
Сбор базы данных
Сервис Voyant Tools [1] создан для анализа текстовых данных в Digital Humanities. Цифровые гуманитарии, специализирующиеся на востоковедении, применяют Voyant Tools и к иероглифическим текстам. В этом кратком руководстве мы рассматриваем возможности использования Voyant Tools для анализа текстов на японском языке на примере комментариев к видео на YouTube.
Как добывались комментарии
Данные для анализа получены при помощи парсера YouTube Data Tools, модуля сбора данных о видео и комментариям к нему [2]. Модуль собирает следующую информацию:
- Tab-файл с основной информацией и статистикой видео
- Tab-файл с количеством комментариев каждого пользователя
- Tab-файл с комментариями каждого пользователя
- GDF-файл с сетью взаимодействия всех комментаторов видео
Наш набор данных включает комментарии десяти самых просматриваемых видео канала японского студента Сюдзи [3], обучающегося в одном из университетов Санкт-Петербурга. Канал освещает повседневную жизнь Сюдзи в России, а комментаторы — японцы и россияне — обсуждают быт, образование и получение культурного опыта в новой стране. В наборе данных 443 комментария (18634 знака без пробелов), чего достаточно для демонстрации возможностей Voyant Tools для анализа японского текста.
Смотрим на облака слов … и видим проблему
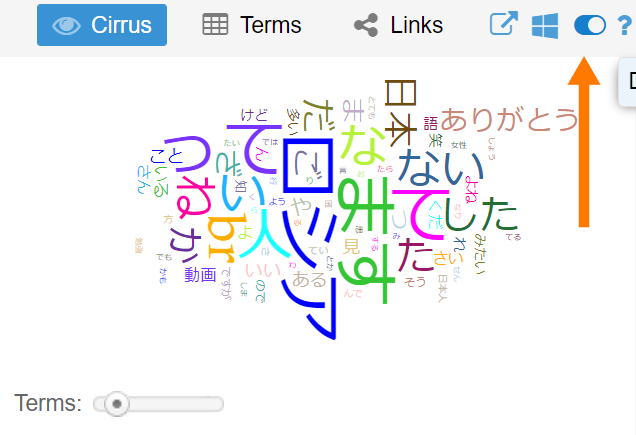
После открытия текста в Voyant Tools мы видим большую частоту “слов”, которые появились в блоках Cirrus (облако слов), TermsBerry (визуализация, которая показывает связи слов друг с другом), и Summary (статистика корпуса). Однако большую часть информации составляют отдельные буквы азбуки хирагана и катакана, которые не являются словами как таковыми, за исключением центрального слова, написанного катаканой – Россия (ロシア). В случае комментариев на YouTube в облаке слов мы видим также окончания глаголов: масу (ます), тэ (て), та (た), най (ない), ттэ (って), сита (した) и наиболее частый тэг для обозначения перевода строки br, который получен из комментариев на YouTube.

Способ сегментирования текста на японском языке при помощи Voyant Tools похож на принцип работы плагина Fugashi [4], работающего на языке программирования Python как токенизатор и средство морфологического анализа. В токенизации японского языка есть определенные трудности из-за отсутствия пробелов в тексте и сочетания двух азбук и иероглифов. В наборе текста из комментариев также часто встречаются заключительные частицы, характерные для разговорной японской речи. Среди восьми наиболее встречаемых элементов – частица на (な, восклицание) и нэ (ね, не так ли) с 102 и 89 употреблениями в тексте соответственно.
Обращаем внимание на большое количество японской азбуки для исконно японских слов хираганы и слабо выраженное употребление кандзи (иероглифов), которые могут сразу обозначить тематику анализируемого текста. Также мы видим частицы-связки и частицы, дополняющие эмоциональное выражение (например, нэ ね, йо よ, на な, со: そう).

Это могло означать невозможность использования Voyant Tools для анализа текстов на японском языке. Например, исследователь Лю Ван [5] столкнулась с трудностями китайской пунктуации и провела очистку данных перед смысловым анализом. Мы хотели сохранить вспомогательные глаголы и частицы на хирагане для дальнейшего анализа, но пришли к выводу, что очистка данных позволит изучить корпус текста без потери смысловых данных.
Чистим данные от стоп-слов, этап I
Эту проблему решает в статье [6] известный японский исследователь цифровых гуманитарных наук Нагасаки Киёнори.
Нагасаки К. утверждает, что анализ вспомогательных глаголов и частиц при помощи Voyant Tools может дать полезную информацию о стиле автора, но это также не позволяет нам с легкостью анализировать текст из-за избыточности найденных частиц. Из-за этого преимуществ удаления вспомогательных глаголов и частиц из текста не меньше, чем недостатков.
Нам следует игнорировать статистику, которую предоставляет Voyant Tools об общем количестве слов, общем количестве уникальных словоформ и среднем количестве слов в предложении и удалить все вспомогательные глаголы и частицы, что поможет на качественно новом уровне проанализировать текст. Исследователь может добавить список стоп-слов (нажмите “Define options for this tool” и далее “Edit list”, чтобы добавить стоп-слова), Рис. 3-4. Стоп-слова – это список слов, которые Voyant Tools не должен учитывать, его можно создать самостоятельно и загрузить в сервис. Также можно вручную дополнить предустановленный список в настройках Voyant Tools.

Нагасаки К. предоставляет список стоп-слов [6], который ученый применял к текстам на японском языке. Стоп-лист содержит служебные частицы, отдельные буквы японских азбук, цифры и другие несмысловые элементы. Мы использовали этот список и заметили значительное улучшение выводимых результатов.

Чистим данные от стоп-слов, шаг II
Далее важно добавить дополнительные стоп-слова, включающие вспомогательные слова и частицы, часто используемые в японском интернет-дискурсе – w и ww (улыбка, смайлик), нэ (ぬ, не так ли), ттэ (って, употребняется, например, когда говорящий хочет поведать об услышанном ), тта (った, разговорный вариант прошедшего времени). Более того, мы включили в стоп-лист все единичные буквы хирагана и такие частицы как br, которые не появляются в видимом тексте комментариев, а только в собранных парсером метаданных. После исключения данного списка из базы данных мы смогли увидеть некоторые элементы структуры текста. Расширенный список стоп-слов доступен в Google Docs [7] и может быть использован в дополнение к списку Нагасаки К.


Что получилось после очистки
В нашем примере заметно преобладание таких слов как Россия (ロシア), Япония (日本), человек (人), слова благодарности («спасибо», ありがとう).
Включив другой метод визуализации данных в Voyant Tools – TermsBerry — мы видим, что слово «Россия» обычно связано с людьми (人), языком ( 語), а также девушками (女性). У слова «человек» (人) есть явные связи со словами «девушка» (女性), «мужчина» (男性), «хороший» (いい), «много» (多い), «хочу увидеть» (みたい).

Слова благодарности («спасибо», ありがとう) и иероглифы, используемые для обозначения улыбки или смайлика (笑) не образуют смысловых связок с другими словами. Однако можно заметить суть обоюдно зависимых слов, например, «что-нибудь» (なんか), «хочу увидеть», «впечатления» (印象), «нравиться» (好き), «почему» (なんで). Данный блок слов показывает вопросы зрителей к автору канала.
Итак, средства Voyant Tools могут хорошо работать для анализа корпуса текста на японском языке в том случае, когда исследователь проводит подготовительную работу с данными, а также учитывает, что не все средства анализа данных в Voyant Tools будут правильно обрабатывать японский язык. Лучшие результаты получатся после подготовки текста, его очистки, применения списка стоп-слов и ручного выбора подходящих средств визуализации данных.
Источники
- Sinclair, S., Rockwell, G., (2012). Voyant Tools (web application), voyant-tools.org
- The Digital Methods Initiative
- Shuji Vlog / ロシアンカナル
- Fugashi – Cython wrapper for MeCab, a Japanese tokenizer and morphological analysis tool. Pypi.org/project/fugashi
- Wang L. (2021). Changing Role of Textile Making: Text Analysis of Digitized “Lienü zhuan” with Voyant Tools (Part I)
- Nagasaki, K. (2016). 簡易テクスト分析にVoyant-Toolsもいかがでしょうか?
- Stoplist Japanese. Voyant Tools



