Если вбить в поисковике запрос типа «пожрать в Москве», вы получите много результатов, в которых вообще нет слова «пожрать» — вместо этого там будут «поесть» , «есть», «еда», «кафе» и т.п. Как поисковик понимает, что нужно показать все это? Хитростей тут много, но ключевая технология под капотом — расширение поискового запроса близкими по смыслу словами. Как работают такие системы?
Возьмем слова «лампочка» и «ламочка» — они похожи на вид, хотя значат разное. А «лампочка» и «светильник» — совсем не похожи, хотя по значению очень близки. Конечно, проще всего увидеть эту близость в словаре, но компьютеры-то их читать не умеют… Да и нет такого толкового словаря, который включал бы все современные слова и словечки, употребляемые в интернете.
Спасают контексты употребления слов. Если взять много-много текстов, то они у лампочки и светильника будут в целом очень похожи. Лампочка на 100 ватт — светильник на 100 ватт, перегорела лампочка — перегорел светильник, выключи лампочку — выключи светильник…. А вот ламочку или лапочку выключить нельзя. Эта идея — что значение слова хранится в сумме его контекстов — по-научному называется «дистрибутивная семантика». Именно при помощи дистрибутивных моделей компьютеры научились понимать и сравнивать смыслы слов.
Набор таких моделей для русского языка есть на сайте RusVectores.ru, сделанном школой лингвистики НИУ ВШЭ и университетом Осло. Там можно, например, найти ближайшие по смыслу аналоги для любого произвольного слова — исключительно на основе контекстного сходства в огромной массе текстов. Алгоритм при этом ничего не знает про «значения» в человеческом, толково-словарном понимании этого слова — но это не мешает. Вот так выглядит топ для слова «филолог»:
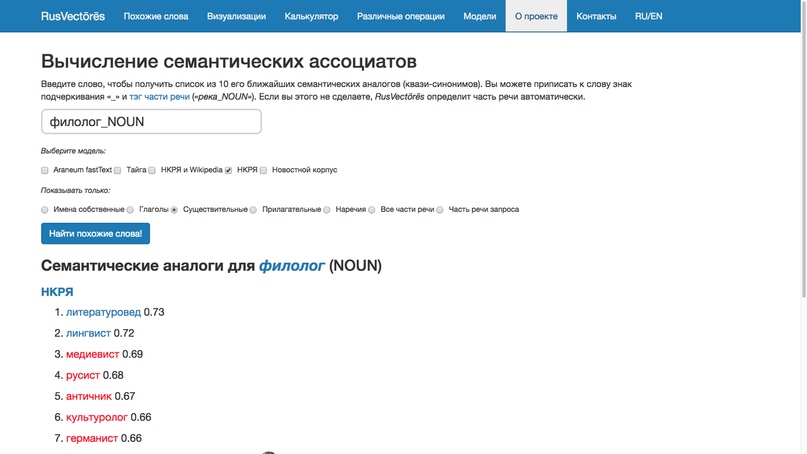
Подробнее о RusVectores:



