
Оценивая качество машинного перевода (МП), человек сопоставляет различные аспекты перевода: адекватность, точность и естественность. Делать это можно разными способами, но все они занимают много времени — недели и даже месяцы! — и стоят довольно дорого. Результаты такой работы почти невозможно использовать повторно. Для разработчиков систем МП это проблема — ведь им нужно ежедневно отслеживать изменения в системе и очень быстро отсеивать неудачные решения.
Как оценить качество перевода автоматически? Гипотеза такова: чем ближе МП к профессиональному человеческому, тем он лучше. В 2002 году команда исследователей из Научно-исследовательского центра IBM имени Томаса Дж. Уотсона предложила способ измерения близость МП к одному или нескольким эталонным переводам, выполненным человеком.
Для оценки качества машинного перевода предложили использовать числовую метрику «точности перевода» и корпус эталонных переводов высокого качества. Собственную метрику точности — BLEU (BiLingual Evaluation Understudy) — они создали на основе показателя вероятности ошибок, используемого для оценки качества распознавания речи. Этот показатель адаптировали для применения с несколькими эталонными переводами и учёта различий в выборе и порядке слов.
Основная идея метрики BLEU заключается в подсчете совпадений фраз переменной длины (т.е. N-грамм, о которых уже рассказывал «Системный Блокъ») в оцениваемом и эталонном переводах.
«Правильных» переводов одного и того же предложения может существовать сколь угодно много. Они будут отличаться друг от друга выбором лексических единиц и порядком слов — и всё равно человек сможет точно сказать, где хороший перевод, а где плохой. Рассмотрим два варианта машинного перевода с китайского языка:
Вариант 1: Это руководство к действию, которое гарантирует, что военные всегда подчиняются командам партии.
Вариант 2: Это гарантирует, что войска будут всегда слышать руководство, направленное этой партией.
Хотя предложения передают примерно одинаковый смысл, они заметно отличаются по качеству. Для сравнения приведем три «человеческих» перевода:
Эталон 1: Это руководство к действию, которое гарантирует, что военные всегда будут подчиняться командам Партии.
Эталон 2: Это руководящий принцип, который гарантирует, что вооруженные силы всегда находятся под командованием Партии.
Эталон 3: Практическое руководство для армии — всегда прислушиваться к указаниям партии.
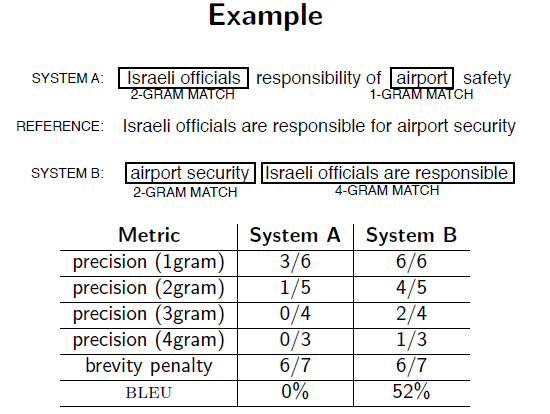
Очевидно, что первый вариант МП имеет много общих слов и фраз с этими тремя эталонами, в то время как второй — нет. Следует отметить, что в Варианте 1 присутствует «руководство к действию» (см. Эталон 1), «которое» (см. Эталон 2) «гарантирует, что военные» (см. Эталон 1) «всегда» (см. Эталоны 2 и 3) будут подчиняться «командам» (см. Эталон 1) «партии» (см. Эталон 2). Второй вариант МП демонстрирует гораздо меньшее количество совпадений.
Основная задача при разработке BLEU состояла в том, чтобы сравнивать N-граммы машинного перевода с N-граммами эталонного перевода и посчитать количество совпадений. Такие совпадения не зависят от порядка слов. Чем их больше, тем лучше предъявляемый перевод. Естественно, что при сравнении N-граммных соответствий в каждом эталонном и машинном переводах программа присвоит Варианту 1 более высокую оценку.
Самая примитивная версия метрики BLEU будет считать N-граммы из одного слова (униграммы) — проще говоря, сравнивать переводы по встречаемости отдельных слов, а не их цепочек. Находим которые встречаются в любом из эталонных переводов, а затем делим на общее количество слов в переводе, выполненном машиной.
К сожалению, системы МП могут выдавать слишком много «подходящих» униграмм, при этом перевод окажется избыточным, похожим на словоблудие. Метрика BLEU учитывает, что в эталонных переводах могут быть использованы разные переводы для одного и того же исходного слова. Рассмотрим пример.
Вариант 1: Я всегда неизменно постоянно делаю это.
Вариант 2: Я всегда делаю это.
Эталон 1: Я всегда делаю это.
Эталон 2: Я неизменно делаю это.
Эталон 3: Я постоянно делаю это.
Видим, что первая система МП способна вспомнить больше слов из примеров, на которых ее обучали, но предложенный первый перевод явно хуже второго. Для решения этой проблемы исследователи предложили «закрывать» слово эталона для дальнейшего поиска после того, как ему будет найдено соответствие в машинном переводе. Они придумали модифицированную оценку точности униграмм, которая рассчитывается следующим образом:
- считают максимальное число вхождений униграммы в любом из эталонных переводов;
- общее число вхождений соответствующей униграммы в оцениваемом тексте сокращают до максимальной частотности униграммы в эталоне, если оно превышает этот показатель;
- прибавляют эту величину к максимальному числу вхождений униграммы в эталонах;
- делят на общее число вхождений слова в оцениваемом переводе.
Вычисление модифицированной точности n-грамм исследует, таким образом, два аспекта перевода: адекватность и естественность. Если в переводе используются те же униграммы, что и в эталонном тексте, то он соответствует критерию адекватности. Чем длиннее соответствующие эталонным n-граммы, тем оцениваемый перевод естественнее.
Чтобы убедиться в том, что модифицированная оценка точности N-грамм различает хорошие и плохие переводы, исследователи вычислили модифицированную точность на выходе у перевода, выполненного человеком (хорошего), и обычного перевода, выполненного в системе МП (плохого), используя по 4 эталона для каждого из исходных предложений.
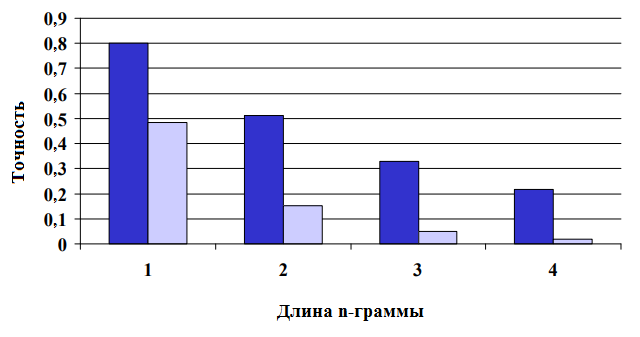
Диапазон метрики BLEU составляет от 0 до 1. Немногие переводы получают оценку 1, если они не совпадают с эталонным переводом. По этой причине даже «человеческий» перевод не обязательно получит 1. Чем выше степень соответствия эталону, тем выше оценка.
Как видно из рисунка, разница в точности увеличивается, когда мы переходим от сравнения точности униграмм к сравнению точности 4-грамм. Исследователи пришли к выводу, что любая отдельно взятая оценка точности n-грамм поможет отличить хороший перевод от плохого. Однако наибольшую эффективность демонстрируют комбинированные методы оценки. Именно так используют BLEU сегодня: измеряется точность для N-грамм разной длины (униграммы, биграммы, триграммы и т.д.), а затем высчитывается средняя точность:
Чтобы система была действительно полезной, она должна видеть разницу между переводами, не сильно отличающимися по качеству. Более того — уметь различать два разных по качеству «человеческих» перевода. Именно последнее требование и обусловливает актуальность метрики в условиях, когда качество машинного перевода постепенно приближается к качеству перевода, выполненного человеком.
Также можно узнать о современных подходах к улучшению нейронного машинного перевода тут.
Материал подготовлен совместно с группой переводческих компаний AKM Translations (www.akmw.ru).



