
На популярных сайтах вроде «Циана» и «Авито» ежедневно публикуются десятки объявлений о сдаче квартир. Помимо стандартных полей «адрес», «количество комнат», «расстояние до метро» и т. п., на странице объявления есть раздел, где хозяева или риелторы в свободной форме описывают квартиру и оставляют любые другие комментарии, в том числе требования к жильцам. Это могут быть как конкретные требования «без животных, не больше двух человек», так и забавные пожелания «только адекватным и приличным людям» или завуалированная дискриминация по национальности вроде «лицам южного происхождения не звонить».
Такие неструктурированные требования могут быть выражены любыми словами или цифрами и содержать любые опечатки. Выделяя их с помощью жестких шаблонов (регулярных выражений, словарей и т. п.), можно многое упустить. Поэтому для поиска нужной информации в объявлениях мы решили применить LLM.
Какой датасет будем анализировать?
Чтобы изучить, что пишут в объявлениях на российских сайтах, и посчитать статистику отдельных слов и выражений, был нужен достаточно большой корпус текстов. Где такой корпус взять? Первая мысль, которая приходит на ум — воспользоваться навыками парсинга и скачать любые тексты с «Циана» или «Авито». Но не все так просто: эти сайты очень строго ограничивают любые автоматические запросы и защищают персональные данные владельцев объявлений, так что обычные питоновские парсеры оказываются неэффективны.
Другой (не менее очевидный при поиске данных) путь — посмотреть, нет ли у сайтов готового API. API у таких серьезных сервисов, конечно, есть, но для наших целей они не подходят: в основном их используют риелторы и агентства для анализа статистики только по собственным объявлениям.
Есть в интернете и готовые инструменты для анализа этих сайтов, созданные энтузиастами, например cianparser. Эта Python-библиотека позволяет анализировать объекты недвижимости по очень многим параметрам, но, к сожалению, не извлекает из объявлений описания, которые нам нужны.
Остается последний путь: найти уже собранные данные в открытом доступе. Мы воспользовались датасетом Avito Demand Prediction Challenge с Kaggle, собранным для ML-соревнования в 2018 году. В датасете были объявления не только по недвижимости, и мы отобрали только те, что подходят под три фильтра одновременно — «Квартиры, Сдам, На длительный срок». Всего получилось 14 557 текстов. Самое главное, что датасет содержал колонку description — описание квартиры, которое мы и будем анализировать. Чтобы получить доступ к данным, нужно было принять лицензионное соглашение: в объявлениях содержится информация о собственности реальных людей, поэтому в статье публиковать тексты целиком мы не будем.
Что будем искать?
Для анализа мы выбрали несколько параметров, о которых обычно пишут в объявлениях.
- Национальность. Правда ли, что чаще всего сдают «только славянам», или будут слова о том, что хозяева рады всем?
- Качества характера и привычки. Жильцов с какими привычками и качествами чаще всего ищут? Правда ли, что все требования будут формальными, чтобы каждый мог оценить, подходит ли он? Или будет много абстрактных слов (порядочные, культурные и т. п.)?
- Состав жильцов. Сколько жильцов и какого пола охотнее всего выберут хозяева? Будет ли одинаково легко снять квартиру семье и одиноким людям, мужчинам и женщинам?
- Возраст жильцов. Какой возраст жильцов предпочтительнее? Действительно ли хозяева часто ищут людей от 25 лет, или есть другие границы?
- Наличие детей. Насколько просто снять квартиру, если у вас есть дети? И зависит ли что-то от их возраста?
- Наличие животных. Как в целом арендодатели относятся к жильцами с животными, какие условия ставят?
Несмотря на то, что параметры «с детьми» и «с животными» в объявлении можно задать и с помощью автоматических фильтров, нам было интересно, сможет ли модель выделить именно текстовые подробности — про возраст детей, про то, к каким именно животным хозяева относятся лояльнее и т. д.
Как будем искать?
Чтобы LLM выполнила то, что мы хотим, необходимо задать ей правильную инструкцию — промпт. Помимо того, что именно извлекать, можно указать формат, добавить примеры, задать «роль» модели и ограничения. Приведем точный текст промпта, который мы использовали:
Ты — эксперт по недвижимости. Извлеки из текста требования к жильцам в JSON. Поля:
— национальность жильцов: требования к национальности (кому можно или нельзя снимать);
— качества жильцов: требования к характеру/привычкам;
— состав жильцов: состав жильцов/пол;
— возраст жильцов: возраст;
— дети: дети (можно/нельзя/возраст);
— животные: животные (можно/нельзя/какие);
Если информации нет — ставь ‘0’. Не выдумывай.
Формат JSON мы выбрали, чтобы потом было удобно анализировать полученные данные и считать статистику. Для той же цели мы просим модель единообразно кодировать отсутствие информации, если ничего не будет найдено. Указания вроде «не выдумывай» должны снизить количество галлюцинаций.
Теперь к самой модели. Не секрет, что качество работы модели зависит от ее размера — величины обучающего датасета и количества параметров самой нейросети. Но для запуска больших и сложных LLM нужны соответствующие вычислительные мощности, так что модель в нашем любительском исследовании подбиралась по таким критериям:
- достаточно умная (делает то, что нужно, и не сильно галлюцинирует);
- бесплатная;
- хорошо работает с русским языком;
- запускается в Google Colab на бесплатной GPU T4 (Colab — это бесплатная облачная платформа от Google для программирования на Python прямо в браузере. Она основана на Jupyter Notebook и не требует установки ПО на компьютер, предоставляя доступ к видеокартам (GPU), в том числе бесплатным, для задач машинного обучения и анализа данных);
- работает достаточно быстро: примеров в датасете около пятнадцати тысяч, а в бесплатной версии Colab можно непрерывно работать не более 12 часов.
Подходящим решением стала модель Qwen2.5-3B-Instruct-Q4_K_M.gguf. Qwen2.5 — линейка больших языковых моделей от Alibaba. «3B» означает примерно 3 млрд параметров. Instruct значит, что модель дообучена как чат‑ассистент: лучше следует инструкциям, умеет вести диалог, генерировать структурированный вывод (JSON, списки и т. п.) и поддерживает много языков, в том числе русский. Веса модели сжаты примерно до 4 бит на параметр, из-за чего она занимает в разы меньше памяти и работает быстрее, чем оригинал, при этом качество сильно не падает. GGUF — это формат хранения модели, оптимизированный для запуска на CPU и GPU.
Обработав данные за 5 часов, мы получили таблицу результатов, где одно объявление — одна строчка.
Доверяй LLM, но проверяй
Чтобы оценить, насколько хорошо наша модель отработала с нашим промптом на данных Авито, мы подсчитали точность и полноту найденных результатов.
Точность мы вычисляли стандартным способом: какая доля значений, выделенных моделью, действительно верная, то есть отражает требования, указанные в объявлении. Этот параметр мы оценивали вручную, сопоставляя содержание объявлений, в которых модель хоть что-то нашла, и выделенные значения. Данных по параметру возраста оказалось слишком мало, а по остальным пяти параметрам получились следующие результаты.
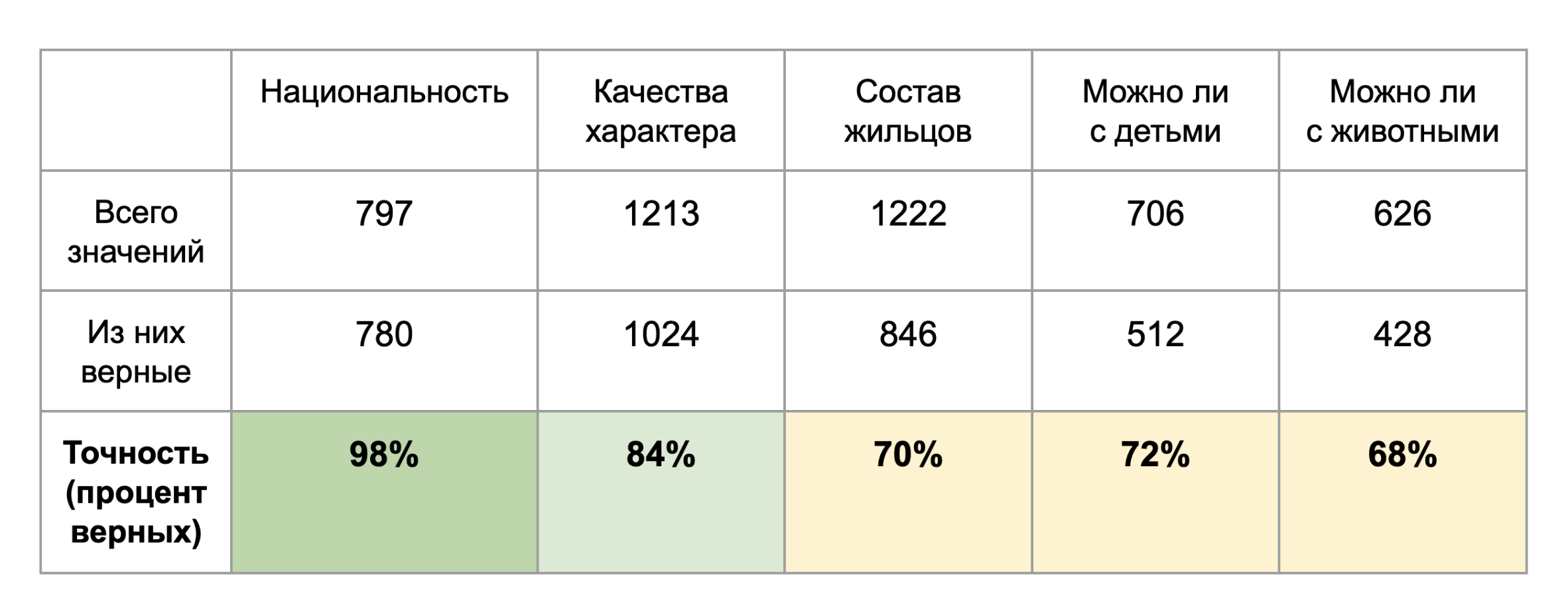
Отличный результат получился по параметру «Национальность»: почти все результаты, найденные моделью, оказались верными. Хороший результат и по параметру «Качества характера»: те значения, которые модель выделяла, оказывались достоверными, было мало галлюцинаций. По остальным параметрам результаты оказались среднего качества: модель либо придумывала, либо путала «да» и «нет». В целом то, что медианная точность модели около 70%, говорит о том, что она вполне подходит для извлечения неструктурированной информации по нашей теме. Возможно, повысить точность можно с помощью детализации промпта или использования более мощной модели.
Чтобы максимально достоверно оценить полноту (долю найденных значений из всех, что нужно было найти), нам бы пришлось найти все нужные значения вручную, а потом посчитать, какой процент из них нашла модель. Вместо этого мы оценили полноту примерно: составили несколько регулярных выражений с теми же паттернами, что уже нашла модель, и посмотрели, как много значений по ним найдется.
Такой способ неидеален: регулярки могут ловить как верные значения, так и ложноположительные. Например, помимо «Россия» в указании на гражданство могло найтись «Россия» в названии кинотеатра или супермаркета неподалеку от квартиры (это становилось понятно только при перечитывании текстов). Регулярки, в отличие от умных моделей, не умеют фильтровать такие вхождения. Для исключения очевидных ошибок мы просмотрели результаты глазами, но они все равно остаются примерными.
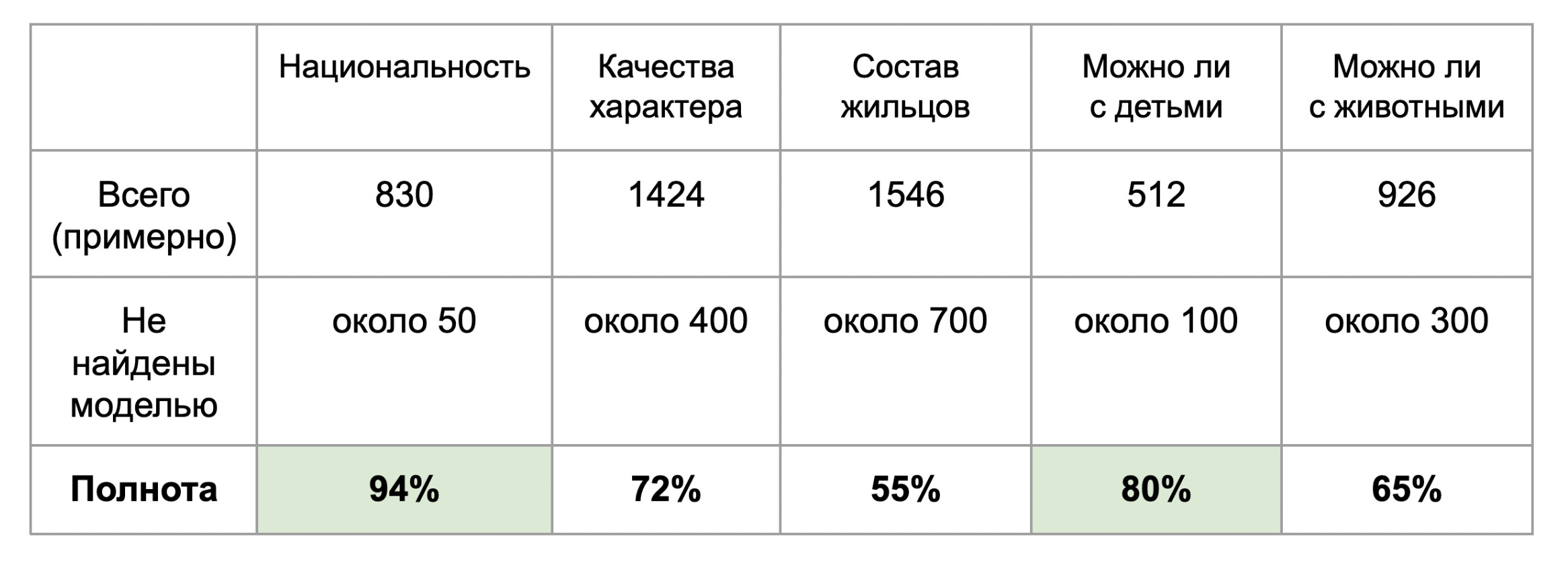
Из получившейся таблицы видно, что модель снова показала хорошее качество по параметру «Национальность». (С такими метриками можно и в прод!) Также радует относительно небольшое количество пропущенных значений по параметру «Можно ли с детьми». Как по подсчетам, так и при беглом чтении результатов, по остальным параметрам модель многое пропускала.
Очевидно, что с такими показателями полноты наше исследование не позволит сделать статистически значимые выводы. Для более серьезного исследования извлечение с помощью модели можно дополнить внимательно составленными регулярными выражениями, словарями и NER. Но мы все же проанализируем найденные моделью значения и покажем, что из них можно узнать много интересного о том, что и как люди пишут в объявлениях.
Можно было и без LLM: требования к национальности
Ожидаемо, про национальность жильцов чаще всего писали, что ищут русских (450 упоминаний), славян (241), граждан РФ (51) или российских (14) граждан, местных (5), с пропиской (13), русскоязычных (2) или даже православных (2).
Не менее ожидаемы цитаты «кавказской национальности/зарубежным гражданам не беспокоить», «кавказцам и азиатам просьба не звонить».
Однако есть и упоминания о том, что подходят любые (7) жильцы или даже нерусские (5), иностранцы (3), «можно лиц из ближнего зарубежья».

Казалось бы, можно было и LLM не применять: дискриминационная фраза «только славянам» — давно известный мем. Стоит отметить, что объявления в датасете не новее 2018 года, а в последние пару лет за использованием подобных формулировок строго следят, за них даже штрафуют. Наше исследование помогает оценить масштабы проблемы в прошлом десятилетии, но было бы очень интересно проанализировать и то, как обстоят дела с дискриминационными формулировками в современных объявлениях. Стали ли тексты более корректными, или просто дискриминация по национальному признаку стала более завуалированной?
Попробуйте соответствовать: требования к характеру и привычкам
Такое разнообразие требований к характеру и привычкам, какое выделила наша модель, заранее не придумаешь и не задашь ни одной регуляркой. Нашлись вполне объективные требования: например, чистоплотность (120), отсутствие вредных привычек (88), аккуратность (74), не курить (22), не пить (5), чистота (8), своевременная оплата (7), соблюдать/ценить чистоту (4), без шумных вечеринок, соблюдать порядок.
Однако встречаются и совершенно абстрактные или откровенно смешные формулировки. Абсолютный лидер — порядочность (754), а также, например, добросовестность (16), интеллигентность (4), разумность, серьезность, воспитанность… неожиданное отсутствие судимости… ищут приличных (16), хороших (6), мирных и культурных людей. Отдельно отметим неоднозначную формулировку, которую модель выделила дословно: пьющих просьба не беспокоить… Ее можно прочитать и как то, что жильцы не должны беспокоить каких-то других пьющих.
Оценку собственной порядочности и разумности оставим тем, кто только собирается искать съемную квартиру, а сами приведем полный список найденных значений, чтобы читатели смогли их подробно изучить.
Придется подстраиваться: состав, возраст жильцов и их животные
Оставшиеся параметры мы рассмотрим вместе, так как они сильно связаны между собой. Данные, извлеченные нашей моделью, показали, что с наибольшей вероятностью вам сдадут квартиру, если вы семья (414 упоминаний) или семейная пара (287). Из одиночек арендодатели предпочитают женщин (79), мужчин-одиночек упоминали реже всего (12).
Про желаемый возраст жильцов писали редко (либо наша модель не смогла выделить эту информацию корректно из большинства объявлений), но встречаются предложения именно для молодежи, студентов или наоборот от 25–30 лет. Один раз встретилось предложение для «семьи средних лет».
По количеству ожидаемо охотнее сдают одному-трем людям, но есть и экзотичные варианты для пяти-шести человек (некоторые арендодатели пишут, что готовы принять бригаду строителей или компанию командировочных посуточно).
С детьми чаще можно (433), чем нельзя (270), но лучше — с детьми от 5–6 лет, школьного возраста. Здесь модели было сложно уловить тонкости: авторы объявлений часто пишут, что «нельзя с маленькими детьми» или что можно семье, но не указано, есть ли конкретные требования к детям. Не будем сильно ругать модель: некоторые вещи часто описаны в объявлениях неоднозначно, и их приходится уточнять в чате или по телефону.
Снять квартиру с животными — отдельный квест: гораздо чаще пишут, что с животными нельзя (430 раз), о том, что можно, писали 89 раз. Вопреки нашим ожиданиям, модель не извлекала подробностей о том, с какими именно животными можно (например, можно ли с хомяком или маленьким попугаем, или вообще ни с кем нельзя?). Видимо, это нужно было эксплицитно указать в промпте, чего мы не сделали. Зато модель несколько раз выделила указания на то, что животные только «под залог», «по договоренности» или, что животных можно «немного».
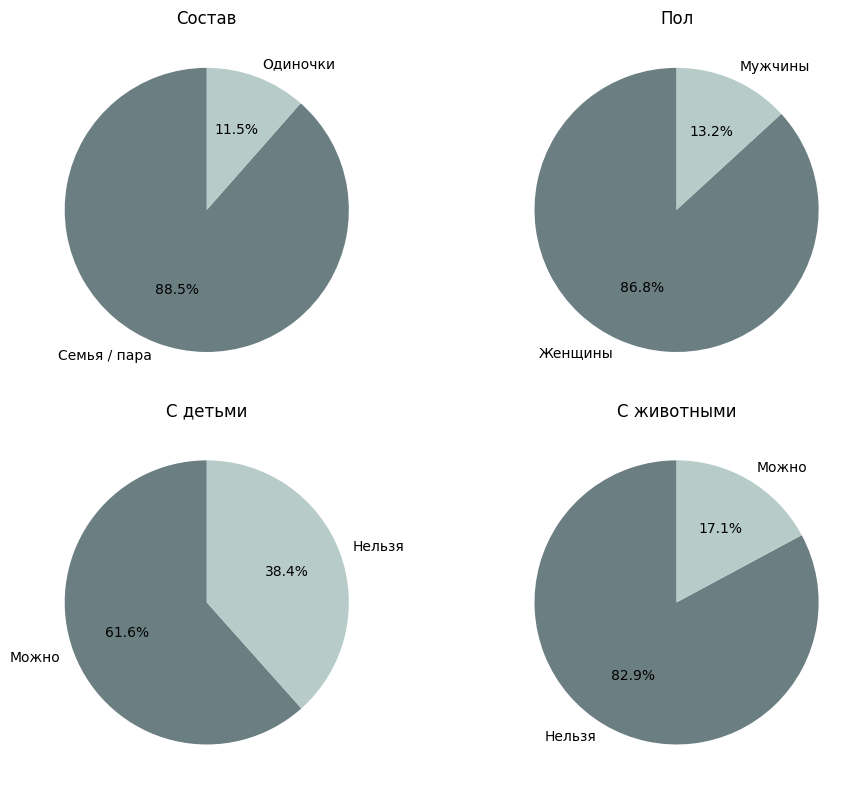
Можно заметить, что мужчинам-одиночкам, людям с маленькими детьми и животными сложнее снять квартиру, чем семейным парам (видимо, штамп в паспорте тоже играет роль) и женщинам без детей и животных.
Что мы узнали из 15 тысяч объявлений?
Итак, используя большую языковую модель, мы извлекли требования к жильцам из почти 15 тысяч объявлений об аренде квартир. Судя по значениям точности и полноты, наше исследование скорее позволило узнать «как бывает» и увидеть много разнообразных примеров, а не сделать надежные выводы о генеральной совокупности объявлений или извлечь все возможное. Наиболее точные и полные результаты получились по параметру «Национальность», а наиболее разнообразные — по «Качествам характера и привычкам».
Полученные результаты интересны как с лингвистической, так и с социологической точки зрения, а метод, если его доработать, применим для извлечения любой неструктурированной информации из текстов.
Автор благодарит Марию Тихонову за консультации и поддержку во время работы над исследованием.
Источники
- Saitov L. Cianparser [Computer Software] // GitHub. URL: https://github.com/lenarsaitov/cianparser/tree/main.
- Avito Demand Prediction Challenge // Kaggle. URL: https://www.kaggle.com/competitions/avito-demand-prediction.
- Google Colaboratory. URL: https://colab.google/.
- Qwen2.5-3B-Instruct-GGUF // Hugging Face. URL: https://huggingface.co/Qwen/Qwen2.5-3B-Instruct-GGUF.
- Палкина Е. В России запретили объявления о сдаче жилья «только славянам» // Snob.ru. 2025. URL: https://snob.ru/news/v-rossii-zapretili-obiavleniia-o-sdache-zhilia-tolko-slavianam/.
- Парсинг веб-сайтов: взгляд изнутри // Habr. 2024. URL: https://habr.com/ru/articles/803869/.
- Как написать хороший промпт // Системный Блокъ. URL: https://sysblok.ru/ai/prompting/
- Ким М. 10 слов машинного обучения // Системный Блокъ. 2024. URL: https://sysblok.ru/nlp/10-slov-mashinnogo-obuchenija/.
- Ким М. Что такое регулярные выражения // Системный Блокъ. 2024. URL: https://sysblok.ru/glossary/chto-takoe-reguljarnye-vyrazhenija/.

