
Алгоритмы искусственного интеллекта позволяют генерировать текст достаточно убедительный для того, чтобы обмануть обычного человека. Они используют для этого языковые модели, на основе которых компьютер может научиться предсказывать следующее слово в заданном контексте.
Так, исследователи из OpenAI недавно продемонстрировали алгоритм, способный порождать реалистичные текстовые отрывки. Они загрузили огромный массив текстов в модель машинного обучения, которая научилась перенимать статистические последовательности слов и на их основе генерировать новый текст, едва отличимый от текста, написанного человеком. Опасность этой технологии заключается в том, что она открывает большие возможности для поточного создания фейковых новостей, отзывов или аккаунтов в социальных сетях.
К счастью, алгоритмы ИИ теперь могут и распознавать фейковый текст.
Исследователи Гарвардского университета и лаборатории MIT-IBM Watson AI Lab на основе открытого OpenAI кода разработали инструмент для распознавания текста, сгенерированного с помощью искусственного интеллекта — т.н. «гигантскую тестовую площадку языковых моделей» (the Giant Language Model Test Room, GLTR). Идея разработчиков состояла в том, чтобы использовать те же модели, что и генераторы текста на основе ИИ. Новый инструмент способен определить, являются ли слова в тексте слишком предсказуемыми для того, чтобы быть написанными человеком.
GLTR анализирует текст с точки зрения вероятности появления одних слов после других и для визуализации работы алгоритма подсвечивает их разными цветами. Так, статистически наиболее вероятные слова (топ-10) подсвечиваются зеленым; менее вероятные — желтым (топ-100) и красным (топ-1000); наименее — фиолетовым. При тестировании на текстовых отрывках, написанных с помощью алгоритма OpenAI, GLTR находит очень большую предсказуемость.
Например, если загрузить в GLTR уже ставший известным текст модели GPT-2 о единорогах, который, за исключением первого предложения, был полностью сгенерирован ИИ, то инструмент выдаст следующую картину:

В отрывке текста, следующем за первым предложением, нет ни одного слова, выделенного фиолетовым, и всего несколько — красным. Большинство же слов имеют зеленую или желтую подсветку, что является мощным индикатором искусственно сгенерированного текста.
А вот пример из реальной жизни — отрывок из статьи газеты The Washington Post, которая использует алгоритмы для освещения спортивных мероприятий и предвыборной кампании (подробнее см. тут). Легко заметить, что почти весь текст, за исключением имен собственных (имен игроков и названий команд), подсвечен зеленым и желтым.

Реальные новостные статьи и отрывки из научных работ содержат больше сюрпризов.
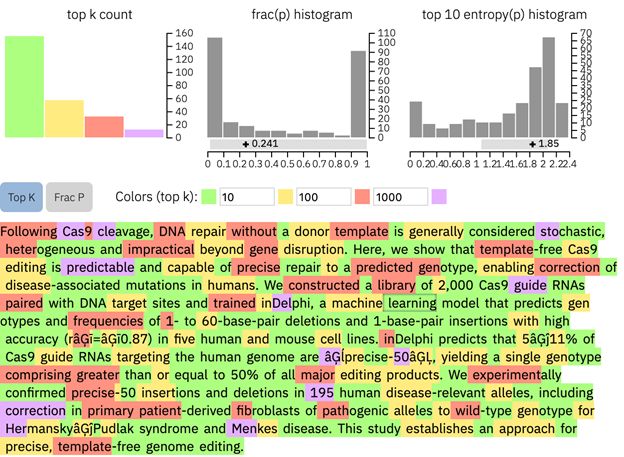
Так, при анализе статьи о предсказуемости результата CRISPR редактирования, опубликованной в журнале «Nature» [1], инструмент выдает значительно большее количество красных и фиолетовых слов, что является маркером текста, написанного человеком.
Исследователи, стоящие за GTLR, провели также интересный эксперимент. Они попросили студентов Гарварда распознать текст, написанный ИИ — сначала самостоятельно, а затем с помощью разработанного ими инструмента. Выяснилось, что студенты способны распознать только половину всех фейков самостоятельно, а вот с помощью инструмента — уже 72%. «Наша цель — создать системы для сотрудничества человека и искусственного интеллекта», — говорит аспирант Себастьян Германн, один из разработчиков GLTR.
Если вам стало интересно, можете сами протестировать систему распознавания автоматически сгенерированных текстов здесь.
Источники:
- Catching a Unicorn with GLTR: A tool to detect automatically generated text
- A new tool uses AI to spot text written by AI
- Predictable and precise template-free CRISPR editing of pathogenic variants
[1] Predictable and precise template-free CRISPR editing of pathogenic variants



