
Диффузионные модели: от шума к данным
Прежде чем перейти к генерации видео, необходимо понять, как происходит генерация изображений, поскольку видео — это по сути набор кадров, где каждый кадр является обычным изображением.
На данный момент для генерации изображений используют диффузионные модели. Диффузионные модели позволяют генерировать разные виды данных: изображения, звук, тексты и многие другие. Этот класс моделей основывается на идее, что генерация происходит из крайне зашумлённых данных путём постепенного удаления шума.
Рассмотрим эту идею на примере изображений. К изображению можно постепенно добавлять шум — в какой-то момент шума станет настолько много, что от исходного изображения не останется ничего, и оно превратится в шум. Процесс постепенного зашумления называется прямым диффузионным процессом.

Иллюстрация прямого (слева направо) диффузионного процесса и обратного диффузионного процесса (справа налево). Источник
Есть и обратный диффузионный процесс, когда из сильно зашумлённого изображения постепенно восстанавливается исходное. Именно этому процессу обучаются диффузионные модели.
На каждом шаге обучения модель получает на вход изображение из обучающей выборки, к которой добавлен шум определённой интенсивности (интенсивность выбирается случайно из заранее заданного диапазона на каждом шаге). Задача модели на выходе вернуть оригинальное изображение без шума.
После обучения генерация изображений происходит следующим образом: на первом шаге модели подаётся случайный шум, модель возвращает модифицированный шум меньшей интенсивности, на втором шаге модели подаётся выход модели с первого шага и так далее. То есть на каждом шаге модель убирает определённую долю шума из текущего входа и тем самым генерирует более «чистое» изображение.
Как можно заметить, диффузионная модель сопоставляет произвольному шуму произвольное изображение. Для того чтобы обучить модель генерировать не произвольные изображения, а соответствующие текстовым описаниям, модели помимо зашумлённого изображения подаётся на вход также его текстовое описание. Таким образом модель учится использовать информацию из текстового описания для удаления шума.
Ускоряем диффузионные модели: латентные представления вместо картинок
Процесс генерации изображений требует нескольких запусков модели (для первых диффузионных моделей требовалось около 500–1000 шагов), из-за этого генерация получается медленной и ресурсозатратной. Чтобы сделать этот процесс более эффективным, диффузионные модели обучают не на исходных изображениях, а на их латентных представлениях.
Латентные представления — это крайне сжатые и информативные представления данных. Они получаются с помощью автоэнкодеров. Автоэнкодер — это специальный вид нейросетей, которые обучаются эффективно сжимать данные в представления, из которых впоследствии можно восстановить исходные данные. Об автоэнкодерах мы подробно рассказывали ранее.
Для наглядности: для описания изображения размера 224 x 224 пикселей в профиле RGB необходимо 224 x 224 x 3 = 150528 чисел, а латентное представление такого размера описывается 4096 числами, то есть оно почти в 37 раз компактнее.
Именно поэтому диффузионные модели обучают на латентных представлениях изображений: чем компактнее входные данные модели, тем модель быстрее. Процедура обучения та же — только шум при обучении добавляется к представлениям изображений, и модель учится возвращать их менее зашумлённые версии. Процесс генерации также состоит из нескольких шагов, однако после последнего шага полученное латентное представление подаётся на вход декодеру, который восстанавливает из него изображение.
Генерация видео: видео — это набор картинок
Генерация видео сводится к генерации каждого кадра, поэтому в этой задаче эффективность ещё более важна. Например, одноминутное видео с 24 кадрами в секунду (стандартная частота кадров для фильмов) содержит 60 * 24 = 1440 изображений!
Итак, обучение Sora устроено следующим образом:
- Видео из обучающей выборки сжимается в компактное представление с помощью заранее обученного автоэнкодера (используется энкодер).
- К компактному представлению из первого шага добавляется шум.
- Зашумлённое представление из предыдущего шага с текстовым описанием видео подаётся на вход диффузионной модели. Модель возвращает представление, очищенное от шума. Далее происходит шаг обучения модели.
Про то, как обучаются модели машинного обучения, можно прочитать в нашем материале.
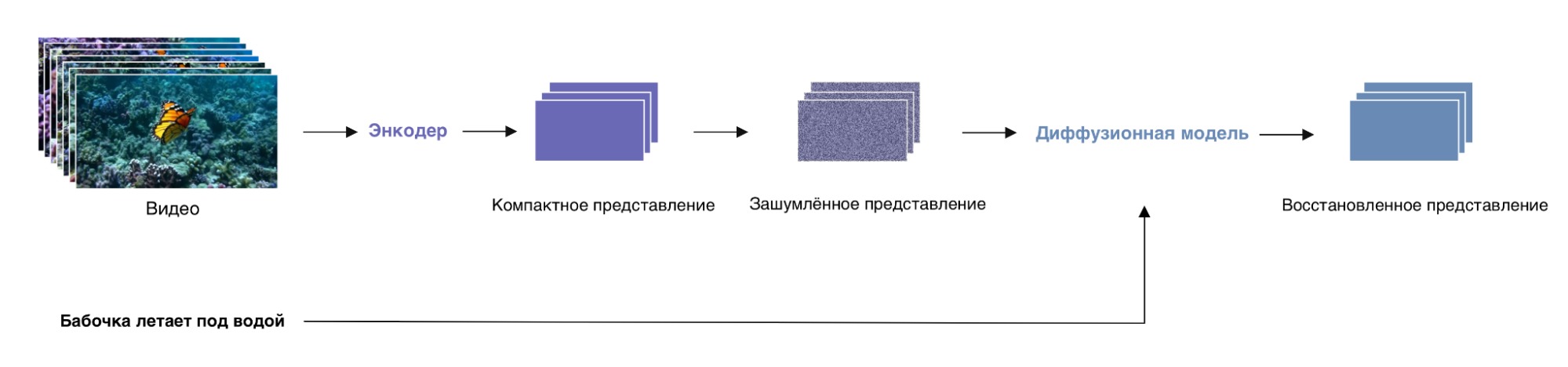
Схема процедуры обучения Sora
Генерация происходит так:
- На вход диффузионной модели подаётся шум и текстовое описание видео. Модель возвращает менее шумное представление видео.
- Полученное представление из предыдущего шага c текстовым описанием подаётся на вход модели.
- Модель возвращает менее шумное представление.
- Шаги 2–3 повторяются N раз.
- Итоговое представление подаётся на вход автоэнкодеру (используется декодер), который возвращает видео.

Схема генерации Sora
Что умеет и не умеет Sora?
Демонстрации всех нижеперечисленных свойств модели доступны на сайте OpenAI.
- Sora способна генерировать видео с разным соотношением сторон и разного разрешения. Максимальная длина видео на данный момент составляет одну минуту.
- Помимо генерации, Sora может продолжать уже существующее видео: и вперёд, и назад по времени. Для этого на вход модели, кроме обычного шума, подают зашумлённое представление существующего видео.
- Sora может генерировать видео виртуальных миров: например, она может сгенерировать геймплей Minecraft. Это способность модели в будущем может быть использована в игровой индустрии.
- Sora может симулировать некоторые физические процессы — например, движение волн или отражение света. Однако многие процессы модели пока не даются.
Последнее свойство вызвало большую дискуссию среди исследователей. Некоторые из них считают, что модели для генерации видео потенциально могут стать полноценными «моделями мира», которые можно будет использовать для симуляций разных процессов вместо расчёта сложных уравнений из физики. Другие же полагают, что обучения генерации видео недостаточно для того, чтобы модель выучила законы физики. Какое из этих мнений правильное — мы узнаем в будущем.
Источник: Video generation models as world simulators [Электронный ресурс]. URL: https://openai.com/research/video-generation-models-as-world-simulators (дата обращения: 06.03.2024).

