшем времени больше, чем в настоящем? В корпусе легко посчитать словарный состав текста, рассмотреть, какие формы встречаются друг с другом или в отдельности часто, а какие — не очень. Всё, что можно сосчитать в тексте, удобнее подсчитывать в корпусе.
Здорово! А как же компьютер поймет, что перед ним — глаголы прошедшего времени?
Для этого в текст документа специальные программы вписывают теги: особые метки, указывающие на часть речи и на грамматическую форму слова. Хорошо подходит программа MyStem — мы расскажем о ней.
Неужели есть программа, которая всё это определяет сама? Как ей пользоваться?
Да, MyStem, разработанный Яндексом, сделает работу по разметке текста за человека. Программа приведет текст в удобный для компьютерного анализа вид: слова поставит в начальную форму, добавит теги частей речи и грамматических категорий.
MyStem можно скачать здесь. В программе нет кнопок, ей нужно подавать команды через специальную командную строку.
На мой компьютер скачался архив с программой. Куда его распаковать?
Если у вас Windows, создайте на рабочем столе папку с любым удобным названием (например, «Stem»), и в нее положите Mystem.exe.
Погодите, у меня еще нет текста, который я буду анализировать. Где взять текст и как его хранить?
Лучше храните в .txt — тогда специальные символы из MS Word не будут мешать размечать корпус. Если у вас несколько текстов в разных документах, лучше сведите их в один большой документ. Назовите его input.txt и положите в папку Stem рядом с mystem.exe.
Если у вас еще нет никакого текста, возьмите наш документ. Это — книга Маргариты Наваррской «Гептамерон», мы выбрали ее из-за отсутствия авторских прав (книгу впервые опубликовали в 16 веке).
У меня получился текст в файле .txt, я скачал(а) myStem с сайта Яндекса. Что делать дальше?
Откройте командную строку. Если никогда раньше этого не делали — откройте Пуск, в нем — программу «Выполнить», и в появившейся строчке впишите cmd. То, что откроется и есть командная строка.
Появилось пустое чёрное окно. Как в нем выполнять команды?
Их нужно писать вручную.
Первая команда, которую нужно выполнить — указание на папку, с которой мы будем работать дальше. В данном случае это та папка, куда вы распаковали mystem. Нужная для этого команда cd выглядит вот так:
Cd «путь к папке на компьютере»
Лайфхак: чтобы не указывать путь к папке вручную, можно написать cd, а затем перетащить папку в окно командной строки мышью. Надпись C:\Users…\Desktop\stem появится автоматически — это и есть путь к папке.
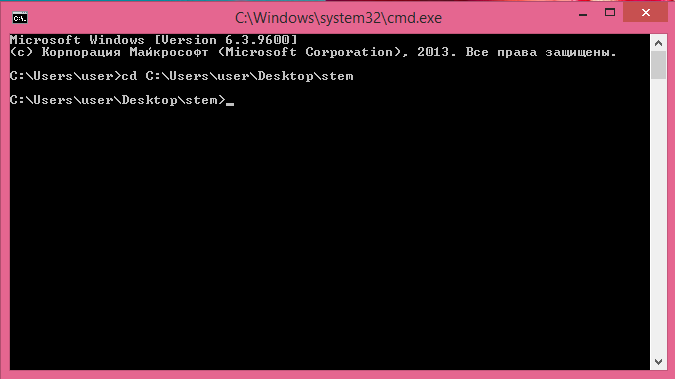
Вторая команда — запуск mystem
Напишите
mystem.exe input.txt output.txt -l
Эта команда состоит из четырех частей:
- mystem.exe — указание компьютеру о том, что нужно запустить стеммер;
- input.txt — название исходного файла;
- output.exe — название конечного файла;
- -l — параметр команды.
Чтобы все сработало, input.txt должен лежать в одной папке с mystem. Output.txt создавать заранее не нужно — программа создаст его сама. Кстати, названия файлов input и output можно выбрать любые.
Если все сделано правильно, появится подобная надпись:
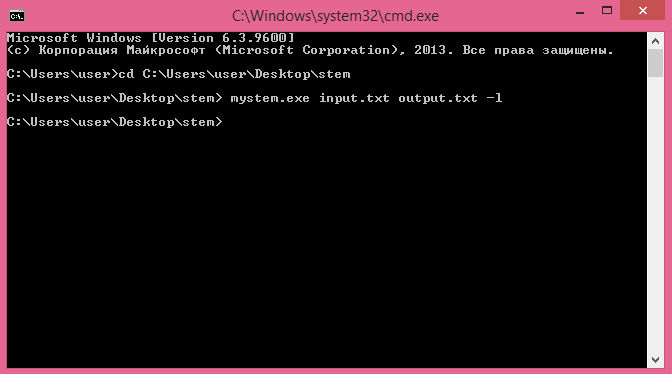
В папке stem будет создан файл output.txt. Его можно открыть и посмотреть, что получилось.
Если есть ошибки
Если появляется ошибка Failed to decode UTF-8 string at pos 0, значит, программа ожидает от текста кодировки по умолчанию — UTF-8. Если вы знаете, как поменять кодировку документа на UTF-8 — поменяйте. Можно подать команду
mystem.exe input.txt output.txt -e cp1251
Эта команда укажет стеммеру, что кодировка документа — cp1251. Еще программа работает с cp866 и koi8-r, но если вы скачали документ из статьи, с ним такой ошибки быть не должно, его кодировка — UTF-8.
А что вообще такое -l, -е?
Это параметры выполнения команды, уточняющие инструкции компьютеру. Их можно сравнить с режимами работы программы. Параметр -l указывает стеммеру, что в итоговом файле не нужно печатать словоформы, встреченные в тексте, а только начальные формы слов.
Попробуйте сначала выполнить команду
mystem.exe input.txt output.txt -l
А потом просто
mystem.exe input.txt output.txt
И посмотрите на разницу. Полный список параметров для mystem — здесь. Попробуйте выполнить mystem.exe с разными параметрами и посмотрите на результаты. Параметры можно комбинировать, например, так:
mystem.exe input.txt output.txt -l -c -s -i -w
или даже так
mystem.exe input.txt output.txt -lciw
Или как захочется, в зависимости от ваших задач. Вот тут можно посмотреть, что получается, если по-разному комбинировать параметры.
Хорошо, мы привели слова в книге к начальной форме. Напомните, для чего вообще все это было нужно?
Давайте напишем mystem такую команду:
mystem.exe input.txt output.txt -wld
Параметры такие: -w обработает только слова из встроенного словаря, -l выпишет только начальные формы слов (леммы), -d попытается снять омонимию.
Получился удобный список слов в начальной форме. Теперь можно закрыть mystem. В блокноте замените фигурные скобки в файле output.txt на пробелы (Правка → Замена), так будет удобнее. Сейчас начнем подсчитывать частоты слов и находить их контексты, устойчивые и не очень.
Как подсчитать, какие слова встречаются реже, а где — чаще?
Для количественных исследований текста есть программа Antconc. Рекомендуем её скачать и открыть в ней файл output.txt (кнопка File → Open File(s)), а затем перейти на вкладку word list и нажать внизу кнопку start. Программа выведет список слов из книги, отсортированных по частоте. Поскольку мы заранее привели все слова к начальной форме, можно не беспокоиться, что «стол» и «столы» попали в разные строчки рейтинга.
Это новое представление данных из книги уже можно изучать и делать выводы. Как мы и ожидали, чаще всего встречаются служебные слова:
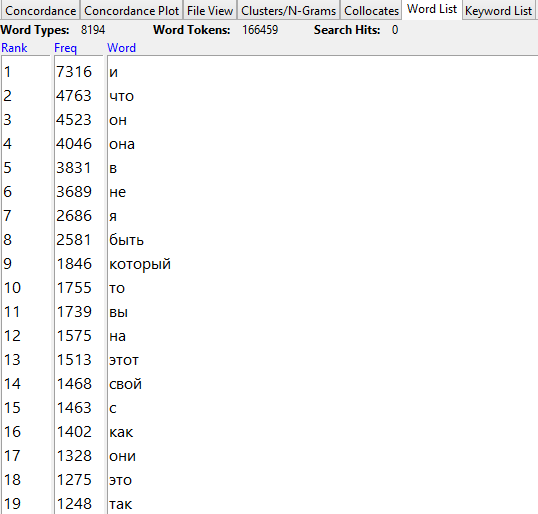
Список слов документа, отсортированных по частоте
Где-то попозже начинаются значащие слова; например, первый по частотности знаменательный глагол — «сказать». Если нажать на него мышью, программа откроет список конкордансов,то есть ближайших контекстов данного слова в тексте (аналогично вкладке concordance tool). Если убрать галочки с пунктов Kwic Sort, программа выдаст контексты слова «сказать» в том порядке, в котором оно встречалось в тексте корпуса, иначе — в алфавитном порядке.
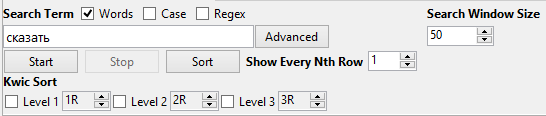
Вот так будет, если убрать галочки:

А вот так — в алфавитном порядке:

Следующая вкладка, Concordance Plot Tool, наглядно покажет, где именно в корпусе встретилось искомое слово. Интересно бывает сравнить разные файлы. Например, «любовь» в input.txt встречается реже, чем в output.txt — потому что в последнем слова «любви», «любовью» тоже приведены к начальной форме «любовь».

Можно посмотреть, где в «Гептамероне» «любовь» встречается в начальной форме, а где — нет. А еще интереснее сравнивать две разные книги или искать по очереди разные слова. Так можно увидеть, что в начале книги больше разговоров или чаепитий, а к концу — больше перестрелок и свадеб.
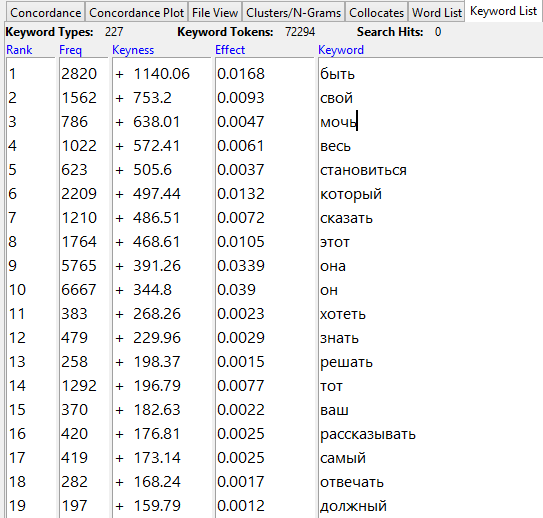
Существует еще и Keyword List — инструмент, показывающий, какие слова встречаются чаще в выбранном корпусе по сравнению с эталонным (reference corpus). Если сравнить, например, наши файлы input.txt и output.txt, приняв input за эталон, то получится, что «самое ключевое», то есть самое относительно частотное слово в output — «быть». Это неудивительно — в исходном (input) файле этот глагол встречается в разных формах и считается за разные слова, а после обработки стеммером (в output) приводится к начальной форме и начинает «встречаться чаще»:
Вкладка «Collocates» по специальным статистическим формулам подсчитывает, с какими словами должно сочетаться искомое слово, если делать выводы о языке, судя только по материалу корпуса. На таком небольшом корпусе, как в нашем примере, выводы этого инструмента не очень информативны.
Наконец, вкладка Clusters/N-Grams покажет, в какие словосочетания слово входило чаще всего. Например, если поставить длину словосочетания (n-граммы) равной трём и поискать n-граммы со словом «любовь», мы увидим, что чаще всего встречается «любовь к она», затем — «любовь к вы», «любовь который я», «любовь к бог», и только потом — «любовь к он». Конечно, все слова приведены к начальным формам и поэтому смотрятся немного нелепо. Но на основе этого распределения уже можно предположить, что «Гептамерон» — скорее о любви к женщине, чем о любви к Богу или к мужчине.
Итоги
Мы узнали, что существует программа mystem, ей можно «скормить» текстовый файл и получить файл со словами в начальной форме. Можно даже предположить грамматические признаки; в статье мы не разбирали работу с ними, но знайте, что это параметр -i.
После обработки стеммером файл можно использовать в antconc — программе, которая умеет строить частотный список всех слов в корпусе, показывать конкордансы (ближайшие контексты слова), отображать, где в документе встретились слова, выдавать самые частые н-граммы с данным словом или показывать «ключевые слова» документа по сравнению с другим документом.
В antconc можно загружать не только тексты после обработки стеммером. Интересные выводы можно получить, работая с обычной книгой или с целой коллекцией.
Что именно делать дальше, решать вам 🙂 Попробуйте узнать, какие слова являются ключевыми для первой части «Властелина Колец» относительно корпуса из всех трех частей. А если не стеммировать слова? Посмотрите, каких прилагательных больше в Винни-Пухе: мужского или женского рода? (Для этого придется разобраться с грамматической информацией в mystem). Или может, вам всегда хотелось узнать, в какой части «Острова сокровищ» чаще упоминается ром? Действуйте!



